
GASでGoogleDrive上の音声ファイルをテキスト化する方法(1分未満Ver.)

はじめに
ChatGPT が文章を要約してくれるので、音声データを文字にできれば ChatGPT がより有意義に使いこなせそうだと思ったことがきっかけ。作ってから 1 分未満の音声データしか対応していないことに気付いたため、後ほど 1 分以上のデータに対応するものを作成予定です。
このブログは素人の筆者が「あったらいいな」と思ったものを”完全個人利用”を前提に作る際、調べたことや感じたことを踏まえつつ ChatGPT の助けを借りてまとめたものです。特にセキュリティに関しては素人ですので、レベルに応じて必要な対策を取ってください。
方針
Google Apps Script (GAS) を使用して GoogleDrive 上に用意された文字起こし用のフォルダ内にある FLAC 形式の音声ファイルをテキストに起こします。それを同じフォルダに TEXT 形式のファイルとして保存します。
フローチャート
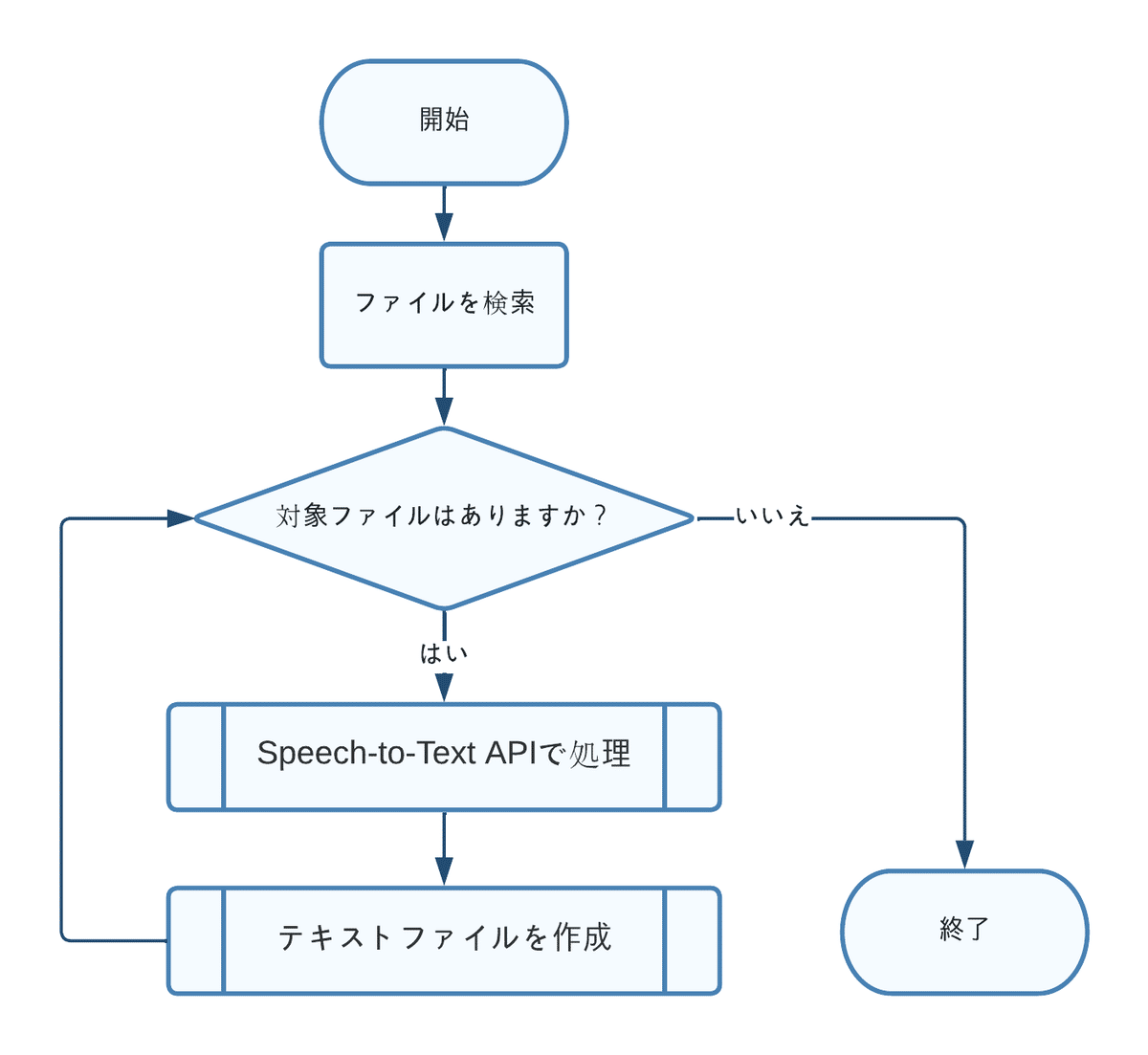
準備すること
GoogleDrive
1. 専用フォルダの作成
文字起こし用のフォルダを作成し、フォルダ ID を控えます。
2.テスト用音声ファイルを用意
1 分未満の音声ファイルを用意します。モノラルに変換した FLAC 形式のファイルを用います。(FLAC 形式の場合、後の設定が簡単なので)
すでにある音声ファイルはAudacityなどを使ってモノラルの FLAC 形式変換するとよいです。これから録音する場合は「Speech-to-Text API にデータを提供する際のベスト プラクティス」を参考に録音してください。
Google Cloud Platform(GCP)の設定
GCP の登録方法は割愛します。
1. プロジェクトの作成
プロジェクトを作成し、プロジェクト番号を控えます。
2. API とサービスの設定
「 OAuth 同意画面の設定」を設定します。
「有効な API とサービス」で、Google Drive API と Cloud Speech-to-Text API を有効にします。
「認証情報」で、「認証情報を作成>API キー」から API キーを作成し控えます。
Cloud Speech-to-Text API は毎月 60 分まで無料ですが、有料サービスのためキーの取り扱いには十分注意してください。
Google Apps Script (GAS)の設定
google ドライブまたはスプレッドシートなどからスクリプトを作成します。
1. 「プロジェクトの設定」から設定変更
「全般設定」の「マニフェスト ファイルをエディタで表示する」にチェックを入れます。
「Google Cloud Platform(GCP)プロジェクト」の「プロジェクトを変更」をクリックしプロジェクト番号を設定します。
2. `appsscript.json`ファイルに`oauthScopes`を追加
エディタに戻ると `appsscript.json`ファイルが表示されるので`oauthScopes`を追加します。
"oauthScopes": [
"https://www.googleapis.com/auth/drive",
"https://www.googleapis.com/auth/script.external_request"
]参照:Google API の OAuth 2.0 スコープ
3. 環境変数を設定する
控えておいたフォルダ ID と API キーを環境変数に設定します。
const newProperties = {
SPEECH_TO_TEXT_API_KEY: "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
GOOGLE_DRIVE_FOLDER_ID: "1234567890abcdefghijklmnopqrstuvwxyz",
};設定の方法はこちら ⇒GAS で環境変数を管理する
コードの説明
API リクエストの config 設定
const config = {
encoding: "FLAC",
languageCode: "ja-JP",
enableWordTimeOffsets: false,
model: "latest_long",
};音声ファイルの形式や録音環境に合わせて設定します。
`sampleRateHertz`は必須項目ですが`FLAC`ファイルと`WAV`ファイルは省略可能です。また、`model`は録音されている音声のタイプに合わせると結果が改善されることもありますが、設定しなくても動作します。
環境変数を取得する
const driveFolderId = getApiKey("GOOGLE_DRIVE_FOLDER_ID");
const apikey = getApiKey("SPEECH_TO_TEXT_API_KEY");「GAS で環境変数を管理する」のほうで`getApiKey`関数を定義しています。一時的に環境変数を使わずに動作させたい場合は、こちらの変数に直接代入すれば動作しますが、セキュリティの観点からおすすめはしません。
Speech-to-Text API で処理する関数
function getTranscriptForFile(file) {
// Google Speech APIへのURLを生成
const url = "https://speech.googleapis.com/v1/speech:recognize?key=" + apikey;
// 音声ファイルをBase64エンコード
const audioContent = Utilities.base64EncodeWebSafe(file.getBlob().getBytes());
// リクエストボディを生成
const requestBody = {
"config": config,
"audio": {
"content": audioContent
}
};
try {
// Google Speech APIにリクエストを送信
const response = UrlFetchApp.fetch(url, {
method: "post",
payload: JSON.stringify(requestBody),
contentType: "application/json",
muteHttpExceptions: true
});
// レスポンスを解析
const result = JSON.parse(response.getContentText());
const transcript = result.results[0].alternatives[0].transcript;
// エラーが発生した場合
if (result.error) {
throw new Error(result.error.message);
}
// 結果が正常に取得できなかった場合
if (!result.results || !result.results.length ||
!result.results[0].alternatives || !result.results[0].alternatives.length) {
throw new Error("結果が取得できませんでした");
}
// 音声認識結果を返す
return transcript;
} catch (e) {
// エラーが発生した場合はログを出力
Logger.log(file.getName() + "の処理中にエラーが発生しました: " + e);
}
}今回の記事のメインとなる関数です。ここまでの設定でこの関数に直接音声ファイルを渡せば音声認識の結果が帰ってきます。
ChatGPTと何度かキャッチボールした結果、汎用性を考慮して仕上げました。エラーの表示については、くどさを感じますが動作するので良しとします。
音声認識結果からテキストファイルを作成する関数
function createTextFileFromSpeech(file) {
// ファイル名を取得する
const fileName = file.getName();
// Speech-to-Text APIで処理する関数を実行する
const transcript = getTranscriptForFile(file);
// 音声認識結果をもとに、テキストファイルを作成する
const outputFile = DriveApp.getFolderById(driveFolderId).createFile(fileName.replace(/.flac$/, '.txt'), transcript);
// 元の音声ファイルのファイル名を変更
file.setName("済)" + fileName);
// 処理成功をログに記録する
Logger.log(fileName + " を処理し " + file.getName() + " へ変更しました");
}先ほど作った`getTranscriptForFile`関数にファイルを送ります。そして、取得したテキストを音声ファイルと同じ場所に同じ名前の`.txt`形式で保存します。処理済みファイルと未処理ファイルを区別するため、処理済みファイルのファイル名には"済)"を先頭に追加します。
スプレッドシートに保存するなど、目的に合わせて機能を変更する場合はこの関数を編集するとよいでしょう。
対象フォルダ内の未処理の`FLAC`ファイルを全て処理する関数
function processFilesInFolder() {
// フォルダオブジェクトを取得
const driveFolder = DriveApp.getFolderById(driveFolderId);
// .flacという拡張子を持つファイルを検索(処理済みのファイルは除外)
const files = driveFolder.searchFiles("title contains '.flac' and not title contains '済)'");
if (!files.hasNext()) {
Logger.log("該当するファイルが見つかりませんでした");
return;
}
// ファイルが残っている間、繰り返す
while (files.hasNext()) {
// 次のファイルを取得する
const file = files.next();
// 音声認識結果からテキストファイルを作成する関数を実行する
createTextFileFromSpeech(file);
}
}この記事全体の目的を果たすために実行する関数です。
先ほど処理済みのファイル名に”済)”を加えたのは、ここのファイル検索で除外するためでした。処理済みファイルを他のフォルダに移動したり削除する場合は`and not title contains '済)'`の部分は不要です。とにかく、処理したいファイルが検索出来ればいいのです。検索にヒットしたファイルを一つずつ`createTextFileFromSpeech`関数に送ります。
トリガー設定でこの`processFilesInFolder`関数を実行すれば、フォルダに音声ファイルを追加するだけで文字起こしすることもできます。
終わりに
最初に説明した通り、このプログラムは1分未満の音声にしか対応しておらず、実用性は限定的です。初めてChatGPTを使いながらプログラミングを行ったこと、用意したサンプル音声が1分未満であったことから、本番の音声を渡した時に初めて1分以上の音声に対応していないことが判明しました。
初めてのChatGPTとの共同作業であったため、記録の意味も含めてこのプログラムを公開しました。この記事の内容だけでも、試行錯誤を好む方は簡単にアレンジすることができると思います。何かの参考になれば幸いです。
この記事が参考になったら記事の購入またはサポートをお願いします!
本日のおまけ
開発に使用したテスト音声データ
この記事で作った関数の一発コピー用コードスニペット
ここから先は
¥ 100
読者の皆様からのサポートに、心より感謝しています。これからもより良い記事をお届けできるよう、日々精進してまいります!