
Python in Excelを試す

何やらExcelでPythonを動かせるようになったということで、早速試してみました。ちょっと癖はありましたが、可能性は広がるのではないかな?という印象です。
Python in Excelとは?
Excel上でPythonコードを動かせる仕組みです。まずは動作例を一つ。
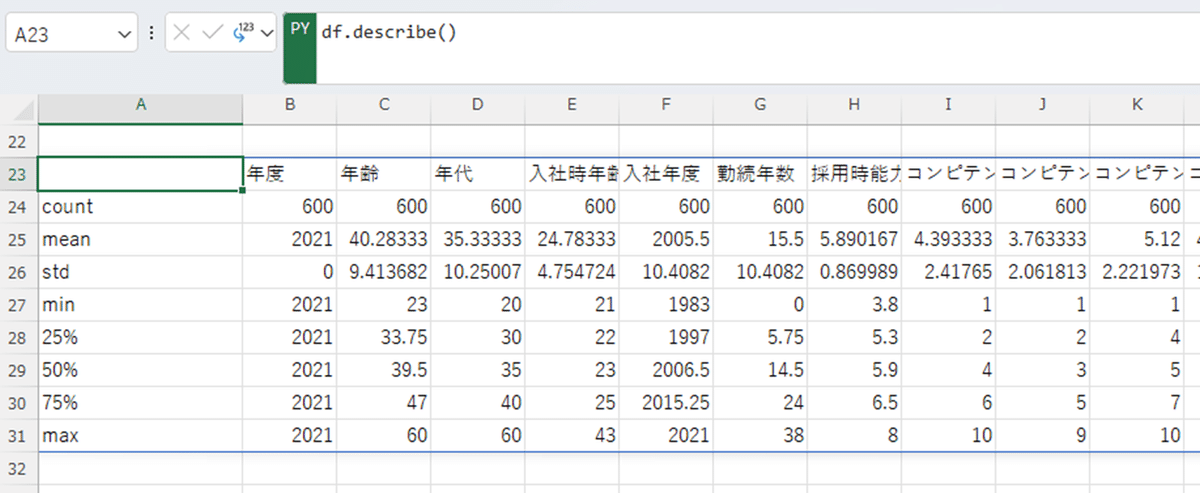
以下の画面は、Excelシートにあるデータの基本統計量を表示したものです。一旦pandasのデータフレーム'df'に取り込んでからdescribe()を実行しました。結果をセルに展開できるのが面白いところですね。
現時点ではまだプレビューの段階なので、利用するにはベーターチャネルを有効にしなくてはなりません。詳しくはマイクロソフトのページをご覧ください。
基本的な使い方
セルに '=py(' と入力するとPythonコードを実行するモードになります。
例えば以下のような感じでB5セルに '=py(' と入力すると、セルや数式バーにPYという文字列が表れて、コードを受け付けるようになります。
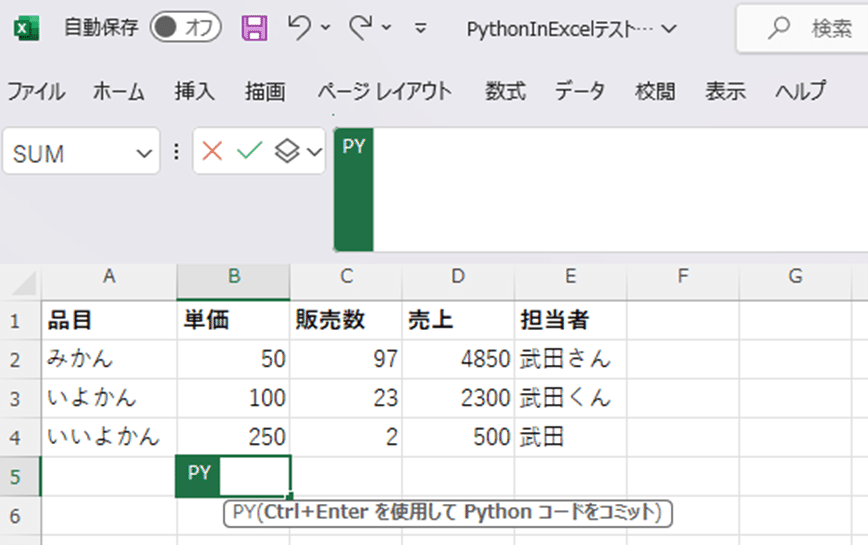
そして、セルもしくは数式バーにコードを書いた上で、Ctrl+Enterを押すとコードが実行されます。Jupyter notebookの操作感に若干似ています。
初期状態だと、実行結果はオブジェクトとして出力されます。数式バーの左隣りにあるアイコンをクリックしてPythonの出力を「Excelの値」にしてから実行すると、結果をセルに出力することができます。

Pythonコードを入力している最中にマウスでセルを選択すると、xl( )という関数が補間されます。xl( )の戻り値はpandasのデータフレームのようでした。

単一の列を選択してもSeriesのメソッドを使えなかったのですが、iloc()で取り出してあげると以下のように上手くいきました。

基本的な使い方はこんな感じです。xl( )でセルを選択するとpandasのデータフレームになるようなので、それなら初めからデータフレームを作ってしまった方が早そうだなとも思いました。
以下、データをpandasのデータフレームに取り込んだ上で、いろいろ試した結果を書いていきます。
データフレームに取り込んでアレコレしてみる
今回も自作の人事トイデータを使いました。利用したデータは以下のサイトで配布しているデータの「拡張版」の方になります。なお、こちらのデータはニュースレター「人事データ分析入門講座」で利用しているデータになります。
データの読み込み
まずはデータをExcelに取り込みます。CSVファイルなのでファイルをダブルクリックしても開くのですが、文字コードの変換がうまくいかない場合があります。そのため、CSVデータを読み込むときにはなるべくExcelのデータ読み込み機能を使いましょう。ここまではいつものExcelと同じですね。

読み込んだデータはシートで見ることができます。今回は600件のデータです。
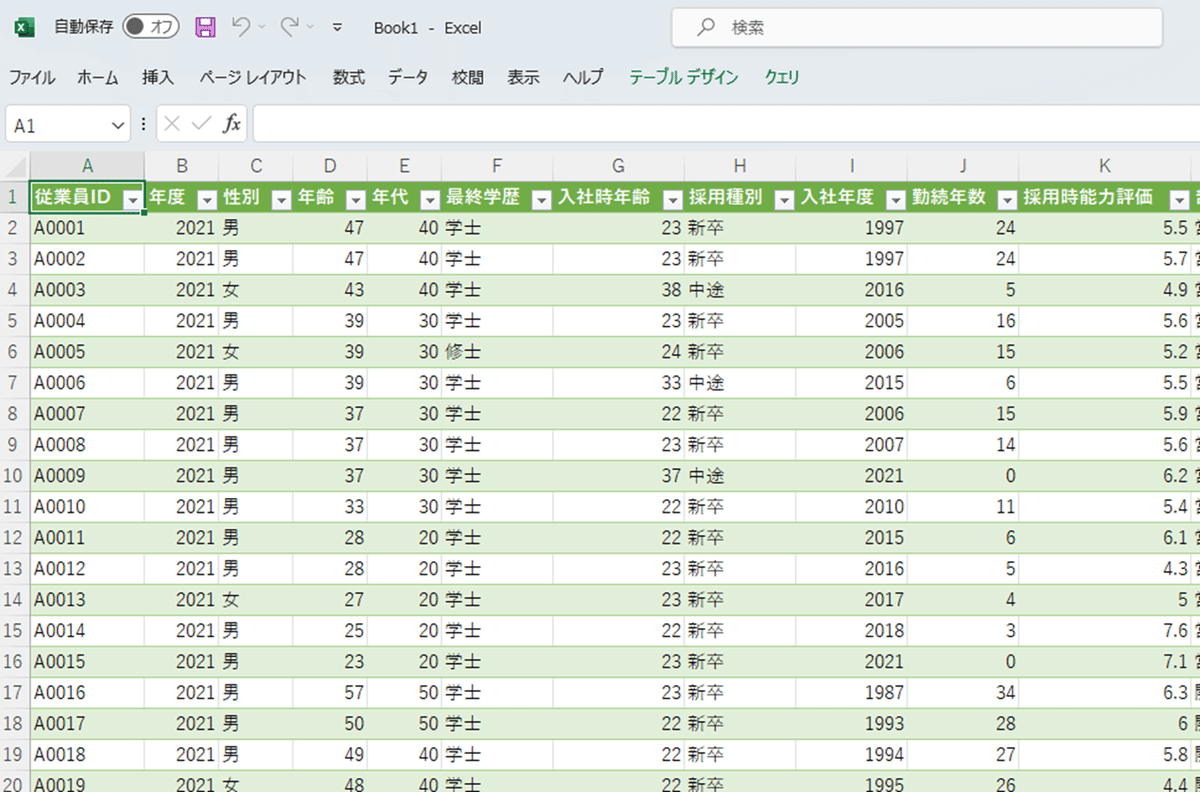
pandasのデータフレームに取り込む
データを取り込んだシートはキレイに置いておきたいので、コード用に新しいシートを準備しました。そして、A1のセルに'=py('と入力してpythonモードにして、データフレームに取り込みました。
以下は、データフレームをdfというオブジェクトに格納した後、arrayPreviewを実行している様子です。セルに中身を表示していますが、省略されていますね。

サンプルを確認
データフレームに取り込んだら中身を見たくなるものです。とりあえずランダムに一件取ってくるsample()で見てみました。ここで注意が必要な点として、すべての列を見たい場合は、出力を「Excelの値」にして実行する必要があるということです。

基本統計量の出力・カテゴリ件数のカウント
データフレームに取り込んでいるので、pandasの機能がそのまま使えます。冒頭にも紹介しましたが、describe()で基本統計量を出すこともできます。

また、カテゴリデータについてはおなじみvalue_counts()でカテゴリ別の件数を数えることができます。

セルに出力された値はいつものExcel機能で利用することができます。入力規則で簡易の棒グラフをつくったり、円グラフを描いたり。

クロス集計
クロス集計をすることも可能です。Excelでもピボットテーブルを使えば同じことができるわけですが、簡素なコード1行で実現できるのがいいですね。出力結果をオブジェクトに保存しておけば、後で再利用もできますし。

このような形で、pandasでできることはいろいろできるなという感じでした。
Seabornでグラフを描く
常用しているseabornも使えるということで、早速試してみました。まずは散布図から。seabornをインポートしなくても使えました。一般的に使われる略称でimportされている感じでしょうかね。

残念ながら日本語表示ができない感じですね。俗にいう豆腐問題。試しに豆腐問題の救世主である japanaize_matplotlibをimportしてみたのですが、モジュールエラーとなってしまいました。正式版ではぜひ対応してほしいところです。
散布図+曲線
豆腐問題に目をつむると、Excelでは描けないようなグラフを作れるのは魅力です。例えば、seabornなので散布図にLowessをフィットさせるのも簡単です。

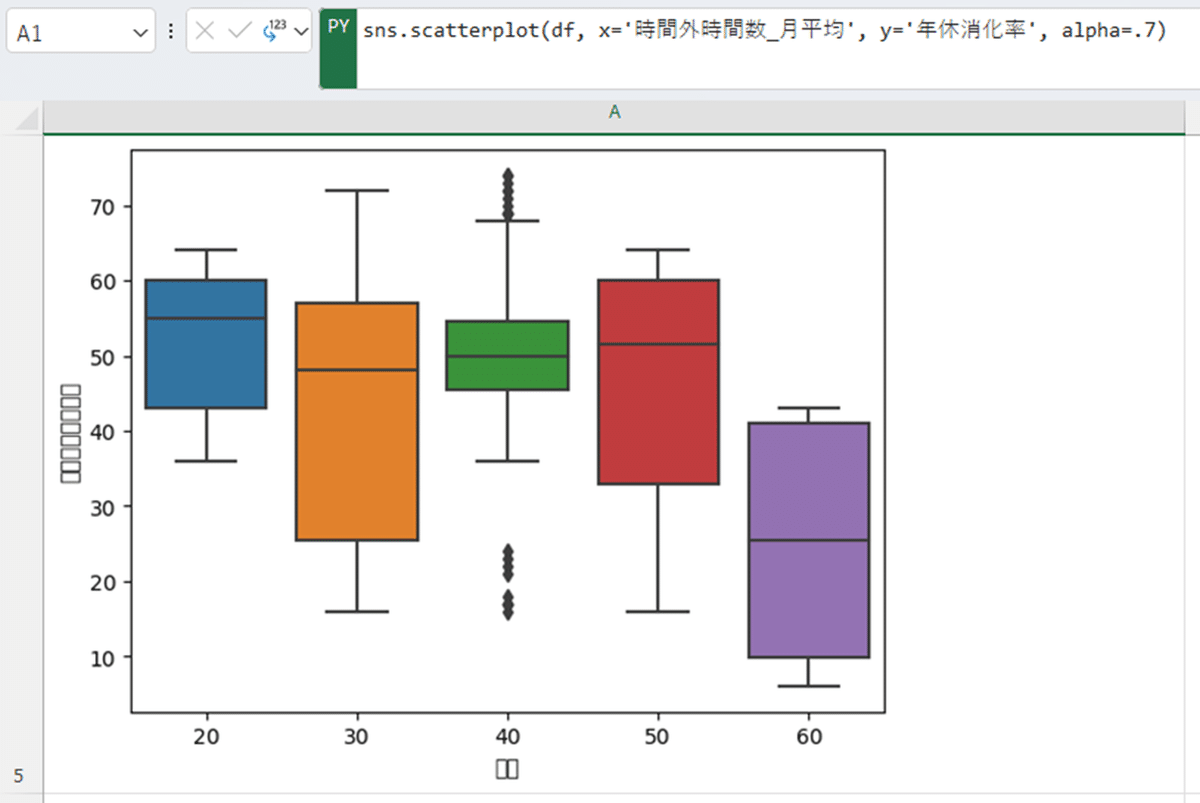
グループ別に箱ひげ図を並べる
最近はExcelでも箱ひげ図を描けますが、グループ同士で比較するのは中々大変です。できなくはないのですが、グループ毎にデータ列を準備するのが何とも大変で…。seabornならグループ化したい列を選択すればよいので楽ですね。
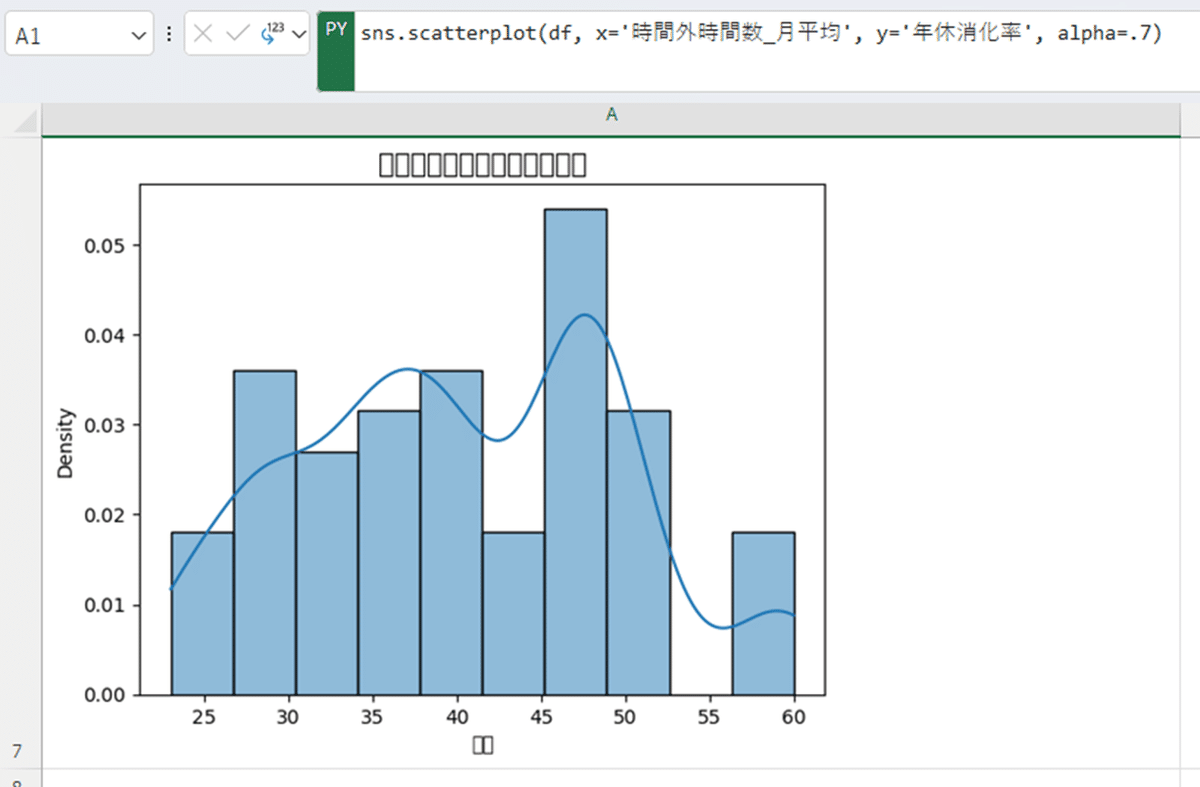
ヒストグラム+KDE
ヒストグラムにKDE(カーネル密度推定)の結果を重ねたもの。最近よく使うグラフの一つです。豆腐問題さえなければなぁ…。
多変量解析を試す
ここまででも十分だと思いますが、多変量解析もやってみることにしました。あくまで動作確認のレベルです。
主成分分析(PCA)
根強い人気の主成分分析。次元圧縮、直交化、データ俯瞰など様々な用途で使われています。モジュールをimportすればいつも通り動きました。sklearnのモジュールが動くということなので、いろいろできそうですね。実用レベルになれば助かる方も多いでしょう。

重回帰(一般化線形モデル)
重回帰も動きました。sklearnでなくstatsmodelsの一般化線形モデルの方でやってみたのですが、上手く動くようです。これは広がりますね。どうせならRも動けばいいのに…。
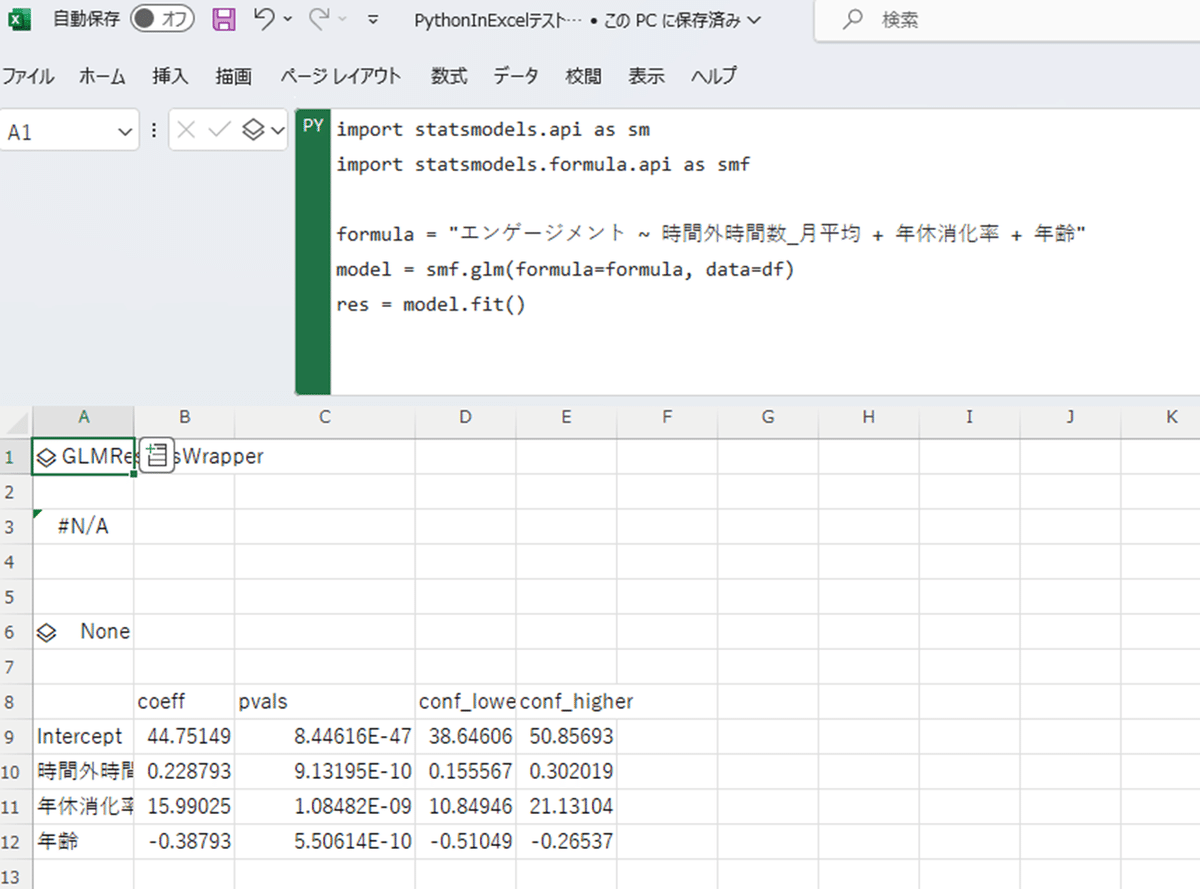
ただ、回帰の結果を格納したオブジェクトをセルにそのまま展開しようとしてもできませんでした(A3セル)。上の例では、A6セルで適当に取り出す関数を作って処理しています。
今後の期待
一通り触ってみて、思ったよりも使えそうだなと感じました。正式版では以下の点が改善されているとうれしいですね。
seabornの日本語表示問題(豆腐問題の解消)
セルを更新するたびに、すべてのPythonコードが再実行されてしまう
マニュアルがあまりない
コード入力の補完機能がない
一方、機能を活かすにはpandasを上手く使いこなせる必要があるようにも感じました。なので、現時点では、Python/pandasを普段から利用したことがある方が、Excelで対応する必要に迫られたときに便利なのかなと思っています。最近は高校の情報科目でPythonを習うそうですし、広がるかもしれません。
また、Pythonコードはマイクロソフトのサーバー上で実行されているようです。そのあたりがどうなるかによっても今後の使い勝手が変わってくるでしょう。