
よくわかるGoogle Cloud#4_PlaywrightをCloud Runで動かす

皆様こんにちは。
カホエンタープライズのnoteをご覧いただきありがとうございます!
本日は、Google Cloudの活用方法をお伝えするシリーズの第4弾をお届けします!
今回使うツールのご紹介
まずは、今回使用するツールを2つご紹介します。
1つ目は「Playwright」です。Playwrightは、Microsoft社が中心となって開発している、Webスクレイピングやブラウザテスト用のオープンソースライブラリです。これを使うことで、Webページの表示やクリック、入力等、ブラウザ上で行う操作を自動化することができます。PythonやNode.jsなどで利用可能となっています。
2つ目は「Cloud Run」です。Cloud Runは、Google Cloud Platform(GCP)で提供されるシステムで、コンテナ化(プログラムやその実行に必要なライブラリや設定などをすべて1つのパッケージにまとめる技術)という技術を使って、サーバーを自分で管理することなくアプリケーションを実行できるツールです。Google Cloud側でサーバーを管理してくれるだけでなく、アプリへのアクセス数に応じてリソースが自動調整されるようになっています。
今回は、
・Playwrightを使用してWebスクレイピングを行う
・その結果をBigQueryに格納するプログラムをCloud Runにデプロイ
・スケジュール実行を設定
以上の流れを試してみたいと思います。
Playwrightを触ってみる
まずはPlaywrightがどんなものなのか簡単に触ってみます。
インストール
pythonがインストールされているPCで以下を実行します。
pip install playwright pytest-playwright
playwright installcodegenを使ってみる
playwrightにはブラウザ操作しながらコードを自動生成してくれるcodegenという機能があるようです。
(windowsであればコマンドラインで)以下を実行します。
playwright codegen以下のような感じでブラウザとコードの画面が立ち上がってきて、ブラウザ操作するたびにコードの画面が更新されます。

Cloud Runで実行する
ここから先のコマンドはCloudShellで実行する想定です。(必要な権限は持っている前提となります。)
Artifact Registryを作成する
Artifact RegistryでDockerイメージをアップするためのリポジトリを作成します。Artifact Registry画面のリポジトリを作成をクリックします。
リポジトリの名前(ここではplaywrightにします)やリージョンを選択し作成をクリックします。

実行用のpythonファイルを作成する
Cloud Run用のpythonファイルを作成します。
今回はplaywrightのwebページで取得した情報をBigQueryにアップさせるサンプルを作ります。
python:main.py
from playwright.sync_api import sync_playwright
from flask import Flask
import os
import pandas as pd
import pandas_gbq
#BigQueryの情報
project_id = '<project_id>'
table_id = '<dataset>.<table>'
app = Flask(__name__)
@app.route("/")
def exec_playwright():
# playwrightの実装
try:
with sync_playwright() as p:
df_dict = {}
# Chromium (Web Browser)のインスタンスを作成する
browser = p.chromium.launch(headless=True)
# 新しいページを作成する
page = browser.new_page()
print('page: ', page)
# page.goto() で Playwright のサイトにアクセス
page.goto('https://playwright.dev/')
# title tag の値(ページタイトル)を取得し辞書に格納
title = page.title()
df_dict['page_title'] = [title]
# hero__titleクラスのテキストを取得し辞書に格納
hero_title_text = page.locator('.hero__title').text_content()
df_dict['hero_title_text'] = [hero_title_text]
# Browser を閉じる
browser.close()
# upload to bigquery 辞書データを渡してBQにアップロードさせる
upload_to_bigquery(df_dict)
return f"OK!"
except Exception as e:
return str(e)
def upload_to_bigquery(df_dict):
df = pd.DataFrame.from_dict(df_dict)
pandas_gbq.to_gbq(df, table_id, project_id=project_id, if_exists='replace')
if __name__ == "__main__":
app.run(debug=True, host="0.0.0.0", port=int(os.environ.get("PORT", 8080)))requirements.txt
playwright==1.41.1
pytest-xdist==3.5.0
Flask==3.0.1
pandas==2.2.0
pandas_gbq==0.20.0Dockerfileの作成
dockerfile:Dockerfile
FROM mcr.microsoft.com/playwright/python:v1.41.0-jammy
ADD main.py .
ADD requirements.txt .
RUN pip install --upgrade pipRUN pip
install --upgrade setuptools
RUN pip install -r requirements.txt
CMD ["python", "main.py"]Docker imageの作成とPush
Dockerfileとpythonのスクリプトは同じディレクトリにある前提で以下を実行します。
shell:dockerイメージの作成
docker build -t <location>-
docker.pkg.dev/<project_id>/playwright/playwright:latest .shell:dockerイメージをArtifact RegistryにPush
docker push <location>-
docker.pkg.dev/<project_id>/playwright/playwright:latest Cloud Runにデプロイ
未認証は許可せず、メモリは1GBにしてplaywright-serviceという名前でデプロイします。
shell:cloud runにデプロイ
gcloud run deploy playwright-service --project <project_id> --memory=1Gi -
-no-allow-unauthenticated --image <location>-
docker.pkg.dev/<project_id>/playwright/playwright:latest --platform
managed --region <region>実行結果
cloudshellから以下コマンドでデプロイしたCloudRunを実行して結果を確認してみます。
curl -H \
"Authorization: Bearer $(gcloud auth print-identity-token)" \
<CloudRun_URL>BigQueryにスクレイピングした結果が格納されました。

スケジューリング
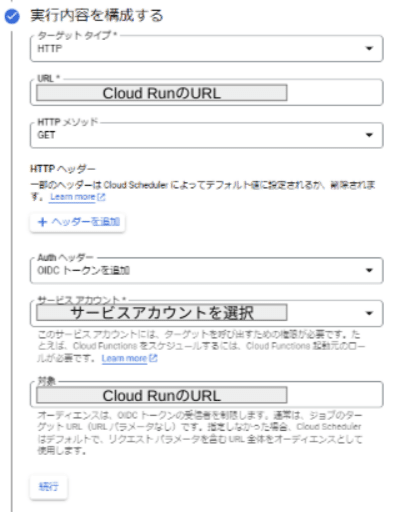
CloudScheduler
CloudScheduelerでスケジューリングする際には以下に注意します。
- メソッドはGET(今回のサンプルプログラムの場合)
- AuthヘッダーにOIDCトークンを追加(認証情報)
Workflows
Workflowsで実行させる場合は、以下のようにhttp get(今回のサンプルプログラムの場合)を対象のURLに対してキックさせます。このときauthのOIDC設定を入れないと認証エラーになるので注意してください。
yaml
call: http.get
args:
url: <Cloud RunのURL>
auth:
type: OIDC
result: returnValueデプロイ前にローカル(Cloud Shell)でテストするとき
以下コマンドを実行するとポート9090にアクセスしてローカルでの実行確認ができます。
shell
PORT=8080 && docker run -p 9090:${PORT} -e PORT=${PORT} <location>-
docker.pkg.dev/<project_id>/playwright/playwright:latest 上記コマンド実行後、Cloud shellの右上のプレビューボタン→ポートを変更で9090にしてアクセスするとテスト実行されます。

今回の記事では、Playwrightを使用してWebスクレイピングの結果をBigQueryに格納し、Cloud Runにデプロイしてスケジュール実行まで設定する方法について解説しました。Playwrightの機能と、Google Cloudのサービスを組み合わせることで、サーバレスな環境でブラウザ自動化からデータ収集、そしてデータの定期的な処理までを一貫して行える環境を構築できます。ぜひ試してみてください。
カホエンタープライズについて
当社はホームセンター「グッデイ」におけるDX化の経験をもとに、様々な企業のDX化を支援しております。
Tableauを用いたデータ活用に関する支援はもちろん、実務に直結するデータ活用スキル習得を目指したDX人材の育成支援等、様々なサービスメニューを用意しております。
データ活用・管理に関してお困り等ございましたら、是非お気軽にご相談ください!
カホエンタープライズにできること
① データ活用に関する支援
・ Tableauライセンス販売
・ Tableauダッシュボード画面構築支援
・ データ分析基盤(DWH)構築・運用支援
・ Tableau操作トレーニング
・ Tableau内製化支援(伴走支援)
② Google Workspace活用支援
・ Google Workspaceライセンス販売
・ Google Workspace導入・活用支援
・ Google Workspace操作トレーニング
③ KOX
・データ活用プラットフォーム「KOX」の提供
④ DX人材育成支援
・DX人材育成プログラム「Data Academy」の提供
<問い合わせ先>
株式会社カホエンタープライズ
担当者:湯野 礼之輔(ゆの れいのすけ)
Mail:sales@kaho-enterprise.co.jp
TEL:070-8814-5939