
19章 DQN:最終回は突然に、DQNでCartPole!

はじめに
シリーズ「Python機械学習プログラミング」の紹介
本シリーズは書籍「Python機械学習プログラミング PyTorch & scikit-learn編」(初版第1刷)に関する記事を取り扱います。
この書籍のよいところは、Pythonのコードを動かしたり、アルゴリズムの説明を読み、ときに数式を確認して、包括的に機械学習を学ぶことができることです。
Pythonで機械学習を学びたい方におすすめです!
この記事では、この書籍のことを「テキスト」と呼びます。
記事の内容
この記事は「第19章 複雑な環境での意思決定-強化学習」の「19.4 最初の強化学習アルゴリズムを実装する」のCartPoleの深層Q学習を紹介します。
深層Q学習は、Q学習アルゴリズムをディープニューラルネットワークで実装した「深層Qネットワーク」による学習アルゴリズムです。
深層Qネットワーク(Deep Q-Network)はDQNと略されます。
今回はGPU非搭載のパソコンを使いました。
19章のダイジェスト
19章では、強化学習に挑戦します。
強化学習の概念を伝えるのはかなり難しいです。
そこで先人の知恵を拝借して、わかりやすいサイトを紹介します!
興味のある方は是非ご参照ください。
テキストでは、まず、理論的概念を学びます。
マルコフ決定過程、エージェント・報酬、利得・ポリシー・価値関数、ベルマン方程式による動的計画法、モンテカルロ法、TD学習(SARSA/Q学習)を怒濤の数式で。
次に、OpenAI Gymツールキットを利用して、2つの実装を行います。
グリッドワールド問題(注1)をQ学習で解く
(注1)5行x6列のマス目の上でトラップを避けてゴールドを探すゲームCartPole-v1(注2)を深層Q学習(DQN)で解く
(注2)棒が倒れないようにバランスをとるゲーム
機械学習のDQNは凄い!
1. CartPoleの紹介
「CartPole-v1」はOpenAI Gymツールキットに含まれるゲームです。
揺れる棒が倒れないようにカートを左右に動かすものです。
次のOpenAIのサイトの紹介画像でイメージをつかめるでしょう。
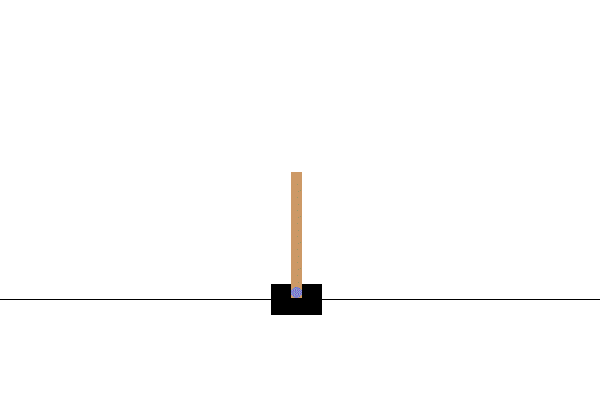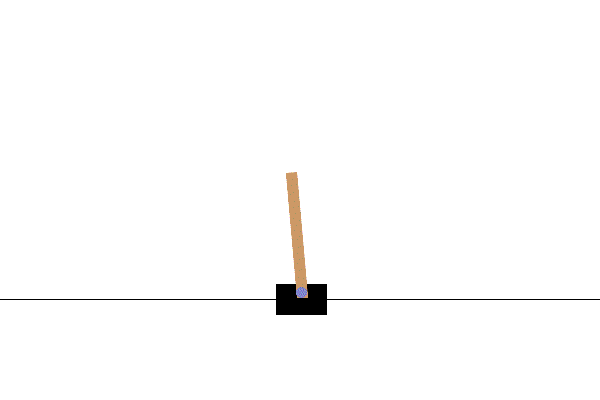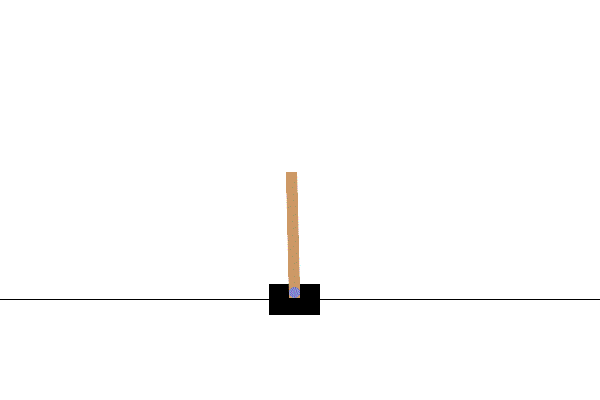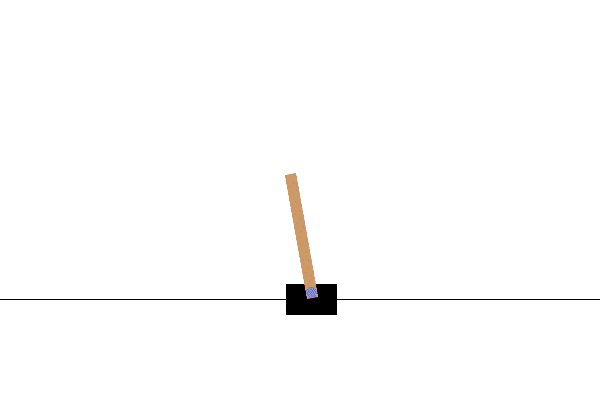
(OpenAIのCartPole公式サイトより引用)
CartPole公式サイトのリンクです。
今回のミッションは、深層Q学習を用いて棒を倒さないような行動選択、つまり、棒の状況を把握してカートを右に動かすか左に動かすかを、コンピュータが自ら学習することです。
2. CartPoleを深層Q学習する
学習・モデルの概要
OpenAI Gymのバージョン : 0.20.0(テキストで使用する古いバージョン)
エピソード数 : 1000(テキストでは200)
報酬 : 終了までのステップ数(上限500)
バッチサイズ : 32
リプレイメモリサイズ:最大10000(テキストでは2000)
PyTorchで深層Qネットワークを構成
入力特徴量:状態$${s}$$
モデル(pytorch.nn.Sequential)
Linear(in=状態空間の形状 : 4, out=256)
ReLU
Linear(in=256, out=128)
ReLU
Linear(in=128, out=64)
ReLU
Linear(in=64, out=行動空間の形状 : 2)
損失関数 : nn.MSELoss
オプティマイザ : optim.Adam
学習の推移
1000エピソードの処理時間は 30.6分 です。
学習の推移を見ると、面白い結果になったことが分かります。
上の図はエピソードごとの報酬、下の図はステップごとの損失値(MSE)です。

最初から400エピソードあたりまでは、上限の500ステップまで到達できるようになっており、学習の効果があるように見えます。
一方で、400エピソード以降、突然、数十ステップで棒が倒れてしまうようになり、うまく学習できない状態になっています。
不思議ですね。謎の現象です。
ちなみに、この学習の前に、実験的に1000エピソードを実施した結果は次のようになりました。

こちらの方もかなり荒れています。
200エピソードくらいまでに順調に進んだ学習が、その後パタリと効果を上げることができなくなっています。
600エピソードあたりから、また効果のある学習が進みます。
しかし、950エピソードあたりでまた、ピタリと効果が上がらなくなりました。
単純にエピソード数を増やせば性能が上がる、というわけでは無さそうです。
ハイパーパラメータのチューニングを行うことで、もう少し学習の効果が上昇するのかもしれません。
3. 深層Q学習の過程を動画にする
CartPoleの動きを動画にして可視化しましょう。
テキストのサンプルコードは、学習処理中にアニメを一部表示してくれるものの、処理後にはアニメを再生することができません。
そこで、学習中に動画をキャプチャすることに取り組みます。
【謝辞 SpecialThanks】
次のサイトのお世話になりました。ありがとうございました!
動画を保存するコード
gym.wrappers.Monitorを利用して動画ファイル(.mp4)を保存します。
なお、Gym 0.20以降、このMonitorの利用が非推奨になったようです。
次のサイトで代替策の検討がなされています。
テキストのサンプルコードに対して、「### 動画作成用」の3箇所を変更しました。
# テキストサンプルコード main.py の抜粋
# 全体的な設定
EPISODES = 1000 # 初期値は200
batch_size = 32
init_replay_memory_size = 500 # 初期値は500
### 動画作成用:保存フォルダ名
savepath = "./保存フォルダ名/"
if __name__ == '__main__':
env = gym.make('CartPole-v1')
### 動画作成用:50エピソードごとに動画を保存
env = wrappers.Monitor(env, savepath+'movie/',
video_callable=(lambda ep: ep % 50 == 0),
force=True)
agent = DQNAgent(env)
state = env.reset()
state = np.reshape(state, [1, agent.state_size])
# リプレイメモリの設定
for i in range(init_replay_memory_size):
action = agent.choose_action(state)
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, agent.state_size])
agent.remember(Transition(state, action, reward,
next_state, done))
if done:
state = env.reset()
state = np.reshape(state, [1, agent.state_size])
else:
state = next_state
### 動画作成用:「リプレイメモリの設定」で中断したエピソードを完結させる処理
while not done:
action = agent.choose_action(state)
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, agent.state_size])
agent.remember(Transition(state, action, reward,
next_state, done))
state = next_state
total_rewards, losses = [], []
start_time = time.time()
for e in range(EPISODES):
state = env.reset()
if e % 10 == 0:
env.render()
state = np.reshape(state, [1, agent.state_size])
for i in range(500): # 初期値は500
action = agent.choose_action(state)
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, agent.state_size])
agent.remember(Transition(state, action, reward,
next_state, done))
state = next_state
if e % 10 == 0:
env.render()
if done:
total_rewards.append(i)
print(f'Episode: {e}/{EPISODES}, Total reward: {i}, '
f'Time: {(time.time() - start_time)/60:.2f} min')
break
loss = agent.replay(batch_size)
losses.append(loss)
# total_rewardsをcsvファイルに出力
with open(savepath + 'q-learning-history.csv', 'w') as f:
print('total_rewards', file=f)
for row in total_rewards:
print(row, file=f)
# lossesをcsvファイルに出力
with open(savepath + 'q-learning-history_losses.csv', 'w') as f:
print('losses', file=f)
for row in losses:
print(row, file=f)
plot_learning_history(total_rewards, losses)このコードは、「リプレイメモリの設定で実行するエピソードを含めて」50エピソードごとに動画を保存します。
深層Q学習で実施するエピソードの番号とは一致しない点が心残りです。。。
動画のサンプル ~エージェントの成長~
保存できたエピソードの中で最長時間のものを紹介します。
これは、300~350エピソードの間の1エピソードです。
noteに直接動画を投稿できないので、Twitterの投稿動画をご覧ください。
深層Q学習:DQNでコンピュータがCartPole-v1を操っています!#Python #機械学習 #強化学習 #深層Q学習 #DQN #gym pic.twitter.com/pvsCjrKawS
— ネイピアDS (@ArtHappyMuseum) February 10, 2023
コンピュータが行動することによって棒の状態を把握し、棒が倒れない時間の長さ(ステップの多さ)に連動した報酬の最大化を目指して自ら学習し、棒の最適な制御を身につけるのです。
なにかすごいことが起きています。感動しました。
深層強化学習は、自動車やロボットの自動運転に活用されているそうです。
未来を感じる技術です。
ところで、Twitterの動画投稿の注意点です。
保存した動画ファイルをTwitterにアップロードするとエラーになり、投稿できませんでした。
次の動画変換サイトで、フレームレートを 30(FPS)に変換し、movフォーマット形式で保存したところ、Twitterに投稿できるようになりました。
まとめ
今回は、OpenAI Gymを利用してCartPoleの「深層Q学習」(DQN)に取り組みました。
テキストの【最後の実装】をやり遂げたのです。
今回をもってテキストの実践に関する記事は終わります。
長い連載となりました。
最後の記事までお付き合いいただき、ありがとうございました。
この連載が、テキスト「Python機械学習プログラミング PyTorch & scikit-learn 編」を学ぶ皆様と並走する「仲間」になれたなら、嬉しいです!
# 今日の一句
print('Python機械学習プログラミングの振り返り記事を書きます!')楽しくPython機械学習プログラミングを学びましょう!
おまけ数式
noteでは数式記法を利用できます。
今回はQ学習で行動価値関数を更新する式を紹介します。
$$
Q(S_t,A_t) \leftarrow Q(S_t,A_t) +\alpha[R_{t+1}+\gamma \displaystyle\max_a Q(S_{t+1},a)-Q(S_t,A_t)]
$$
$${Q(S_t,A_t)}$$は時間ステップ$${t}$$のとき、状態$${S_t}$$と行動$${A_t}$$の各ペアに対する行動価値関数であり、表形式の2次元配列です。
右辺第2項はQ値の更新差分であり、次に取りうる最善の行動から得られる価値です。
$${\alpha}$$は学習率を表すハイパーパラメータ、$${R_{t+1}}$$は状態$${S_t}$$で行動$${A_t}$$をしたときの報酬、$${\gamma}$$は割引率、$${\displaystyle\max_a Q(S_{t+1},a)}$$は次の状態$${S_{t+1}}$$の最善の行動で得られる価値です。
おわりに
AI・機械学習の学習でおすすめの書籍を紹介いたします。
「日本統計学会公式認定 統計検定2級 公式問題集[CBT対応版]」
新しい連載テーマを「統計の学び」にする予定です!現在検討中です!
新連載では「統計検定2級 公式問題集[CBT対応版]」をテキストにします!
統計学に興味をお持ちの方と一緒に学習を進める気持ちで書きます!
データサイエンスの基礎固めとして、また、データ分析の手始めとして、確率・統計を学んでみませんか?
最後まで読んでくださり、ありがとうございました。