
Advanced Data Analysis(旧Code Interpreter)でどんなファイル操作ができるのか調べてみました

ChatGPTの公式プラグインであるCode Interpreter(以下、CIという。)は、様々なファイルを読み書きしたり、編集したりすることができます。
そこで、今回、CIがどんなファイルをどのように扱うことができるのか調べてみました。
1.CIで扱える基本的なファイル
Code Interpreterは、主にテキストベースのファイルを読み書きすることができます。これには以下のようなファイルが含まれます。
テキストファイル(.txt)
CSV ファイル(.csv)
JSON ファイル(.json)
Python ファイル(.py)
Markdown ファイル(.md)
Jupyter notebook ファイル(.ipynb)
HTML ファイル(.html)
XML ファイル(.xml)
2.CIで使えるPythonライブラリ
現在のChatGPTの環境では、標準的なPythonライブラリと一部の追加ライブラリが利用可能です。以下に主要なライブラリを示します。
標準ライブラリ: これらはPythonに付属しているライブラリで、追加のインストールが必要ありません。例えば、math, datetime, json, re, random, statisticsなどがあります。
NumPy: 数値計算を効率的に行うためのライブラリです。大量の数値データを扱う際や、高度な数学的演算を行う際に非常に役立ちます。
Pandas: データ分析を行うためのライブラリです。表形式のデータを効率的に扱い、加工、分析することが可能です。
Matplotlib: データの視覚化を行うためのライブラリです。折れ線グラフ、ヒストグラム、散布図など、様々な種類のグラフを作成することが可能です。
SciPy: 科学技術計算を行うためのライブラリです。最適化、線形代数、積分、補間など、多くの科学計算機能を提供しています。
scikit-learn: 機械学習を行うためのライブラリです。分類、回帰、クラスタリングなど、多くの機械学習アルゴリズムを提供しています。
上記のライブラリ以外にも、多くのライブラリが利用可能となっています。
3.画像、音声ファイル
特定のライブラリを使用して、画像や音声などのバイナリファイルを扱うことができます。
(1) 画像ファイル
画像ファイルを操作するために、以下のライブラリが利用可能です。
① Pillow (PIL)
Pythonで最も広く使われている画像処理ライブラリです。jpeg, png, bmpなどの多くの形式の画像ファイルの読み書きや編集をサポートしており、以下のようなことができます。
画像の読み込みと保存
画像の形式変換(RGBからグレースケールへの変換など)
画像のリサイズ、回転、切り取り(クロッピング)
画像の明るさ、コントラスト、色相などの調整
フィルタリング(ぼかし、シャープ化など)
② OpenCV
コンピュータビジョンと機械学習に関連する多くのアルゴリズムを含む強力なライブラリです。jpeg, png, bmp, webp, tiffなど多くの形式の画像ファイルの読み書きや編集をサポートしており、以下のようなことができます。
画像の読み込みと保存
画像の形式変換(RGBからグレースケールへの変換など)
画像のリサイズ、回転、切り取り(クロッピング)
フィルタリング(ぼかし、エッジ検出など)
画像の特徴抽出(SIFT、 SURFなど)
画像からのオブジェクト検出(顔検出など)
画像のステッチング(パノラマ作成)
動画のフレームごとの画像解析
③ matplotlib
このライブラリは主にデータの視覚化に使われますが、画像の読み込みや表示も可能です。出力結果をPDFファイルに保存することもできます。
【ピカチュウの画像の生成と編集】
以下のプロンプトでピカチュウの画像を生成してもらいました。
① SVGでピカチュウの絵を描く
ピカチュウの絵をSVGで描いてダウンロードできるようにしてください。ピカチュウはポケモンのキャラクターで、複雑な形状やディテールを持っています。ここでは、シンプルなスタイルでピカチュウの顔をSVGで描いてみましょう。
以下はシンプルなピカチュウの顔を描くSVGコードです:
作業完了 コードの詳細を表示
シンプルなピカチュウのSVGファイルを作成しました。以下のリンクからダウンロードできます:
ピカチュウのSVGをダウンロード
注:このSVGはシンプルなスタイルでの表現です。公式なキャラクターのデザインとは異なる場合がありますので、ご了承ください。
以下がダウンロードしたSVGファイルです。

② PILでピカチュウの絵を描く
PILを使用し、基本的な画像を組み合わせて、ピカチュウに似た画像を描いてみてください。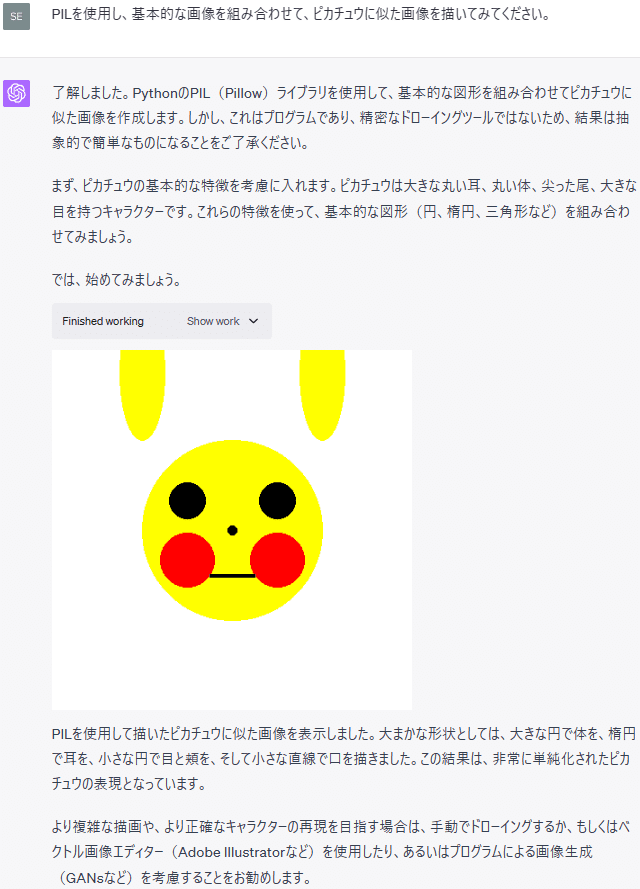
次に、以下のプロンプトでピカチュウの画像を回転させてみました。
この画像が連続して回転するGIFファイルを作成してください。
なお、このGIFを作成するために生成されたコードは以下のとおりです。
from PIL import ImageSequence
# Create a blank list for storing rotated images
rotated_images = []
# Rotate the image in 10 degree increments and store
for angle in range(0, 360, 10):
rotated_image = image.rotate(angle)
rotated_images.append(rotated_image)
# Save as a GIF
rotated_images[0].save('rotating_pikachu.gif', save_all=True, append_images=rotated_images[1:], optimize=False, duration=100, loop=0)次に、以下のプロンプトでピカチュウの画像の色を変化させてみました。
この画像の色相が連続して変化するGIF画像を作成してください。
なお、このGIFを作成するために生成されたコードは以下のとおりです。
import numpy as np
# Create a blank list for storing images with changed hues
hue_changed_images = []
# Change the hue in 10 degree increments and store
for hue in range(0, 256, 10):
hue_changed_image = change_hue(image, hue)
hue_changed_images.append(hue_changed_image)
# Save as a GIF
hue_changed_images[0].save('hue_changing_pikachu.gif', save_all=True, append_images=hue_changed_images[1:], optimize=False, duration=100, loop=0)次に画像生成AIで生成した画像をアップロードして、次々と色が変わるGIFアニメーションを作成しました。
この画像の色相が次々と変わっていくGIFファイルを作成してください。出力されたGIFファイルは以下のとおりです。

次に、画像の色が段々明るくなって消え、また元に戻ってくるGIFアニメーションを作成しました。
この画像が15フレームで色が段々明るくなり、白くなって完全に消え、そこで5フレームストップして、また15フレームかけて元の画像に戻っていくことを繰り返すGIFアニメーションを作成してください。


CIが生成した画像を表示するコード
from PIL import Image
# Load the image
original_image = Image.open('/mnt/data/ロボット5.jpg')
original_image.show()
# Get the size of the image
image_width, image_height = original_image.size
image_width, image_heightCIが生成したRGB値を増減させて画像の明るさを変えるコード
import numpy as np
# Number of frames for the fade in and fade out
num_fade_frames = 15
# Create a list to store the frames
frames = []
# Add the original image to the frames
frames.append(original_image)
# Create the fade in frames
for i in range(1, num_fade_frames + 1):
# Calculate the alpha value
alpha = i / num_fade_frames
# Create a new image with the same size as the original image, filled with white color
white_image = Image.new("RGB", (image_width, image_height), (255, 255, 255))
# Create a new image that is a combination of the original image and the white image
fade_in_frame = Image.blend(original_image, white_image, alpha)
# Add the fade in frame to the frames
frames.append(fade_in_frame)
# Create the pause frames
for _ in range(5):
# Add the white image to the frames
frames.append(white_image)
# Create the fade out frames
for i in range(num_fade_frames - 1, -1, -1):
# Calculate the alpha value
alpha = i / num_fade_frames
# Create a new image that is a combination of the original image and the white image
fade_out_frame = Image.blend(original_image, white_image, alpha)
# Add the fade out frame to the frames
frames.append(fade_out_frame)
# Check the number of frames created
len(frames)CIが生成したGIFアニメーションを作成するコード
# Create the GIF animation with each frame displayed for 0.2 seconds
gif_filename_02 = "/mnt/data/animation_02.gif"
frames[0].save(
gif_filename_02,
save_all=True,
append_images=frames[1:],
duration=200,
loop=0
)
gif_filename_02これ以外にも、画像から様々なGIFアニメーションが作成できるようです。
(2) 音声ファイル
音声ファイルを操作するためのモジュールとして、scipy.io.wavfileが利用可能です。これは、SciPyライブラリの一部で、WAV形式の音声ファイルを読み書きするためのモジュールです。主に以下の2つの関数を提供しています。
read(filename): WAVファイルを読み込み、サンプリングレート(1秒あたりのサンプル数)と音声データの配列を返します。音声データの形式は通常、16ビット整数(numpy.int16)または32ビット浮動小数点数(numpy.float32)です。
write(filename, rate, data): サンプリングレートと音声データの配列を指定して、WAVファイルを書き出します。書き出される音声データの形式は、入力されたデータの形式に依存します。
これらの関数を使用すると、WAVファイルから音声データを読み込み、そのデータを操作(例えば、フィルタリングやエフェクトの適用)し、結果を新しいWAVファイルとして保存することができます。
ただし、scipy.io.wavfileは比較的基本的な機能しか提供しておらず、音声データのエンコーディングや圧縮、複数チャンネルの音声、非PCM形式のWAVファイルなど、より高度な音声ファイルの操作には対応していません。
また、現在の環境では、MP3ファイルを直接扱うことはできません。PythonでMP3ファイルを扱う場合は、librosaやpydubなどのライブラリを使用するのが一般的ですが、これらのライブラリはサポートされていません。
MP3ファイルを扱いたい場合は、まずMP3をWAVに変換し、その上で、SciPyなどの音声処理ライブラリを使用してWAVファイルを操作してください。
【ピアノの音階の生成】
以下のとおり、ピアノの音階を生成して、WAVファイルで出力してもらいました。
ピアノの音階を1オクターブ生成して、一つのWAVファイルにまとめてください。ピアノの音階を1オクターブ生成し、一つのWAVファイルにまとめることができました。以下のリンクからファイルをダウンロードできます。
synthesized_octave.wav
これは単純なビープ音で各音階の基本周波数を持つ音を順番に連結したものです。再生してみてください。
以下のWAVファイルが単純なビープ音で各音階の基本周波数を持つ音を順番に連結したものです。
なお、このWAVファイルを作成するために生成されたコードは以下のとおりです。
import numpy as np
from scipy.io.wavfile import write
# Parameters
sample_rate = 44100 # number of samples per second
note_duration = 1.0 # duration of each note in seconds
# Frequencies of the piano notes from C4 to C5
frequencies = {
"C4": 261.63,
"C#4/Db4": 277.18,
"D4": 293.66,
"D#4/Eb4": 311.13,
"E4": 329.63,
"F4": 349.23,
"F#4/Gb4": 369.99,
"G4": 392.00,
"G#4/Ab4": 415.30,
"A4": 440.00,
"A#4/Bb4": 466.16,
"B4": 493.88,
"C5": 523.25,
}
# Create an array to hold the full audio sequence
full_audio = np.array([], dtype=np.int16)
# Append each note to the full audio
for note, freq in frequencies.items():
# Generate the time values for each sample
t = np.linspace(0, note_duration, int(sample_rate * note_duration), False)
# Generate the audio signal
signal = np.sin(freq * t * 2 * np.pi)
# Ensure that highest value is in 16-bit range
audio = signal * (2**15 - 1) / np.max(np.abs(signal))
audio = audio.astype(np.int16)
# Append the audio for this note to the full audio
full_audio = np.append(full_audio, audio)
# Write the full audio to a WAV file
write('/mnt/data/synthesized_octave.wav', sample_rate, full_audio)次に、以下のような指示を出してみました。

以下のファイルがこうしてできたWAVファイルです。
このWAVファイルを作成するためにCIが生成したコードは以下のとおりです。
import numpy as np
from scipy.io.wavfile import write
# Sampling rate
sr = 44100 # 44100 samples per second
# Frequencies for the notes
frequencies = {
'ド': 261.63,
'レ': 293.66,
'ミ': 329.63,
'ファ': 349.23,
'ソ': 392.00,
'ラ': 440.00,
'シ': 493.88
}
# Note sequence
notes = ['ド', 'ミ', 'ソ', 'ド', 'ミ', 'ソ', 'ラ', 'ラ', 'ラ', 'ソ', 'ファ', 'ファ', 'ファ', 'ファ', 'ミ', 'ミ', 'ミ', 'レ', 'レ', 'レ', 'ド']
# Generate the audio for each note
audio = np.concatenate([
np.sin(2 * np.pi * np.arange(sr) * frequencies[note] / sr)
for note in notes
])
# Ensure that highest value is in 16-bit range
audio *= 32767 / np.max(np.abs(audio))
audio = audio.astype(np.int16)
# Write audio to wav file
write('/mnt/data/song.wav', sr, audio)
'/mnt/data/song.wav'「ファ」が一つ多すぎるようです😓
4.Microsoft Officeファイル
PythonにはMicrosoft Office関連のファイルを読み書きするためのライブラリがいくつか存在します。以下に主要なファイルタイプごとの一般的なライブラリを示します。
(1) Wordファイル(.docx)
python-docxは、PythonでMicrosoft Word(.docx)ファイルを読み書きするためのライブラリです。このライブラリを使用すると、以下のようなことが行えます。
新しいドキュメントの作成:空のドキュメントを作成し、その中にテキスト、画像、テーブルなどを追加できます。
既存のドキュメントの読み込み:既存のWordファイルを読み込み、その内容を抽出したり、操作したりすることができます。
テキストの追加と編集:ドキュメントにテキストを追加したり、既存のテキストを編集したり、書式設定(例えば、フォント、サイズ、色など)を行うことができます。
パラグラフと見出しの操作:ドキュメント内のパラグラフと見出しを追加、編集、削除することができます。
表の操作:ドキュメントに表を追加し、そのセルの内容を編集することができます。
画像の追加:ドキュメントに画像を挿入することができます。
ただし、python-docxは一部の高度なWord機能をサポートしていません。たとえば、ヘッダーやフッター、フットノートやエンドノート、コメント、トラックチェンジなどの操作はサポートされていません。また、既存のドキュメントから画像を抽出する機能もありません。
なお、python-docxはdocx形式のファイルのみをサポートしています。古いバージョンのWordで使用されていたdoc形式のファイルはサポートされていません。
(2) Excelファイル(.xlsx 等)
① Pandas
Pandasは、データ分析を行うためのライブラリで、データフレームという形式でデータを効率的に扱うことができます。CSVやExcelファイルの読み書きもサポートしています。
Pandasは、Excelファイルに対して、以下のような操作が可能です。
ファイルの読み込み:pandas.read_excel関数を使用してExcelファイルを読み込み、データフレームに変換することができます。読み込む際には、特定のシートを指定したり、ヘッダーやフッターをスキップしたり、特定の列をインデックスとして使用したりすることが可能です。
データフレームの操作:読み込んだデータフレームに対して、様々なデータ操作を行うことができます。例えば、フィルタリング、ソート、集約、欠損値の補完、新しい列の追加、既存の列の変換などが可能です。
ファイルへの書き込み:DataFrame.to_excel関数を使用して、データフレームをExcelファイルに書き出すことができます。書き出す際には、特定のシートを指定したり、ヘッダーやインデックスの有無を指定したりすることが可能です。
ただし、Pandasはデータの読み書きに特化しているため、Excelのようなスプレッドシート特有の機能(例えば、セルの書式設定、数式の使用、グラフの作成など)を直接操作することはできません。
また、xls形式のファイルはサポートしていません。
② openpyxl
openpyxlは、PythonでExcel 2010以上のファイル(.xlsx/.xlsm)を読み書きするためのライブラリです。このライブラリを使用すると、Excelファイルの中身を詳細に操作することができます。具体的には、以下のような操作が可能です。
ファイルの読み込み:既存のExcelファイルを読み込むことができます。
シートの操作:ワークブック内のワークシートを追加、削除、名前の変更、順序の変更を行うことができます。セルの操作:特定のセルに値を設定したり、値を取得したりすることができます。また、セルの書式設定(フォント、色、罫線、背景色など)を変更することも可能です。
列と行の操作:列や行を挿入、削除、または調整(幅や高さの設定)することができます。
数式の使用:Excelの数式をセルに設定することができます。
画像やグラフの挿入:Excelシートに画像やグラフを挿入することができます。
データのフィルタリングやソート:シートのデータをフィルタリングやソートすることができます。
これらの機能を使用すると、Pandasだけでは対応できない、Excel特有の詳細な操作を行うことができます。
openpyxlも、xls形式のファイルはサポートしていません。
(3) PowerPoint(.pptx)
python-pptxは、PythonでPowerPoint(.pptx)ファイルを読み書きするためのライブラリです。このライブラリを使用すると、以下のようなことが行えます。
新しいプレゼンテーションの作成:空のプレゼンテーションを作成し、その中にスライド、テキストボックス、図形、画像などを追加できます。
既存のプレゼンテーションの読み込み:既存のPowerPointファイルを読み込み、その内容を抽出したり、操作したりすることができます。
スライドの追加と削除:新しいスライドを追加したり、既存のスライドを削除したりすることができます。
テキストの追加と編集:スライドにテキストボックスを追加し、その中にテキストを入力したり、書式設定(例えば、フォント、サイズ、色など)を行うことができます。
図形の操作:スライドに図形(例えば、矩形、円、線など)を追加し、その位置、サイズ、色、線の太さなどを設定することができます。
画像の追加:スライドに画像を挿入することができます。
表の操作:スライドに表を追加し、そのセルの内容を編集することができます。
ただし、python-pptxは一部の高度なPowerPoint機能をサポートしていません。たとえば、アニメーション、トランジション、オーディオやビデオの挿入などの操作はサポートされていません。また、既存のプレゼンテーションから画像を抽出する機能もありません。
なお、python-pptxはpptx形式のファイルのみをサポートしており、古いバージョンのPowerPointで使用されていたppt形式のファイルはサポートしていません。
5.PDFファイル
CIで使えるPDFのライブラリには以下のようなものがあります。
① PyPDF2
PyPDF2は、PDFファイルの読み書きと操作を行うためのライブラリです。ページの抽出と追加、PDFの結合と分割、順序変更などの基本的なPDF操作を行うことができます。
PyPDF2は主に既存のPDFファイルを操作するためのライブラリであり、新しいPDFファイルをゼロから作成する機能は提供していないため、PDFファイルを新規作成する場合は、ReportLabなどの他のライブラリを使用する必要があります。
PDFからテキストを抽出する機能は、PDFがテキストベースの場合のみ有効であり、スキャンされた画像からテキストを抽出するには、OCR(光学的文字認識)ライブラリが必要です。
また、PyPDF2のテキスト抽出機能には限界があり、複雑なレイアウトや特殊な文字エンコーディング、日本語などの非ラテン文字の扱いに弱点があります。そのため、日本語のテキストを含むPDFからのテキスト抽出は、上手くいかないことが多いです。その場合は、PDFMinerなどの他のライブラリを使用することをお勧めします。
② PDFMiner
PDFMinerはPythonでPDFファイルを解析するためのライブラリで、PDFファイルからのテキスト抽出、レイアウト情報の取得、著者名、作成日時、タイトルなどのメタデータの抽出、画像抽出などを行うことができます。
PDFMinerは、日本語を含む非ラテン文字の扱いにも強く、文字のエンコーディングやフォントの問題によるテキスト抽出の問題を比較的うまく処理します。
実際に試してみましたが、日本語のテキストが書かれたPDFファイルからテキスト抽出して、内容を把握することに成功しました。
ただし、PDFMinerはPDFの作成や編集には使用できません。PDFの作成や編集を行う場合は、PyPDF2やReportLabなどの他のライブラリを使用する必要があります。
また、PDFMiner.sixは、Python 2と3の両方に対応したPDFMinerのフォークです。
③ ReportLab
ReportLabは、PythonでPDFを生成するためのライブラリです。図形、テキスト、画像、グラフィックス、表など様々なコンテンツをPDFに含めることができます。
ReportLabは、テキストの挿入、編集、フォントの選択、サイズの変更など、PDFで一般的に必要とされるテキスト操作をサポートしています。
また、基本的な図形の描画から複雑なグラフィックの作成までをサポートしていおり、JPEGやPNGなどの画像ファイルをPDFに挿入することも可能です。表を作成することもできます。
ページレイアウトとスタイルのカスタマイズもサポートしています。
ReportLabはPDFファイルの生成に特化したライブラリであり、PDFの読み込みやテキストの抽出には使えません。PDFからテキストを抽出するためには、PDFMinerなどの他のライブラリを使用する必要があります。
【PDFファイルまとめ】
結論としては、日本語を含むPDFファイルからのテキストの抽出にはPDFMiner、新しいPDFファイルの作成にはReportLabを使用するべきです。また、ページの抽出、PDFファイルの結合、分割などの操作はPyPDF2、テキスト、図形、画像などの挿入にはReportLabが使えます。
【英語論文PDFファイルの要約】
arXivの英語論文のPDFファイルから各セクションの見出しを抽出し、セクションごとの要約を作成しました。
入力 PDFMinerでこの論文のテキストを抽出し、その中から各セクションごとの見出しを抜き出して、一覧を表示してください。
出力 ご指示に従って、大見出しと小見出しを適切に並べ替えました。結果は以下の通りです:
1 Introduction
2 LONGNET
2.1 Preliminary
2.2 Dilated Attention
2.3 Multi-Head Dilated Attention
2.4 Computational Complexity and Token Dependency
3 LONGNET as a Distributed Trainer: Scaling up to 1B Tokens
3.1 Distributed Algorithm
3.2 Scaling up to 1B Tokens
4 Experiments on Language Modeling
4.1 Setup
4.2 Results
4.3 Scaling Curves of Sequence Length
4.4 Scaling up Model Size
4.5 Long Context Prompting
5 Conclusion and Future Work
これらの見出しは、論文の各セクションを示しています。
入力 各セクションの見出しを基にして、元の文書を再確認し、セクションごとに要約を作成してください。
出力 この論文は、非常に長いシーケンスを扱うことができる新しいTransformerモデル、LONGNETについて述べています。以下、セクションごとの要約を日本語で提供します。
1 はじめに
(テキストが抽出できなかったため、具体的な要約はできませんが、通常、このセクションでは研究の背景や目的、主な貢献を説明します)
2 LONGNET
(テキストが抽出できなかったため、具体的な要約はできませんが、このセクションではLONGNETの主要な概念や特性を説明しています)
2.1 予備知識
Transformerの核心は自己注意機能で、クエリと一連のキーと値を出力にマッピングします。しかし、自己注意機能はシーケンス長に対する二次的な依存性のため、長いシーケンスに苦労します。その問題を緩和するために、疎な注意機能が提案され、クエリがキーと値の一部にのみアクセスできるようにします。
2.2 ダイレーテッド・アテンション
ダイレーテッド・アテンションは、入力(Q, K, V)を等しくセグメントに分割し、それぞれのセグメントはシーケンスの次元に沿って間引かれます。
2.3 マルチヘッド・ダイレーテッド・アテンション
マルチヘッド・ダイレーテッド・アテンションでは、異なる頭部で計算を行い、クエリ-キー-バリューペアの異なる部分を疎にします。
2.4 計算複雑性とトークン依存性
ダイレーテッド・アテンションを用いて、各クエリ-キー-バリューペアは RN×d からRw/r×d へと疎にされ、注意計算のフロップス(浮動小数点演算)は2Nwd/r^2 と見積もられます。
3 LONGNETと分散トレーニング
ダイレーテッド・アテンションの計算複雑性が大幅に低減されたにも関わらず、単一のGPUデバイス上でシーケンス長を百万レベルにスケーリングすることは、計算とメモリの制約により不可能です。
3.1 分散アルゴリズム
LONGNETの線形計算複雑性を利用して、シーケンス次元の分散トレーニングを行います。
3.2 1Bトークンまでのスケーリング
現代の分散システムで1Bトークンまでスケーリングする可能性を検証します。
4 言語モデリングにおける実験
LONGNETを言語モデリングに適用します。バックボーンアーキテクチャは、MAGNETOとXPOSの相対位置エンコーディングを用い、標準的な注意機能をダイレーテッド・アテンションで置き換えます。
4.1 セットアップ
LONGNETを言語モデリングに適用します。バックボーンアーキテクチャは、MAGNETOとXPOSの相対位置エンコーディングを用い、標準的な注意機能をダイレーテッド・アテンションで置き換えます。
4.2 結果
LONGNETを、バニラのTransformerとスパースTransformerと比較します。
4.3 シーケンス長のスケーリング曲線
以前の研究は、言語モデルがパラメータやトレーニングトークンを増やすことによるいくつかのスケーリング法則に従うことを示しています。
4.4 モデルサイズのスケーリング
大規模な言語モデルの重要な特性は、損失がコンピュートとパワーローとしてスケールすることです。
4.5 ロングコンテキストプロンプト
プロンプトは、言語モデルにガイダンスを提供し、追加情報を提供するための重要な方法です。
5 結論と今後の展望
我々はLONGNETを紹介します。これは、シーケンス長を10億トークン以上にスケーリングできるTransformerのバリエーションで、短いシーケンスに対する損失はありません。
これらの要約は、各セクションの主要なポイントを抽出していますが、全体の文脈を理解するためには、各セクション全体を読むことをお勧めします。
「1 はじめに」などは読み取れていませんが、ある程度要約に成功したと言えるでしょうか。
なお、ここには最終的な出力結果のみを表示していますが、実際には、途中で何度も失敗(2.1や3.1などの小見出しは読み取れるのに、「1 はじめに」の大見出しは読み取れないなど)しています。まだまだPDFファイルの読み取りは、完全ではないようです。
6.圧縮ファイル
PythonにはZIPファイルなどの圧縮ファイルを読み書きするための標準ライブラリがいくつかあります。以下に、主な圧縮形式とそれを扱うためのライブラリを示します。
ZIP (.zip): zipfile モジュールを使用すると、ZIPファイルを読み込んだり、新しいZIPファイルを作成したりすることができます。
gzip (.gz): gzip モジュールを使用すると、gzip形式のファイルを読み込んだり、新しいgzipファイルを作成したりすることができます。
tar (.tar, .tar.gz, .tar.bz2 など): tarfile モジュールを使用すると、tar形式のファイルを読み込んだり、新しいtarファイルを作成したりすることができます。
これらのモジュールはPythonの標準ライブラリの一部であり、追加のインストールは必要ありません。これらを使用して、圧縮ファイルを解凍したり、新たに圧縮ファイルを作成したりすることが可能です。
ただし、7z形式やrar形式などの特殊な圧縮形式のファイルを扱うためのライブラリはサポートしておらず、これらの圧縮ファイルを直接扱うことはできません。これらのファイルを扱う場合は、予め他の形式(例えばZIP)に変換してください。
7.その他のファイル
Pythonは様々なデータ形式を扱うことができる柔軟性を持っています。上記で述べた形式以外にも、以下のようなファイル形式を扱うことができます。
YAML (.yaml): PyYAMLライブラリを使ってYAMLファイルを読み書きすることができます。
INI (.ini): Pythonの組み込みライブラリであるconfigparserを使ってINIファイルを読み書きすることができます。
SQLite (.sqlite, .db): Pythonの組み込みライブラリであるsqlite3を使ってSQLiteデータベースを操作することができます。
HDF5 (.h5, .hdf5): h5pyライブラリやPandasのHDFStoreなどを使ってHDF5形式のファイルを読み書きすることができます。
8.画像やテキストの読み取り
Pythonは画像やテキストを含む多くのファイル形式の読み取りをサポートしています。
テキストファイルの場合、Pythonの組み込み関数を使用してファイルを開き、内容を読み取ることができます。また、より複雑なテキスト形式(例えばCSVやJSON)の場合は、専用のライブラリ(csv, jsonなど)を使用することで読み取りが可能です。
画像ファイルの場合、Pythonのライブラリ(PILやOpenCVなど)を使用して画像データを読み取ることができます。これらのライブラリは、画像のピクセルデータを数値の配列として読み取ることを可能にします。
また、PDFやWordなどの複雑なドキュメント形式の場合、専用のライブラリ(PyPDF2やpython-docxなど)を使用してテキスト内容を抽出することが可能です。しかし、これらのライブラリで読み取れるのは主にテキスト内容であり、レイアウト情報や画像内容を正確に把握することは困難です。
9.OCR機能
(1) 英文が記載された画像の読み取り
以下の画像ファイルに記載された文字を読み取ることができるか試してみました。

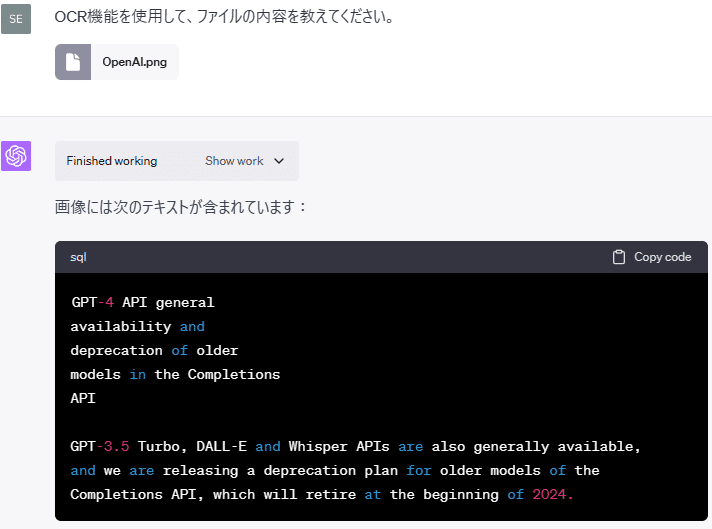
OCR機能を使用するためにCIが生成したコードは以下のとおりです。
from PIL import Image
import pytesseract
# Open the image file
img = Image.open('/mnt/data/OpenAI.png')
# Use Tesseract to do OCR on the image
text = pytesseract.image_to_string(img)
text以上のように、Pythonの Pytesseractライブラリを使用して、OCR機能で画像に記載されたテキストを読み取ることができました。
なお、今回は、テキストの読み取りに成功しましたが、Pytesseractライブラリのインポートが拒否される場合もあり、毎回成功する訳ではありません。
(2) 日本語文が記載された画像の読み取り
次に、最初の画像のテキストを日本語訳した以下の画像をアップロードして、日本語の文字を読み取ることができるか試してみます。

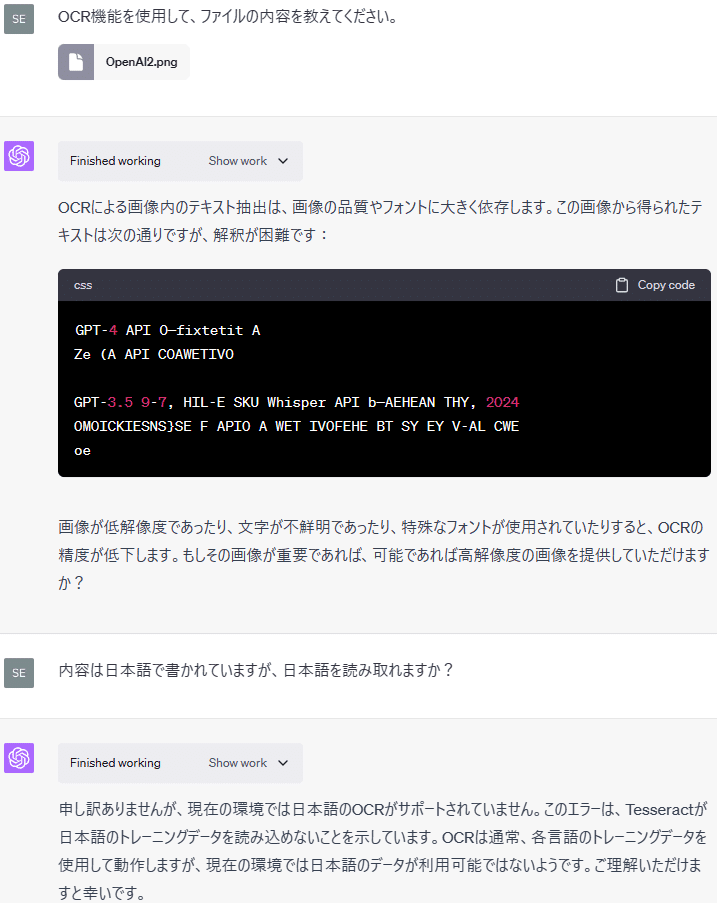
このように日本語のOCRには対応しておらず、日本語を読み取ることはできないようです。
(3) 英文が記載されたPDFファイルの読み取り
最初の英文が記載された画像ファイルをPDF化したファイルを用意してアップロードしました。このファイルに記載されたテキストを読み取ることができるか試してみます。
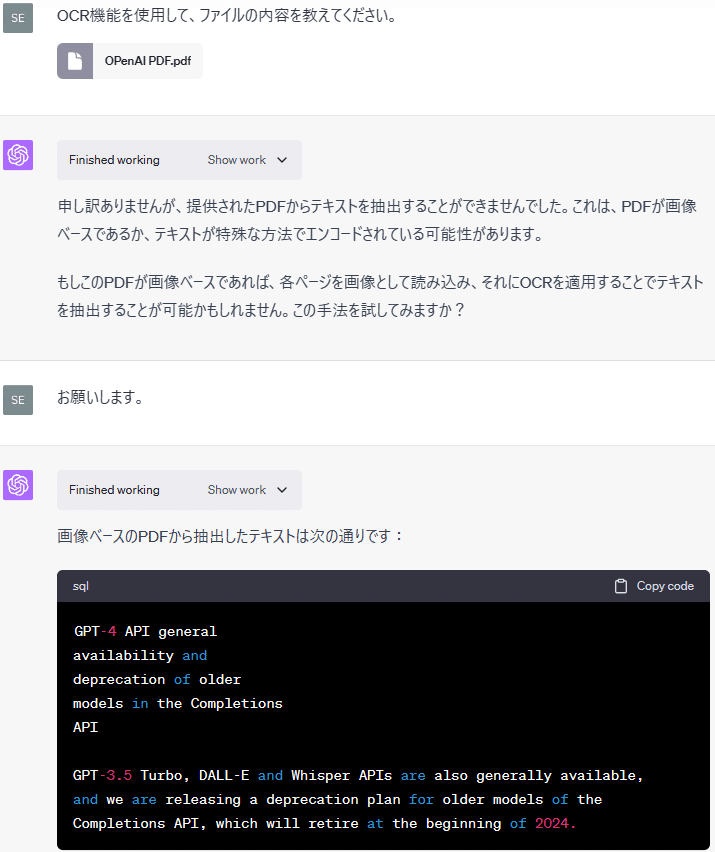
最初はテキストの読み取りに失敗しましたが、2回目にテキストの読み取りに成功することができました。
最初に読み取りに失敗したときにCIが生成したコードは以下のとおりです。
from PyPDF2 import PdfFileReader
# Open the PDF file in read-binary mode
pdf_path = '/mnt/data/OPenAI PDF.pdf'
pdf = open(pdf_path, 'rb')
# Use PyPDF2 to read the text in the PDF
pdf_reader = PdfFileReader(pdf)
total_pages = pdf_reader.getNumPages()
# Extract text from each page and combine it
pdf_text = ''
for page_number in range(total_pages):
page = pdf_reader.getPage(page_number)
pdf_text += page.extractText()
pdf_textPyPDF2ライブラリのPdfFileReaderを使用したようですが、PDFファイルに記載されたテキストの内容を読み取ることはできませんでした。
次に、テキストの読み取りに成功したときにCIが生成したコードは以下のとおりです。
import pdf2image
# Convert the PDF to a list of images
images = pdf2image.convert_from_path(pdf_path)
# Use OCR to get the text from each image
pdf_image_text = ''
for image in images:
pdf_image_text += pytesseract.image_to_string(image)
pdf_image_text今回は、PytesseractライブラリのOCR機能を併せて使用することにより、テキストの読み取りに成功したようです。
(4) 日本語文が記載されたPDFファイルの読み取り
次に、上記(2)で使用した日本語文が記載された画像ファイルをPDF化したファイルを用意してアップロードしました。
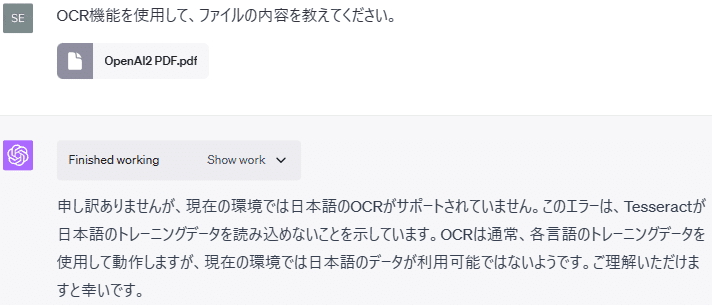
やはり、日本語のOCRには対応しておらず、日本語を読み取ることはできないようです。
10.まとめ
以上のように、CIは様々なファイルを扱うことができます。
ユーザーが作業を依頼すれば、CIが自動的に必要なライブラリをインポートしてくれるので、普段は、あまりライブラリの種類を気にしなくても大丈夫です。
しかし、プロンプトで使用するライブラリを指定することにより、今までできなかったことができたり、作業を効率的に進められたりすることがあるので、是非、様々なライブラリの特徴を知って活用してみてください。
一方で、CIは標準ライブラリ以外のPythonライブラリにも対応していますが、サポートしていないライブラリも多く、それらを外部から追加することはできないようです。
特に、Matplotlibのグラフ作成機能やPytesseractのOCR機能などが日本語に対応しておらず、今後、日本語にも対応することが期待されます。
また、CIはインターネットアクセスが制限されており、APIやWebサイトのデータを利用できないのが残念です。
OpenAIは、セキュリティ上の理由からインターネットアクセスを制限しているようですが、これができると、CIの用途が大きく広がるため、是非、制限の緩和を検討してもらいたいものです。
いずれにせよ、CIの利用できる範囲は非常に広く、様々な作業の自動化に役立ちそうです。
皆さんも、是非、色々な使い方を考えてみてください。CIは、ChatGPTの可能性を大きく広げる機能になるはずです。
※この記事は、ChatGPTの回答を基に作成しました。怪しい点は何度か質問するなどして確認しましたが、それでも誤りが残っている可能性がありますので、その点はご注意ください。