
自動でプロンプトエンジニアリングする『APE(Automatic Prompt Engineering)』を試す。LangGraph

こんばんは、IZAIエンジニアリングチームです。今回は、自動プロンプトエンジニア(APE)についての論文のアイディアをもとに、遺伝的アルゴリズムチックにプロンプトを自動で調整する方法を試してみました。
APE(Automatic Prompt Engineering)とは
APEはAutomatic Prompt Engineeringの略で、その名の通り自動でプロンプトエンジニアリングを行うアルゴリズムです。与えられたタスクをもとにオリジナルのプロンプトと意味的に近しいプロンプトをいくつか生み出し、それらを評価する、ということを繰り返します。
実装方法
今回はLangChainの派生ライブラリであるLangGraphを用いて実装します。LangGraphを用いることでループ処理や条件分岐の実装をより簡単に行うことができます。
使用するライブラリ
pip install httpx
pip install langgraph
pip install langchain_openai
pip install pandas
pip install numpyfrom typing_extensions import TypedDict, Optional
from langgraph.graph import StateGraph
from langchain_openai import ChatOpenAI
from langchain_community.embeddings.openai import OpenAIEmbeddings
from langchain_core.pydantic_v1 import BaseModel, Field
import pandas as pd
import numpy as np
from IPython.display import Image, display今回はOpenAIのGPT3.5-turboとOpenAI Embeddingを使うのであらかじめ環境変数にOPENAI_API_KEYを登録しておきます。
使用するデータセット
今回使用するデータセットはHugging Face上に公開されているライブドアニュースの三行要約データセットです。
このデータセットはLlama2をファインチューニングするためのタグなどが追加されているので、今回は使う部分だけをまとめたデータセットを作っておきました。
入力例
あなたは誠実で優秀な日本人のアシスタントです。
以下の入力文を3行で要約しなさい。
入力文: タイやホタテ、焼きあごなど、多彩な魚介類がダシに使われるようになり、それぞれの店の個性を生み出している。未知の味との出会いを楽しもう。ぴあMOOK『究極のラーメン2016 ハンディ版』から、選りすぐりの名店をご紹介!OPEN 2015年5月24日種類麺スープ具決め手の特製オイル厳選食材の旨みを活かした贅沢スープOTHER MENU完全禁煙03-5350-8177OPEN 2015年2月20日種類麺スープ具決め手の焼きあご焼きあごのダシが上品な塩ラーメンOTHER MENU完全禁煙03-6457-3328OPEN 2015年2月23日種類麺スープ具決め手のホタテスープに凝縮された肉・野菜・魚介の旨み完全禁煙03-3910-4005OPEN 2015年2月12日種類麺スープ具決め手の乾き物エビの旨みが抽出されたポタージュ系ラーメン完全禁煙03-3834-3271OPEN 2014年11月1日種類麺スープ具決め手のアサリ鶏や魚介、野菜などダシにこだわりあり部分禁煙電話非公開OPEN 2015年3月1日種類麺スープ具決め手の地元食材ご当地食材たっぷりのこだわりあふれる一杯完全禁煙047-333-5556※掲載情報は、2015年10月〜12月上旬の取材時のものです。掲載後にやむを得ない事情により掲載内容が変更となる場合もあります。あらかじめご了承ください。続々と新しいお店が登場し、進化が止まらないラーメン店。※本誌は2015年9月に発行したぴあMOOK『ぴあラーメン本2016 首都圏版』の内容を再編集し、最新情報に更新したものです。
出力例
3行要約: 絶品スープが味わえる注目のラーメン店を紹介している RAMEN TOMIRAIの「豚骨魚介特製らあめん」は奥行きのあるスープが自慢 たかはしの「焼きあご塩らー麺」はトビウオのダシが上品な塩ラーメンである
df = pd.read_csv("small_dataset.csv")LangGraphで実装する
まずは使用するモデルの設定から行います。プロンプトを生成する用のモデルはtemperatureを1.0と高めに設定することで、試行するプロンプトのバリエーションを高めます。
class PromptGeneratorResponseType(BaseModel):
prompts: list[str] = Field(description="新しいプロンプトのリスト")
llm = ChatOpenAI(model="gpt-3.5-turbo")
prompt_generator = ChatOpenAI(model="gpt-3.5-turbo", temperature=1.0).with_structured_output(PromptGeneratorResponseType)
embeddings = OpenAIEmbeddings()次にグラフのStateを設定します。LangGraphにおけるStateは、各ノードの引数となる辞書型のクラスです。
class State(TypedDict):
prompt: list[str] # 生成されたプロンプトのリスト
response: Optional[list[str]] = None # それぞれのプロンプトによって生成された回答のリスト
true_answer: Optional[str] = None # 本来の回答
question: Optional[str] = None # LLMに入力される文章
iteration: int = 0 # 何回目の生成か
graph_builder = StateGraph(State)ノードの設定に入る前に評価関数を考えましょう。ここでの評価関数とは複数のプロンプトによって生成された文章と、本来の回答を比較し、点数をつける関数のことです。
今回のタスクは文章要約なので、
文章同士のコサイン類似度 + 出力文章の長さの比*
をスコアとして計算します。[-1, 2]
出力文章の長さの比*・・・
簡易的な評価手法。出力した要約文と正解文の長さの近さを0から1の値で表します。完全に同じ長さなら1、長さの差が大きいほど0に近づきます。
他にもBLEU、ROGUEなどのスコアリングも有効です。
def evaluate(State):
embeddings_list = np.array(embeddings.embed_documents(State["response"]))
target_embedding = np.array(embeddings.embed_query(State["true_answer"]))
# コサイン類似度の計算
similarity = np.dot(embeddings_list, target_embedding.T) / (np.linalg.norm(embeddings_list, axis=1) * np.linalg.norm(target_embedding))
# 文章の長さの比を計算
target_length = len(State["true_answer"])
length_error = map(lambda x: min(len(x), target_length) / max(len(x), target_length), State["response"])
# 最終的なスコアを計算
score = similarity + np.array(list(length_error))
max_idx = int(np.argmax(score))
print("best prompt:", State["prompt"][max_idx], "score:", score[max_idx], "index:", max_idx)
return {"prompt": State["prompt"][max_idx]}次に新しいプロンプトを生成するノード、それらのプロンプトを実行するノード、そして結果表示用のノードを作成していきます。
def generate_prompt(State):
generator_prompt = """
あなたはプロンプトエンジニアです。
入力されたプロンプトをもとに、言い換えや語順を変える、新しい情報を追加するなどの操作を加えて同じ意味を持つ新しいプロンプトを生成してください。
以前のプロンプト: '''{prompt}'''
新しいプロンプトを全部で5つ生成してください。
"""
new_prompt = prompt_generator.invoke(generator_prompt.format(prompt=State["prompt"])).prompts
new_prompt.append(State["prompt"])
return {"prompt": new_prompt, "iteration": State["itreration"] - 1}
def generate_answer(State):
rows = df.sample(n=1)
question = rows["text"].item()
answer = rows["summary"].item()
prompts = State["prompt"]
print("question:", question)
responses = []
for prompt in prompts:
responses.append(llm.invoke(prompt + f"\n{question}").content)
print("prompts:", prompts)
print("responses:", responses)
print("true answer:", answer)
return {"response": responses, "true_answer": answer, "question": question}
def summary(State):
summary_statement = """
調整されたプロンプト:
{prompt}
"""
print(summary_statement.format(prompt=State["prompt"]))
return Stateではグラフを構築しましょう。繰り返し回数は5としておきます。
graph_builder = StateGraph(State)
graph_builder.add_node("generate answer", generate_answer)
graph_builder.add_node("evaluate", evaluate)
graph_builder.add_node("generate prompt", generate_prompt)
graph_builder.add_node("summary", summary)
graph_builder.add_edge("generate answer", "evaluate")
graph_builder.add_edge("generate prompt", "generate answer")
graph_builder.add_conditional_edges("evaluate", lambda state: "summary" if (state["iteration"] == MAXIMUM_ITERATION) else "generate prompt", {"summary": "summary", "generate prompt": "generate prompt"})
#graph_builder.add_edge("evaluate", lambda state: "summary" if (state["iteration"] == 0) else "generate prompt")
graph_builder.set_entry_point("generate answer")
graph_builder.set_finish_point("summary")
graph = graph_builder.compile()完成したグラフを表示してみましょう。
display(Image(graph.get_graph().draw_mermaid_png()))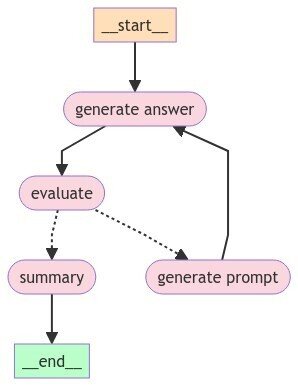
試してみる
では実際に実行してみましょう。繰り返し回数は5です。
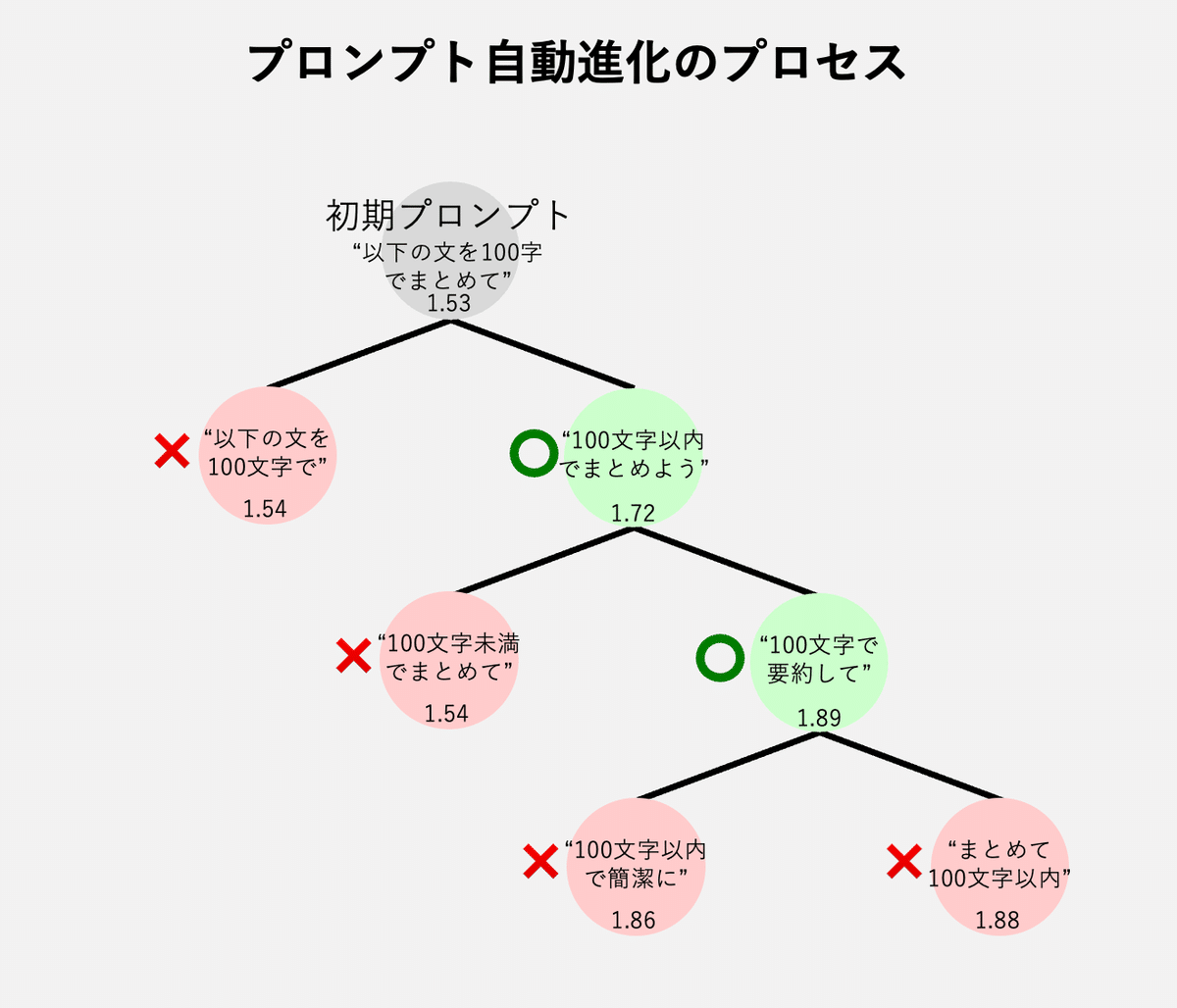
graph.invoke({"prompt": ["以下の文を100字でまとめて"], "iteration": 5})出力結果とスコアを比較してみると、
以下の文を100字でまとめて: 1.535763893167752
以下の文章を100文字以内でまとめよう。: 1.7255995484118527
100文字未満でまとめてください。: 1.8353215729331582
100文字以内で以下の文章を要約してください。: 1.8857869283793893
文章を100文字以内で簡潔にまとめてください。: 1.8556173336068014と、たしかにスコアが上昇し、プロンプトも洗練されていることが確認できます。
それぞれの段階で他に生成されたプロンプトの一部も確認してみると、
"以下の文章を100文字以内でまとめよう。" と同時に生成されたプロンプト
- 100文字で以下のテキストをまとめよう。
- この文章を100字でまとめる。
- 100字のまとめを書こう。
"100文字未満でまとめてください。" と同時に生成されたプロンプト
- まとめてください。
"100文字以内で以下の文章を要約してください。" と同時に生成されたプロンプト
- 以下の文章を100文字以下に簡潔にまとめてください。
- まとめてください:以下の文章を100文字以内に。
- 要約:以下の文章を100文字以内にしてください。
"文章を100文字以内で簡潔にまとめてください。" と同時に生成されたプロンプト
- 以下の文章を100文字以内で要約してください。
- 下記文章を短くまとめてください。と様々なバリエーションのプロンプトが生成されていることがわかります。
考察
今回使用したプロンプトは日本語の短い文章でしたが、GPT-3.5-turboでは文法が崩壊したプロンプトを生成することがありました。英語プロンプトや高性能なLLMを使うことで、良い結果を得ることができそうです。
評価関数についても、今回は評価サンプル数が1でしたが、より多くのサンプルの平均点を計算することでより安定した結果が得られるでしょう。
今回は終了条件が既定の回数ループすることでしたが、終了条件を変更することで既定のスコアを上回った場合に終了する、といった条件に変更することも可能です。色々試してみても面白いですね。
新しいプロンプトの生成について、今回は単純に似た意味の文章を生成しましたが、生成された文章と正解文章を比較し不足部分を補うようにプロンプトを修正すると、より早く良いプロンプトへ収束する可能性が高いです。
最後に
APEを活用すると、膨大な量のプロンプトを自動で試し、自動で評価することができます。人間には時間的・発想的に到達不可能なプロンプトを作成できるので、正解データセットが用意出来る領域においては、今後のプロンプトエンジニアリングの主流になりそうです。
以上、参考になった方はいいね、コメントをいただけると今後の開発の励みになります。それではまた!
この記事が気に入ったらサポートをしてみませんか?