
Stable Diffusionのimg2img機能で画像の人物を色々な表情に変化させてみた

画像生成AIのStable Diffusion(以下SDと言います。)には、文章から画像を生成する機能以外に画像から新しい画像を生成するimg2img機能があります。今回は、このimg2imgを試してみることにしました。
1.img2imgの無料デモページ
AI関連コミュニティサイトのHugging Faceに、このSDのimg2imgを無料で試せるデモページのDiffuse The Restが公開されたので試してみました。以下がそのデモページです。
デモページの中央に以下のような絵を描くためのスペースがありますので、そこにマウスで適当に絵を描きます。

実際に筆者が描いてみたのが次の絵です。

そして、プロンプトの入力欄に生成したい画像の指示(呪文)を入力して青いボタンをクリックします。ちなみに今回は、「A realistic photo of a brave man fighting with a sword」と入力しました。すると、数枚の画風の違う画像が生成されます。その1枚が次の画像です。

どうでしょうか。少し顔や体の向きが違いますが、構図はそっくりです。
2.自宅パソコンへのimg2imgの導入
もっと色々とimg2imgを試してみたいので、今回も、前回と同様にGoogleが提供しているPython実行環境のColaboratoryを利用して、Hugging Faceで公開されているSDのimg2imgのコードをインストールすることにしました。
(1) インストール前の準備
最初に、Colaboratoryを使用できるように準備する必要があります。前回、SDをインストールする際にこの準備作業を完了していれば、このプロセスは省略できます。
最初に、Hugging FaceのSD(v1-4)のページにアクセスしてライセンスを確認します。
次に表示されるHugging Faceのサイトにログインして、アクセストークンを取得します。
Colaboratoryのサイトにログインし、ノートブックを設定して、GPUを選択します。これで、SDを導入する準備が整いました。
なお、実際の操作の際の画面などは、以下のサイトを参考にしてください。
(2) Colaboratoryへのimg2imgのインストール
それでは、実際にColaboratoryのノートブックにコマンドを入力していきます。なお、Colaboratoryにimg2imgをインストールする方法については、以下のサイトを参考にしました。
〇 GitHubのリポジトリから最新のDiffusers(拡散モデル専用のライブラリ)をインストールします。
!pip install transformers scipy ftfy
!pip install git+https://github.com/huggingface/diffusers.git〇 インストール前の準備作業で取得したHugging Faceのアクセストークンを設定します。
YOUR_TOKEN="アクセストークンの文字列"〇 SDのimg2imgのパイプラインを使用して、img2imgの実行に必要な全てのファイルをダウンロードします。
import torch
from diffusers import StableDiffusionImg2ImgPipeline
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=YOUR_TOKEN
).to("cuda")これで、img2imgを使う準備ができました。
(3) img2imgでの画像生成
最初に、入力する画像をColaboratoryにアップロードします。ノートブックの画面左側のフォルダ内のcontentフォルダ(現在の作業フォルダ)を右クリックし、ドロップダウンリストから「アップロード」を選択して、入力画像のファイル名をinput.pngに変更してアップロードしてください。
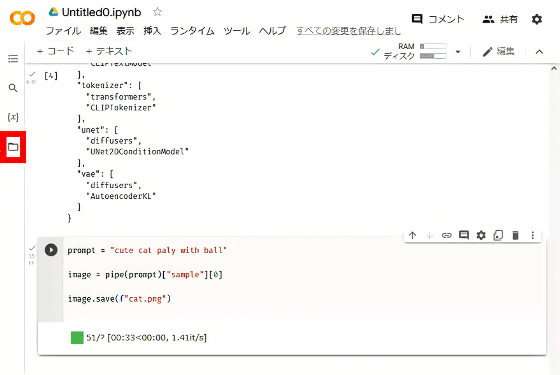
次に、以下のコマンドを入力して、新しい画像を生成します。
from PIL import Image
from torch import autocast
prompt = "画像の変更方針の指示(呪文)"
init_image = Image.open("input.png").convert("RGB")
init_image = init_image.resize((512, 512))
with autocast("cuda"):
images = pipe(
prompt=prompt,
init_image=init_image,
strength=0.75, # 入力画像と出力画像と相違度 (0.0〜1.0)
guidance_scale=7.5, # プロンプトと出力画像の類似度 (0〜20)
num_inference_steps=50, # 画像生成に費やすステップ数
generator=None,
)["sample"]
images[0].save("出力画像のファイル名.png") 画像1枚生成するのに約10秒かかります。生成した画像は、ノートブックの画面左側のフォルダ内の該当ファイルをダブルクリックすることにより見ることができます。
また、Colaboratoryのファイル保存は一時的なものなので、気に入った画像はダウンロードして、自分のPCに保存してください。
(4) 公開ノートブックからのインストール
コマンド入力の不要なGUIでの操作が可能なSDをノートブック形式で公開している方(だだっこぱんださん)がおられましたので、該当ページのリンクを以下に掲載しておきます。上から順番に実行していくだけで、SDのインストールが可能であり、img2imgも使用できます。
※ メインプログラムのインストールが終わらない場合は、最終行の「demo.launch(debug=True)」を「demo.launch(debug=False)」に書き換えると上手くいくようです。
3.img2imgによる人物の表情の変更
前回、SDで文章から生成した画像を元に、img2imgで表情の変更ができるかどうか挑戦してみました。入力画像として用意したのは、以下の画像です。

ちなみに、SDにプロンプトとして入力した呪文は「a detailed oil painting of attractive and active young lady, beautiful and cute face, cyberpunk, dynamic by UnrealEngine5」です。
(1) 笑っている表情への変更
上の画像を入力画像とし、プロンプトに「smiling」と入力して、img2imgに画像生成させたのが以下の画像です。

(2) 泣いている表情への変更
次に、プロンプトに「crying」と入力して、img2imgに画像生成させたのが以下の画像です。
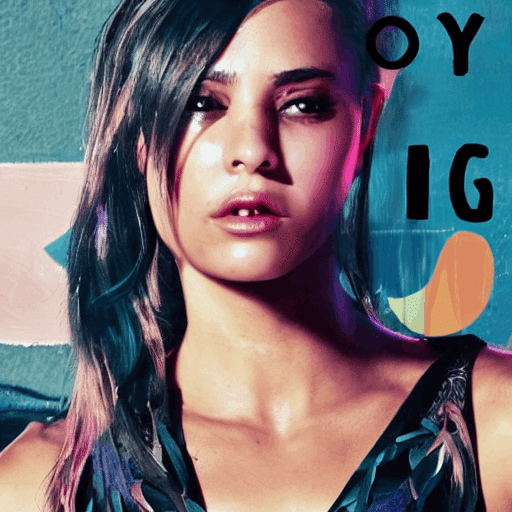
(3) 怒っている表情への変更
最後に、プロンプトに「angry」と入力して、img2imgに画像生成させた結果が以下の画像です。

次に、strengthを0.75から0.5に変更して、同じようにimg2imgに画像生成させた結果が以下の画像です。

このようにstrengthを小さくすると、元の画像に近づき、大きくすると、元の画像から離れていきます。
また、guidance_scaleを大きくすると、よりプロンプトの指示に従うようになります。
これらの数字をいじることによって、細かく表情を管理していくことができそうです(思い通りの表情を作るのは難しいですが)。
今回は、顔が変わってしまう場合もありましたが、同じ人物の表情や姿勢などを変えた画像が簡単に生成できるのなら、これを使って、漫画を描いたりすることもできそうです。
また、簡単に悪用もできそうですが、そういうことをすると、規制が厳しくなったり、サービスが停止したりして、自分たちの首を絞めることになるので、絶対にやめましょう。
なお、現役の漫画原作者のRootportさんがMidjourneyを使って実験的に描いた「サイバーパンク桃太郎」のようなすごい作品も、既にあります。