
15章 RNN:IMDb映画レビューの感情分析に落とし穴が・・・

はじめに
シリーズ「Python機械学習プログラミング」の紹介
本シリーズは書籍「Python機械学習プログラミング PyTorch & scikit-learn編」(初版第1刷)に関する記事を取り扱います。
この書籍のよいところは、Pythonのコードを動かしたり、アルゴリズムの説明を読み、ときに数式を確認して、包括的に機械学習を学ぶことができることです。
Pythonで機械学習を学びたい方におすすめです!
この記事では、この書籍のことを「テキスト」と呼びます。
記事の内容
この記事は「第15章 系列データのモデル化-リカレントニューラルネットワーク」の「15.3.1 プロジェクト1:IMDb映画レビューの感情分析」を実施する際に、IMDb映画レビューデータ感情分析で遭遇するつまずきの対処方法を取り上げています。
具体的には、以下の点を紹介します。
torchtextのインストール
IMDb映画レビューデータセットのラベルの変換
テスト処理のエラー
モデル訓練の処理時間
15章のダイジェスト
15章では、リカレントニューラルネットワーク(RNN)にチャレンジします。
RNNは系列データと呼ばれる「順序に意味があるデータ」を取り扱います。系列データは例えば、文章データ、DNA配列データ、株価データ、音声データです。
まずは、系列データとRNNモデルの理論的な基礎を図解などで学びます。
続いて、次の2つのケースについて、RNNを実装します。
1. プロジェクト1:IMDb映画レビューの感情分析
2. プロジェクト2:文字レベルの言語モデルをPyTorchで実装(ジュール・ヴェルヌの『神秘の島』を利用)
なお、この章で扱う文章データは「英語」です。日本語を取り扱う際の処理、たとえば形態素解析などは取り扱っていません。
IMDb映画レビューデータを用いた感情分析処理を動かす!
1. IMDb映画レビューデータセットによる感情分析の概要
IMDbは映画やテレビ番組などに関する情報を集めたデータベースであり、Internet Movie Databaseの頭文字をとって呼ばれています。
データベースにはキャスト、作品の概要、評価、レビューなどが含まれています。
以下はIMDbサイトのリンクです。
IMDb映画レビューデータセットは、IMDbの情報を加工して機械学習に使いやすくしたデータセットです。
このデータセットの提供サイトのリンクを置いておきます。
テキストによると、このデータセットの特徴は次のようになります。
①映画に対する「肯定的(ポジティブ)」と「否定的(ネガティブ)」の二値分類ラベルと、②映画レビュー文章(text)で構成される。
肯定的(ポジティブ)は星6個以上、否定的(ネガティブ)は星5個以下を意味する。
訓練データ25,000個、テストデータ25,000個に区分済みである。
このデータセットを利用する感情分析は、映画レビュー文章から、レビュー者が映画に対して、「好き(肯定的)」・「嫌い(否定的)」のいずれを評価したのか、を予測する機械学習モデルを構築して実現します。
PyTorchのnn.Moduleクラスを利用してLSTM型のリカレント層をもつモデルを構築します。
レビュー文章は単語の並び順に意味がある「系列データ(シーケンス)」です。
文章を読み進めて次々と出現する単語を理解するときには、それよりも前に出現した単語を記憶して、単語間の相互作用を踏まえて解釈することにより、各単語や文章の内容を把握できます。
LSTM(Long Short-Term Memory)は長短期記憶を担う機能があり、長期(長文)の系列データに適しています。
ニューラルネットワーク(NN)、リカレントニューラルネットワーク(RNN)、LSTMの概要に関しては、次のサイトがわかりやすかったです。ありがとうございました!
2. torchtextのインストール(落とし穴①)
IMDb映画レビューデータセットを取得するために、テキストでは torchtext を使います。
ここで落とし穴①に嵌まりました。
この torchtext に仕様変更が入って、使い方が大幅に変わっていたのです。
仕様変更の情報については、このサイトが参考になりました。ありがとうございました!
torchtextのバージョンの推移を追います。
・テキスト執筆時のバージョン:0.10.0
・大幅な仕様変更のバージョン:0.12
・本稿執筆時の最新バージョン:0.14.1
最新バージョンをインストールする際には、torchtextに加えて、torchdataのインストールが必要です。torchdataをインストールしないと、テキストのコード実行時にtorchdata未存在のエラーが発生します。
■ torchtextとtorchdataをインストールする
Anacondaの場合、次のコマンドでインストールします。
# コマンドプロンプト等でのインストール
conda install -c pytorch torchtext
conda install -c pytorch torchdata
# Jupyter Notebookでのインストール
echo y|conda install -c pytorch torchtext
echo y|conda install -c pytorch torchdataバージョンは次のとおりです。
・torchtext : 0.14.1
・torchdata : 0.5.1
Anaconda公式サイトに掲載のtorchtextインストール方法のリンクを貼っておきます。
3. IMDb映画レビューデータセットのラベルの変換(落とし穴②)
テキストのデータ準備作業の手順3-Aでは、データセットの「肯定的(ポジティブ)」と「否定的(ネガティブ)」のラベルの値を、「肯定的=1」、「否定的=0」に変換します。
具体的には、データセットのラベル値が「'pos'の場合1に変換、これ以外の場合0に変換」するコードになっています。
ここで落とし穴②に嵌まりました。
データセットのラベル値が'pos'・'neg'になっていないのです!
したがって、テキストのコードでは変換後のラベル値がすべて0になってしまいます!
ひとまず、torchtextのIMDBクラスを使って取得した訓練データ(train_dataset)の中身を見てみましょう。
次のサイトでtorchtextで取得したIMDbデータセットの rowデータの閲覧方法を知りました。Thank you very much !!!
次のコードを実行して、データセットの内容を表示します。
# train_datasetの1件目からラベルと文章を表示する
from torchtext.datasets import IMDB
train_dataset = IMDB(split='train')
for label, line in train_dataset:
print(f'Label : {label}')
print(f'line : {line[:56]}')
break
出力イメージ
Label : 1
line : I rented I AM CURIOUS-YELLOW from my video store becauseラベルの値は1です。
では、データセットのデータ仕様はどうなっているのでしょう。
PyTorch公式サイトで調べてみます。
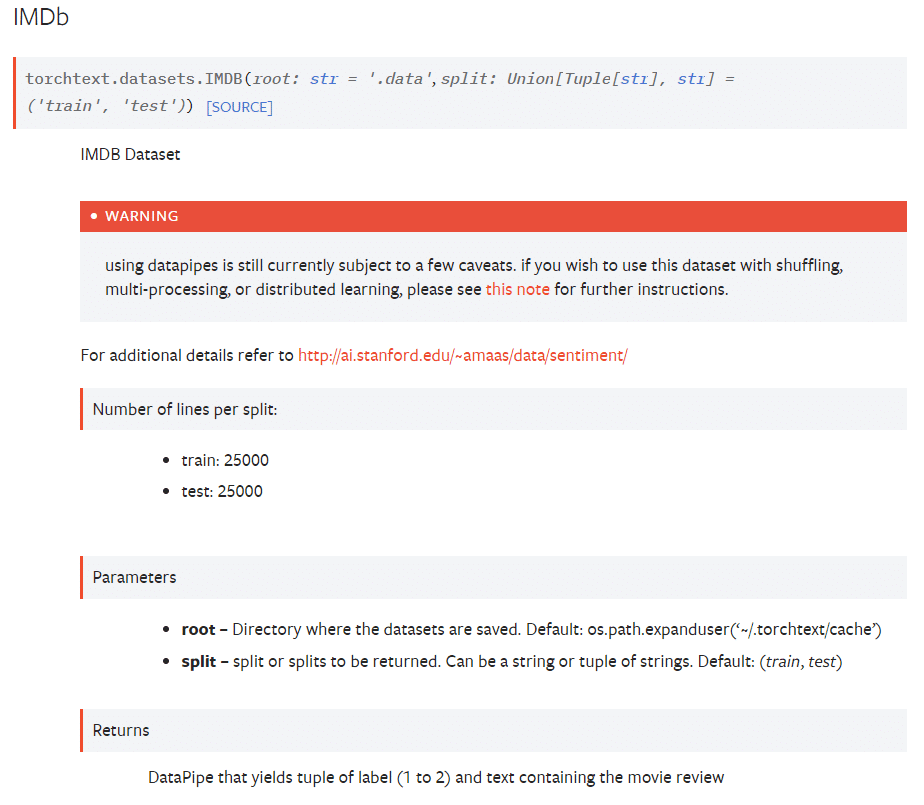
Returns(返り値)には次のような記載があります。
DataPipe that yields tuple of label (1 to 2) and text containing the movie review
(Goolge翻訳)
ラベル (1 ~ 2) と映画レビューを含むテキストのタプルを生成する DataPipe
ラベルの値は1と2です。ちょっとスッキリしましたね。
しかし、ラベル値1と2の内容は記載されていません!
どっちが肯定的でどっちが否定的なの???
ネットで調べてみたものの、値の内容の情報を得ることができませんでした。
奥の手を使います。
実はテキスト8章でIMDbデータセットを取得し、ラベル整形済み(肯定的=1、否定的=0)のCSVファイルをローカルに保存しています。
ちなみに、8章のデータセット取得時にもドタバタ劇が発生しました!
ぜひ過去の記事をご覧ください。
先程、データセットの1件を表示しました。このデータはラベル1で「I rented I AM CURIOUS-YELLOW」から始まる文章でした。
この内容を保存済みのCSVファイルで確認してみます。
すると、ラベルは0(=否定的)でした。
よって、datatextのIMDBクラスで取得したデータのラベルは、1=否定的、2=肯定的となります。
■ テキストのコードを変更する
では、手順3-Aの変換関数の変更を行いましょう。
変更後のコードサンプル(例)は次のとおりです。
# 感情分析-前処理 手順3-A:変換関数を定義【変更版】
text_pipeline = lambda x: [vocab[token] for token in tokenizer(x)]
label_pipeline = lambda x: 1. if x == 2 else 0. # 変更箇所
# label_pipeline = lambda x: 1. if x == 'pos' else 0. # 変更前4. テスト処理のエラー(落とし穴③)
感情分析の最後のコード「10エポックの訓練を行った後、このモデルをテストデータで評価する」の実行時に次のエラーが発生しました。
これが落とし穴③です!

TypeError: MapperIterDataPipe instance doesn't have valid length
長さ(length)に問題があるようですが、エラーメッセージの内容はまったく意味不明です。。。
さまざまな試行錯誤の末、データセットの長さを取得する処理に問題があることが分かりました。
以下のサンプルコードの実行結果を見ていきましょう。
まず、訓練データセットと検証データセットは正常にlengthを取得できます。
# 訓練データセットと検証データセットのlength取得
print(len(train_dl.dataset))
print(len(valid_dl.dataset))
出力イメージ
20000
5000一方で、テストデータセットのlength取得では、先程のエラーと同じエラーが発生します。
# テストデータセットのlength取得
print(len(test_dl.dataset))
訓練/検証データセットはOKで、テストデータセットはNGとなる真の原因は把握しないことにします(難解なので)。
ただ、データ準備作業の手順1で、random_splitにより訓練データセットを分割してtrain_datasetとvalid_datasetを生成する処理をする際に、「list関数」でリスト型に変換していることが、訓練・検証データセットでエラーが発生しない要因のようです。
以下のサンプルコードで、試してみましょう。
# list()で挟んでみる
print(len(list(train_dl.dataset)))
print(len(list(valid_dl.dataset)))
print(len(list(test_dl.dataset)))
出力イメージ
20000
5000
25000うまくいきそうです。
■ テキストのコードを変更する
ではテキストのコードを変更しましょう。
evaluate関数を変更することにします。
これ以外にも変更方法はあり、例えば、test_datasetをリストに変換する方法が考えられます。
変更後のコードサンプルを添えておきます。
# 感情分析-evaluate関数【変更版】
def evaluate(dataloader):
model.eval()
total_acc, total_loss = 0, 0
with torch.no_grad():
for text_batch, label_batch, lengths in dataloader:
pred = model(text_batch, lengths)[:, 0]
loss = loss_fn(pred, label_batch)
total_acc += \
((pred>=0.5).float() == label_batch).float().sum().item()
total_loss += loss.item()*label_batch.size(0)
# 変更後のコード dataloader.datasetをlist関数で囲った
return total_acc/len(list(dataloader.dataset)),\
total_loss/len(list(dataloader.dataset))
# 変更前のコード
# return total_acc/len(dataloader.dataset),\
# total_loss/len(dataloader.dataset)5. モデル訓練の処理時間
テキストでは、訓練データセット20,000個、検証データセット5,000個を用いて、感情分析のモデルを10エポックにわたって訓練します。
GPUを搭載していないパソコンで処理したところ、370分かかりました。
6時間を超えました!
寝てる間に処理しておきましょう!
次の図は訓練結果です。
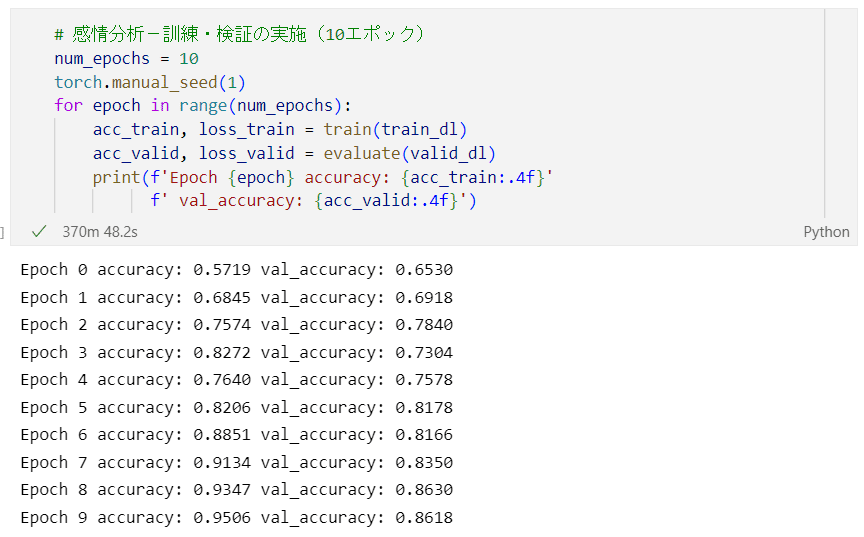
10エポック目の正解率は、訓練データセットで95%、検証データセットで86%です。過学習をしている感じがします。
テキストの正解率は、訓練データセットで98%、検証データセットで87%です。
テキストよりも正解率が低いのはなぜでしょう・・・。
最後に、25,000個のテストデータによる評価結果を置いておきます。

正解率は85.93%。テキストの85.98%をわずかに下回りました。
モデルを保存しておきましょう。
# 感情分析-訓練したモデルの保存
path = 'models/imdb-rnn.ph'
torch.save(model, path)■ 長時間かかる処理のために
パソコンがスリープしないように、「電源とスリープの設定」を変えておきましょう。
また、電源はコンセントに挿しておきましょう。
【電源とスリープの設定】
Windowsのスタートメニューから設定(歯車)をクリック
→「Windowsの設定」画面で「電源とスリープ」を検索
→「電源とスリープ」画面で「次の時間が経過後、PCをスリープ状態にする(電源に接続時)」を「なし」に設定
6. おまけ:双方向RNN
感情分析の最後のコード「双方向RNN」モデルの訓練を行ってみました。
nn.LSTM の引数 bidirectional=True を設定します。
エビデンスを残していないのですが、メモの扱いで記録します。
(モデルは保存して残してあります)
10エポックの訓練に約800分の処理時間を要した。
正解率は10エポック全ての値が、訓練データ:0.4968、検証データ:0.5128になった。
テストデータの正解率は0.5000になった。
性能はあまりよくないようです。
コード入力ミスが有ったのかもしれませんし、もしかすると効果を得られにくいアルゴリズムだったのかもしれません。
まとめ
今回は、IMDb映画レビューデータセットによる感情分析について、PyTorchでリカレントニューラルネットワークを実装しました。
実装の過程では3点の大きな課題が発生し、解消に取り組みました。
PyTorchのデータセット関連処理について、torchdata ライブラリの開発が逐次、進められています。
現時点で torchdata はベータ版の扱いとなっており、新機能の開発が活発に行われているとのことです。
torchdata開発プロジェクトの進展によって、データセット取得時に用いる torchtext と torchdata は、テキスト執筆時から大幅に仕様が変わっていました。
この仕様変更の影響で、テキストのコードがそのまま使えず、エラーを生じさせる結果になっていました。
現在進行形のライブラリ開発に追随することは決して簡単なことでないことを実感いたしました。
# 今日の一句
print('章が進むにつれて、落とし穴が増えている気がする')楽しくPython機械学習プログラミングを学びましょう!
おまけ数式
noteでは数式記法を利用できます。
今回はリカレントニューラルネットワークのRNN層について、時間ステップ$${t}$$での隠れユニット活性化の式を紹介します。
$$
\boldsymbol{h}^{(t)} = \sigma_h \left(\boldsymbol{z}^{(t)}_h \right) = \sigma_h \left(\boldsymbol{W}_{xh} \boldsymbol{x}^{(t)} + \boldsymbol{W}_{hh} \boldsymbol{h}^{(t-1)} + \boldsymbol{b}_h \right)
$$
$${\boldsymbol{z}_h}$$は隠れ層の総入力(事前活性化)、$${\boldsymbol{W}_{xh}}$$は入力$${\boldsymbol{x}^{(t)}}$$と隠れ層$${\boldsymbol{h}}$$の重み行列、$${\boldsymbol{W}_{hh}}$$はリカレントエッジに関連付けられた重み行列、$${\boldsymbol{b}_h}$$は隠れユニットのバイアスベクトルです。
おわりに
AI・機械学習の学習でおすすめの書籍を紹介いたします。
「統計検定2級対応 統計学基礎」
データサイエンスの基礎を補強する上で、確率・統計の知識は欠かせないものになっています。
統計分野の資格の代表格が「統計検定」。
大学基礎課程レベルである「2級」から学んでみませんか?
2級を足がかりにして、上位の準1級、1級に次々とチャレンジしていくのもいいと思います。
私はこの公式テキストと公式問題集を利用して、2級を(ぎりぎり)取得しました。
試験の詳しい内容は、統計検定のホームページでご確認下さい。
なお、最近、公式問題集が刷新されました。CBT方式に対応したとのこと。
最後まで読んでくださり、ありがとうございました。