
魔術として理解するお絵描きAI講座

やればやるほど呪術化する、AI画像錬成について。
以下は、その道の専門家にはメッチャ怒られるかもしれない、雑なロジックと制御講座。
いちおうメジャーなサービスでは、共通して動作するノウハウ(DALL-E2, MidJourney, StableEiffusion, DiscoDiffusion, crayon, dall-e mini 他)。

雑に理解する画像AIのしくみ
対話型のAIにとって、呪文とは画像錬成の方向性を定めるものにすぎない。
たとえば、以下は「I love apple」で錬成された画像の例である。どうにも、ふわっとしたものが出てくる
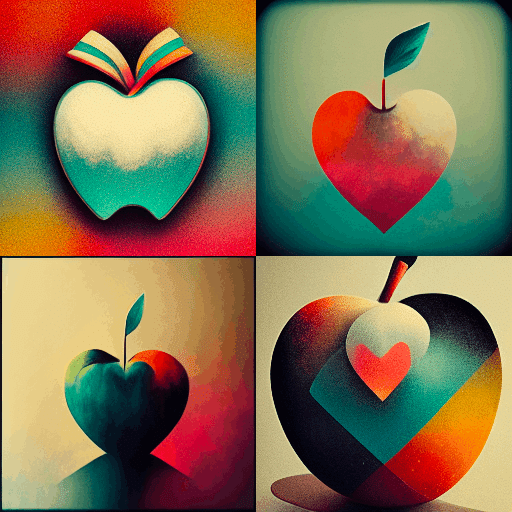
「Apple」という方向性は、「リンゴ」「青リンゴ」と「アップルコンピューター(旧レインボーロゴ」「アップルコンピュータ(新ロゴ)」など、複数の可能性を同時に持つからだ。
つまり、「Apple」とは、AIにとってはとてもあいまいな方向性なのだ。
写真かイラストかもわからない。ついでに「ハート」も合体してきてる。このような短い詠唱は、多くのケースで制御不能となる。
AIはあいまいな命令には、同時に成立するような絵を錬成してしまう(注、顔が分裂するのはまた別の事象です)。
すぐれたAI使役には、詠唱を通じて方向性を束ねる設計が必要となる。
以下は、「フルーツのアップル」と縛りをかけた詠唱。改善したが、まだ赤リンゴと青リンゴが同時に存在している。
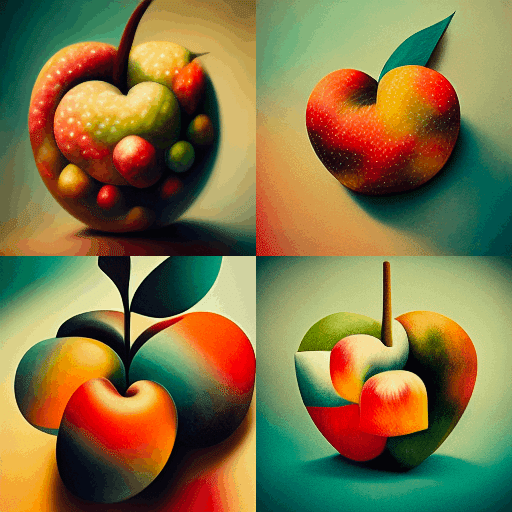
このように、りんごを1つ出すのにも、それなりの方向性詠唱が必要となる。
実はより安定した詠唱には、発想を変える必要がある。
「イーコマースサイト用の、画質の良い、シンプルな背景にある、単独の赤いりんご」
とすれば、一発でリンゴが錬成される。

「イーコマース用商品写真」は背景やレイアウトの再現性が高い。ここに気づけば、よい呪文を練れる。
だがAIのベクトルは数千次元におよぶ。無闇に単語をならべても、複数の単語が、お互いのベクトルを打ち消しあってしまう。
だからAIをよく使役するには、2つの理解「ベクトルの方向を強く適宜する力ある言葉の語彙力」と「再現性をもった呪文の組み立て」が必要になる。
まめちしき
色彩が、「赤と青と緑が混ざったような状態」のときは、ベクトルが曖昧すぎる状態と思われる。それはMidJourneyの画風ではない。もっとベクトルの限定が必要な状態。
力ある言葉を探せ
力ある言葉とは、明快な方向性をもった言葉である。「曖昧さのない純粋な単語」と言ってもよい。
これは、AIの学習の仕組みに起因する。AIはネットにある、画像とその解説文をペアにして学習している。無数のペアの学習から、可能性空間でもいうべきベクトル空間を形成する。
その仕組み上、「学習の中で内容がブレずに何度もでてくる画像と文字のペア」には、強い力が生まれる。
呪文詠唱の最終節に、"Unreal Engine"や"Playstation5"というルーンを置くと、画質が向上しやすい。これはAIが、記事と画像のペアから「アンリアルエンジン(ゲーム作成ツール名)は、画質がすごい」といった内容を学んでいるからだろう。
同様に、第一節に "beautiful concept art of" を付与するのも強い。これも「平均的なコンセプトアートと呼ばれる画像は、絵が上手い」からだ。
以下に比較図を示す。



個人的におすすめの強いルーンはカメラ設定だ。
詠唱の末節に、「Canon EOS 5D Mark 4と、SIGMA Art Lens 35mm F1.4 DG HSMレンズで撮影、F値2.4、ISO 200、シャッタースピード2000」など追加すると、品質が大きく高まる。
画質だけでなく、構図やライティング、ボケなどを含めて全体的にコントロールできる。

これは、「そのような表記がついている画像は、プロの写真や、メーカー公式のサンプル写真、ハイアマチュアがとった写真サイトの作品」とAIが学んでいるためだ。前ボケや後ろボケを狙って出したいときには、強いルーンとして機能する。

まず初心者は、遊びながら強いルーンのレパートリーを見つけていくとよいだろう。
力ある構文を探せ
詠唱時のワード選定の順番も大事である。
以下「ロボットのいる風景」と「風景にあるロボット」での表示の違い。


一見、おなじように見える命令でも、ロボットの扱いが大きく変わっているのがわかる。このように、「何をどういう順番で言うか?」は、画像錬成の品質を大きく左右する。
原則としては、おおまか「手前にある文ほど強く、後ろにある単語ほど弱い」「最後の文はそこそこ強い」「前置詞や関係代名詞の前の単語のほうが強くでて、後ろの単語のほうが弱くなる」というような特徴を、やんわりと持つ。
基本的には、「美術館や、写真サイト、画集のキャプションに近い文体」で、呪文を作るのがよい。
AI錬成を古からしている上級魔術師の間では、以下のような構成が定番となっているように思える。
<全体のフォーマット><主題><主題の補足><作者><全体の補足><フレーバー>
<全体フォーマット>Detailing oil painting of
<主題>The great white castle on deep forest landscape
<英霊>by CASPAR DAVID FRIEDRICH and CLAUDE LORRAIN,
<全体の補足> perfect lighting, golden hour,
<フレーバー> taken with Canon 5D Mk4

古き偉大なるものを呼べ
AI魔術の詠唱には、第二音節〜第三音節に古き偉大なるものの御名を入れると、精度が安定する。ダヴィンチとかレンブラントのようなトップ英霊か、カラヴァッジオのような、いまだ忘れ去られぬ古きものの名だ。
基本的には、風景画を描くときには風景画家の御名を、人物画を描くときには人物画家の御名を詠唱に織り込めば精度が高まる。

なお、ここで召喚されるのは、ダヴィンチ本人ではなく、「ダヴィンチ的なるものを体現した何か」だと思った方がいい。
AIが学習したのは、「ダヴィンチという単語と紐づいた画像群」にすぎない。そこにはダヴィンチの弟子や、ダヴィンチの影響を受けた作品、ダヴィンチの実家、ダヴィンチと比較された作品の成分も混ざっている為だ。
「ダリ作のポートレート」と詠唱すると、ダリ本人がやってくる!
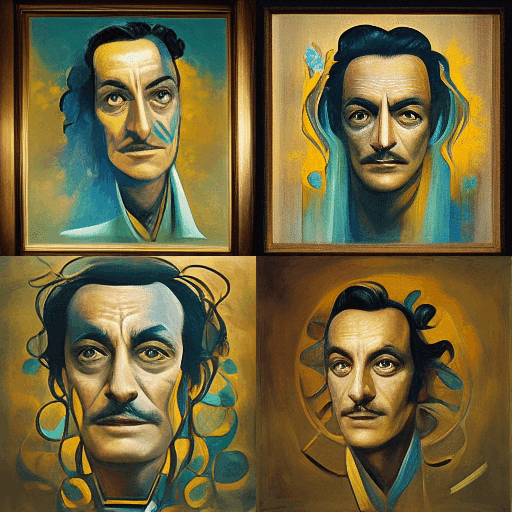
これは「Salvador Dalí」のベクトル空間に、ダリ本人のノリノリのパフォーマンス写真や自画像がいっぱい含まれるためだ。このように、我々は限度でAIと会話をしているのではない。言語を通じて間接的にAIにベクトルのパラメーターをわたしている…という意識が大事。
ちなみに英霊や精霊には地域・知名度補正がかかる。日本の英霊の御名を唱えても、西洋の魔術基盤の下では制御しにくい。知名度補正的にはHokusai級の大英霊でないと、なかなか安定しない。
同じ「landscape painting of forests」の詠唱でも、作者を変えるだけでこれくらい変わる。


個人的には、複数の英霊を合祀しするのをオススメする。いわゆる複合英霊だ。同種の属性をもつ英霊をミックスすれば、表現が安定する。逆に異なる属性を持つ英霊をミックスすれば、不安定化するが表現がブレンドされる。
下図は、上図で例にあげたボッシュの絵に、別の作家を複合したものだ。ボッシュ特有のこんもりしたオブジェクト感を維持しながら、まったく異なる画風になったことがわかる。

現代のアーティスト名を単独使用するのは、できるだけ避けたほうがいいかなと思う。基本的に画家の名前を入れるときには、複数いれるか、死後70年経った人の名前をメインし、特定個人の画風に依存しすぎたプロンプトを作らないほうがよいと思う。
法律的というより感情や仁義的なトラブルに巻き込まれるかもしれない。(著作権法は原則としては、個々の作品そのものに付与され、スタイルやアイデアやコンセプトは、単独では著作権法の保護の対象にはならないため)。
リスク回避を優先する人は「ルネッサンス」とか「ロココ」とか時代やムーブメントを丸ごと召喚するとよい。
この辺は、たぶん近い未来にマナーになる気がする。
実在する俳優や政治家や有名人の名前は絶対にいれるな!
人間の画像の安定化ノウハウとして、「実材するセレブの名前をいれる」というものがある。だが絶対に、絶対に、やらないほうがいい。
これは禁呪と考えた方がよい。
即死級の恐ろしい事例を、dicordのタイムラインで目撃したことがある。
誰かが「ハリウッド女優」と「囚われた姫騎士の写真」的フレーズを合成し、画像を作ろうとしていた。たぶん本人は悪意なく、「囚われた姫騎士的なにか」な作品クオリティをあげたかったのだろう。そのために、何気なく「ハリウッド女優」の名前をいれたのだと思う。
ところがAIは、いきなり「フォトリアルなオッパイポロリの姫騎士的なにか、しかも顔はハリウッド女優」を出力したのだ!!
事故ではあるのだろうけど、かなりヤバい画像だ。
その画像はうっかり作った誰かが消したか、通報を受けた運営が消して事なきを得た。おそらく悪意なき、不幸な事故だったのだと思う。
でも、もしこの画像が世に出ていたら…それは立派なフェイクポルノになってしまう。拡散していたら、賠償額まったなしの大惨事だ。
有名人を素体にした人体錬成には、そういう一発即死リスクがある。いまのAIの挙動では、自分が意図しなくても実在人物のNOT SAFE画像が突然錬成されうる。有名人の名前が含まれるプロンプト文は、軽々しく作らない方がいいと思う。

とにかく「実在する人間の顔面が形成されうる実名入りのプロンプト」は絶対に作らない方がよい。これから、そういう事故や事件が多発するはずなので、先に強く注意喚起しておくしだい。
AIの根源を理解しよう
以下、もうちょっと突っ込んだテクニカルな話。
このMidJourneyやDALL-E、Stable Diffusionといった画像生成手法は、Clip Guidedという技術をもとにしている。この仕組みを理解していると、文章のベクトルをイメージしやすい。
Clipは、画像と文字を「相互に比較可能なベクトル」に変換するAIだ。もうちょい柔らかくいうと、「この画像と文字のペアの一致度はどれくらいか?」をスコアで計測するAIとも言える。
現状の画像生成はこのClipを使って、「文字」と「絵」の距離が小さくなるように画像を生成する。
AIは、「ペアになる画像と文字」を何億個もトレーニングして作られている。つまり「ネットの画像と、それにつけられたキャプション」でトレーニングされている。
このためclip型の画像生成は、「ユーザーからキャプションを受け取り、そのキャプションとペアになりそうな画像」を生成しようとする。この基本ルールを理解すると、画像錬成の精度が大きくがある。
欲しい画像を出すには、「自分の欲しい画像が、美術館サイトやECサイト、写真サイトにあるとき、どのようなキャプションが付いてそうか?」を想像して、それにあう文章を考えればいいからだ。
前述の「基本構文」などは、まさにそれに近い構造でできている。
<全体のフォーマット><主題><主題の補足><作者><全体の補足><フレーバー>
油彩画「ひまわりのある風景」(ゴッホ作)。真赤な太陽と情熱的な色合い、強い筆致。… といった書き方は、美術館や美術オークションカタログの記載にとても近い。
もっと慣れてくると、さらに特殊な記法(ベクトルの重みを直接注入する)もあるが、それ上級魔術なのでまた別のお話。
ベクトルの直接注入記法の例
oil painting::1 landscape with sunflower::1 by Vincent van Gogh::0.25 water color ::-0.25
ほかにもノイズや原画を使った誘導や、インペイント(修正補完)、拡大、縮小、複合AI、フォトショやBlender素材への転用…などのネタは色々あるけれど…長くなりすぎるので割愛。
それでは皆さん、用法要領をまもって楽しい魔術ライフを!

おまけ、神秘は秘匿せよ…?
オカルティズムは隠秘学と書くが、魔術とはつまり「プロセスを隠蔽してアウトプットだけを開示する」技術体系と考えてよい。つまり魔術の考えでは、こういうったノウハウは独り占めしてこそ価値や権力性が生まれる。
「神秘は秘匿されるべし」というやつだ。
だが、時代は21世紀。インターネット時代において、情報の拡散は不可逆かつ高速になった。隠匿した神秘など、数日後には誰かがネットで無料でバラまいてしまう。もはや、情報を独占することは現実的ではない。
で、あるならば定期的に情報を公開していき、知を束ねることで魔術の深奥たる根源にたどり着くべきなのかな…と考える。
prompt に関しては、以下にDALL-E Prompt Bookをカンニングペーパーがある。これを読めば、必要な基礎単語はすぐにわかると思う。
なお、個別のAIのクセ、呪文を暗記することは、あまり意味がない。カンニングペーパーをみればOKだからだ。
真に覚えるべきノウハウは、「新しいブラックボックス技術に遭遇したとき、如何に短時間で挙動の仮説をたて、暫定的に制御下におくか?」だとおもおう。このテクニックの再現性こそが重要だ思う。
メカのスケッチとか
AIに描かせた、「新しい時代の到来を祝福するメチャクチャ太った猫の神聖で素晴らしい油絵」#dalle2 pic.twitter.com/oybOQFxM3k
— 深津 貴之 / THE GUILD / note.com (@fladdict) July 3, 2022
技術的に理解したりコードに触ってみたい人
しっかり仕組みから勉強した人は、以下を一読しよう。
根本のコードを読みたいひとは、Latente Diffusion ModelかGlide X3を調べよう。
この記事を3日ぐらい推敲して、typemoon 世界と頑張って整合性をとっているるうちに、 @shi3z さんに先に記事だされてしまった。メッチャくやしい
いいなと思ったら応援しよう!
