
17章 GAN:遂にパソコンが画像を創造しだした!?

はじめに
シリーズ「Python機械学習プログラミング」の紹介
本シリーズは書籍「Python機械学習プログラミング PyTorch & scikit-learn編」(初版第1刷)に関する記事を取り扱います。
この書籍のよいところは、Pythonのコードを動かしたり、アルゴリズムの説明を読み、ときに数式を確認して、包括的に機械学習を学ぶことができることです。
Pythonで機械学習を学びたい方におすすめです!
この記事では、この書籍のことを「テキスト」と呼びます。
記事の内容
この記事は「第17章 新しいデータの合成-敵対的生成ネットワーク」の3種類のGAN(敵対的生成ネットワーク)が自動生成した手書き数字画像を比べてみます。すべてGoogle Colab環境のGPUを使用しました。
17章のダイジェスト
17章では、敵対的生成ネットワーク(GAN)を学び、新しい画像の生成に取り組みます。
まずは、GANの仕組みを図解などを用いて理解します。
画像生成器が生み出した新しい画像(つまりフェイク画像)を画像識別器が本物か偽物かを判定します。生成器が本物そっくりさんを生み出すように学習し、識別器が本物そっくりな偽物を摘発するように学習して、お互いに切磋琢磨しながら、生成器が生み出す画像の精度向上を目指します。
続いて、MNIST手書き数字をお手本にして、PyTorchで次の3つのアーキテクチャを実装して、新しい手書き数字画像を生成します。
①vanilla GAN:オリジナルバージョンの敵対的生成ネットワーク
②DCGAN:ディープ畳み込みGAN
③WGAN:ワッサースタインGAN
本章のコードはGPU利用を前提としており、テキストにはGoogle Colabの使い方のレクチャーが掲載されています。
手書き数字風の画像を次々と生み出す!
1. 訓練の概要
MNIST手書き数字の訓練データ60,000個を学習した画像生成器が、新しい手書き風画像を生成します。
画像を描くAIの初歩的なモデルになります。
訓練は100エポック実施します。
学習に用いる「MNIST手書き数字」は、11章、12章、13章、14章でも利用したおなじみのデータセットです。
画像データは28x28のグレースケールです。
MNIST手書き数字データベースの公式サイトはこちらです。
過去の記事でも取り扱いました。よかったら覗いていってください!
17章ではGoogle Colabをフル活用します。
テキストの17.2.1を参考にして、Google ColabとGoogleドライブを使えるように設定しましょう。
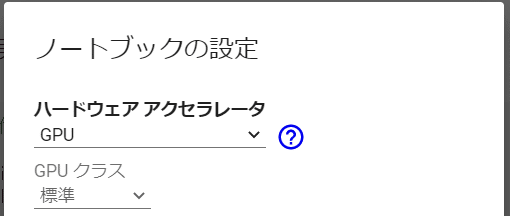
特に重要なGoogle ColabのGPU設定は次のようにします。
メニュー>ランタイム
>ランタイムのタイプを変更>ノートブックの設定
>ハードウェアアクセラレータ>GPU
2. vanilla GANバージョン
モデルの概要
最初のアーキテクチャはvanilla GANと呼ばれる、GANが登場したときのオリジナルに近いモデルです。
全結合層をベースにした生成器と識別器のモデルです。
# 生成器ネットワークモデル gen_model
Sequential(
(fc_g0): Linear(in_features=20, out_features=100, bias=True)
(relu_g0): LeakyReLU(negative_slope=0.01)
(fc_g1): Linear(in_features=100, out_features=784, bias=True)
(tanh_g): Tanh()
)# 識別器ネットワークモデル disc_model
Sequential(
(fc_d0): Linear(in_features=784, out_features=100, bias=False)
(relu_d0): LeakyReLU(negative_slope=0.01)
(dropout): Dropout(p=0.5, inplace=False)
(fc_d1): Linear(in_features=100, out_features=1, bias=True)
(Sigmoid): Sigmoid()
)訓練処理
訓練時間は約22分。すんなりと処理が進行した印象です。
生成した画像のサンプル
砂嵐のような粗さで、ぼんやりした輪郭の画像になりました。
数字だと言われたら数字に見える、そんなレベルです。

3. DCGANバージョン
モデルの概要
DCGANのモデルは、転置畳み込み層(ConvTranspose2d)とバッチ正規化(BatchNorm2d)を取り入れたものです。
# 生成器ネットワークモデル gen_model
Sequential(
(0): ConvTranspose2d(100, 128, kernel_size=(4, 4), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): LeakyReLU(negative_slope=0.2)
(3): ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): LeakyReLU(negative_slope=0.2)
(6): ConvTranspose2d(64, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): LeakyReLU(negative_slope=0.2)
(9): ConvTranspose2d(32, 1, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): Tanh()
)# 識別器ネットワークモデル disc_model
Discriminator(
(network): Sequential(
(0): Conv2d(1, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2)
(2): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(6): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2)
(8): Conv2d(128, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(9): Sigmoid()
)
)訓練処理
訓練時間は36分17秒。まずまずの速度で処理が進行した印象です。
生成した画像のサンプル
100エポック時の画像はかなり手書き数字に近いように見えます。
8,1,2,7,7でしょうか。

4. WGANバージョン
モデルの概要
WGANのモデルは、EM距離と勾配ペナルティを取り入れています。
# 生成器ネットワークモデル gen_model
Sequential(
(0): ConvTranspose2d(100, 128, kernel_size=(4, 4), stride=(1, 1), bias=False)
(1): InstanceNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(2): LeakyReLU(negative_slope=0.2)
(3): ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(4): InstanceNorm2d(64, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(5): LeakyReLU(negative_slope=0.2)
(6): ConvTranspose2d(64, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): InstanceNorm2d(32, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(8): LeakyReLU(negative_slope=0.2)
(9): ConvTranspose2d(32, 1, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): Tanh()
)# 識別器ネットワークモデル disc_model
DiscriminatorWGAN(
(network): Sequential(
(0): Conv2d(1, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2)
(2): Conv2d(32, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): InstanceNorm2d(64, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(4): LeakyReLU(negative_slope=0.2)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(6): InstanceNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(7): LeakyReLU(negative_slope=0.2)
(8): Conv2d(128, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(9): Sigmoid()
)
)訓練処理
訓練時間は2時間50分43秒。
かなり時間がかかりました。
Google Colabの90分対策が必要です。
生成した画像のサンプル
はっきりと手書き数字に見えるレベルに至ったように感じます。
7,8,3,1,2でしょう。
この技術の延長線上には、コンピュータが自ら絵画や写真を描く「AI画伯」があるのかもしれません。

5. 訓練データの保存
モデルの保存
訓練したモデルを生成器と識別器の別に保存しておきましょう。
次のコードは、WGANの生成器/識別器をGoogleドライブに保存するサンプルコードです。
# WGAN 手書き文字画像生成:モデルの保存
# generator
path_g = '/content/drive/MyDrive/保存先フォルダ/wgan_gen.pt'
torch.save(gen_model, path_g)
# discriminator
path_d = '/content/drive/MyDrive/保存先フォルダ/wgan_disc.pt'
torch.save(disc_model, path_d)サンプル画像データの保存
生成器が生み出した画像データはリスト形式で次の変数に保持されています。
・vanilla GAN:epoch_samples
・DCGAN:epoch_samples
・WGAN:epoch_samples_wgan
このリストデータを保存しておけば、いつでもテキストのコードを用いて、手書き数字画像を再表示できます。
次のコードは、pickleを用いて、WGANの画像リストデータをバイナリでGoogleドライブにて保存/再読み込みするサンプルコードです。
# WGAN 手書き文字画像生成:画像サンプルlistの保存
import pickle
path_p = '/content/drive/MyDrive/保存先フォルダ/wgan_image_sample_list.pkl'
with open(path_p, 'wb') as f:
pickle.dump(epoch_samples_wgan, f)# DCGAN 手書き文字画像生成:画像サンプルlistの読み込み
import pickle
path_p = '/content/drive/MyDrive/保存先フォルダ/wgan_image_sample_list.pkl'
with open(path_p, 'rb') as f:
new_epoch_samples_wgan = pickle.load(f)まとめ
今回は、Google Colab環境でGPUを利用して、GANによる画像生成タスクに取り組みました。
何か新しいものを生み出すタスクを実装して「これぞAI」と言えるようなモデル作りを体感できた気がします。
一方で、前回のテキスト生成、今回の画像生成を体験してみて、コスト・時間をかければ本物そっくりの「フェイクを生み出せてしまう」という事実に、今までよりも深くタッチできた気がします。
漠然とした不安のようなものが残りました。
# 今日の一句
print('「この文章は偽物である」は本物の文章か?')楽しくPython機械学習プログラミングを学びましょう!
おまけ数式
noteでは数式記法を利用できます。
今回はEM距離の式を紹介します。
EM距離は、分布$${P(x)}$$と$${Q(x)}$$の非類似度を計測する方法の1つです。
$$
EM(P,Q)=\displaystyle \inf_{\gamma \in \prod(P,Q)} E_{(u,v) \in \gamma}(||u-v||)
$$
$${\prod(P,Q)}$$は周辺分布が$${P}$$と$${Q}$$になる全ての同時分布の集合です。
$${\gamma(u,v)}$$は分布$${u}$$から分布$${v}$$への輸送計画(変換方法)です。
おわりに
AI・機械学習の学習でおすすめの書籍を紹介いたします。
「AI・データサイエンスのための 図解でわかる数学プログラミング」
ビジネスの現場では今後、数学的知識の必要度が高くなると言われています。
この書籍は、図解によって数学的な考え方を直感的に説明し、Pythonのコードを動かしてみて計算を体感することを目的に書かれています。
カバーする領域は、確率統計、機械学習、数理最適化、数値シミュレーション、深層学習です。
なんとか数学的な知識を獲得したくて、現在、ゆっくり読んでいます。
Pythonコードを動かして数式の気持ちに迫ってみたいです。
特に、テキストの範囲外である数理最適化・数値シミュレーションに取り組もうと思っています。
最後まで読んでくださり、ありがとうございました。