
「スモールデータ解析と機械学習」を寄り道写経 ~ 第5章「分類問題と不均衡データ問題」

第5章「分類問題と不均衡データ問題」
書籍の著者 藤原幸一 先生
この記事は、テキスト「スモールデータ解析と機械学習」第5章「分類問題と不均衡データ問題」の通称「寄り道写経」を取り扱います。
テキスト5.18節「ケーススタディ」の寄り道写経に取り組みます。
ではテキストを開いてスモールデータの旅に出発です🚀
このシリーズは書籍「スモールデータ解析と機械学習」(オーム社、「テキスト」と呼びます)の機械学習の理論・数式とPythonプログラムを参考にしながら、テキストにはプログラムの紹介が無いけれども気になったテーマ、または、テキストのプログラム以外の方法を試したいテーマを「実験的」にPythonコード化する寄り道写経ドキュメンタリーです。
はじめに
テキスト「スモールデータ解析と機械学習」のご紹介
テキストは、2022年2月に発売され、スモールデータと呼ばれる小さなサンプルサイズのデータを用いた機械学習の取り組み方について、理論(数式)とPythonサンプルプログラムを提案する素晴らしい実用書です。
引用表記
この記事は、出典に記載の書籍に掲載された文章及びコードを引用し、適宜、掲載文章とコードを改変して書いています。
【出典】
「スモールデータ解析と機械学習」第1版第1刷、著者 藤原幸一、オーム社
記事中のイラストは、「かわいいフリー素材集いらすとや」さんのイラストをお借りしています。
ありがとうございます!
第5章 分類問題と不均衡データ問題
主に Jupyter Notebook 形式(拡張子 .ipynb)でPythonコードを書きます。
この記事は 5.18節「ケーススタディ」にフォーカスして寄り道写経いたします。
ケーススタディは、4つの不均衡データを用いて、ランダムフォレスト、AdaBoost、SMOTE、ADASYN、RUSBoostによるモデルを構築し、性能評価を実視します。
不均衡データの機械学習に慣れるのに最適であり、とても魅力的な題材なのです!
寄り道ポイントです。
・取得したオープンデータの手作業に関するガイダンス
・学習時に発生するエラーの回避策
・学習の一括実行化

データ取得のガイダンス
テキストは、以下の4つのオープンデータを用います。
・Covertype
・Abalone
・CTG
・Pageblocks
読者自身でWebサイトのデータを取得する必要があり、少々ハードルの高い作業を伴います。
このパートでは、4つのデータをテキストのプログラム5.3「データセットの構築」で読み込めるファイルに仕上げる作業を書きます。
■ 圧縮ファイルの解凍ツールの確保
ZIPファイル、gzファイル、Zファイルを扱える解凍ツールを揃えてください。
Windows11の例です。
・ZIPファイルはエクスプローラーで解凍できます。
・gzファイル、Zファイル は「圧縮・解凍ソフト 7-Zip」で解凍できます。
(エクスプローラーで解凍できなかったです)
■ Covertypeのファイル作成手順
①次のUCIサイトからデータをダウンロードします
https://archive.ics.uci.edu/dataset/31/covertype
②covertype.zipファイルを解凍してcovtype.data.gzファイルを取り出します
③covtype.data.gzファイルを解凍してcovtype.dataファイルを取り出します
④covtype.dataのファイル名をcovertype.csvに変更します
■ Abaloneのファイル作成手順
①次のUCIサイトからデータをダウンロードします
https://archive.ics.uci.edu/dataset/1/abalone
②abalone.zipファイルを解凍してabalone.dataファイルを取り出します
③abalone.dataのファイル名をabalone.csvに変更します
■ CTGのファイル作成手順
①次のUCIサイトからデータをダウンロードします
https://archive.ics.uci.edu/dataset/193/cardiotocography
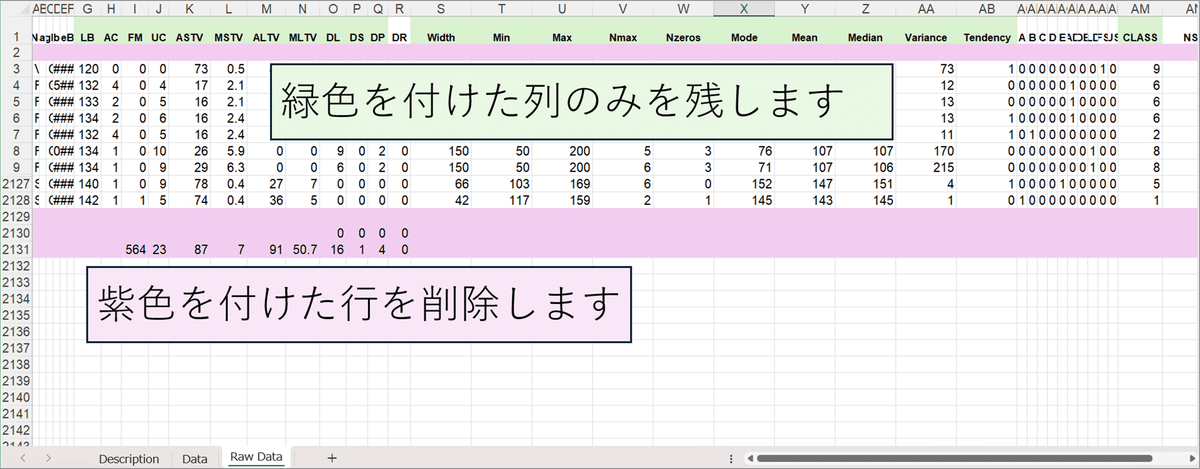
②cardiotocography.zipファイルを解凍してCTG.xlsファイルを取り出します③CTG.xlsをEXCELで開いて「Raw Data」シートの不要データを削除し、ファイル名をctg.csvにして「CSV UFT-8(コンマ区切り)」で保存します
【残す列】(22列)
LB, AC, FM, UC, DL, DS, DP, ASTV, MSTV, ALTV, MLTV, Width, Min, Max, Nmax, Nzeros, Mode, Mean, Median, Variance, Tendency, CLASS
【削除する行】(4行削除)
2行目、2129行目、2130行目、2131行目
Excelファイルの加工手順を図示します。
■ Pageblocksのファイル作成手順
①次のUCIサイト(Page Blocks Classification)からをダウンロードします
https://archive.ics.uci.edu/dataset/78/page+blocks+classification
②page+blocks+classification.zipファイルを解凍してpage-blocks.data.Zファイルを取り出します
③page-blocks.data.Zファイルを解凍してpage-blocks.dataファイルを取り出します
④page-blocks.dataのファイル名をpageblocks.csv(半角空白区切りのデータ)に変更します
■ 注意事項
各ファイルの最終列が目的変数になります。
おまけ1
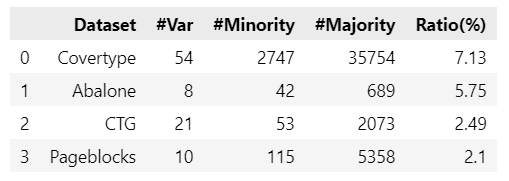
テキストの表5.1「データセットのプロフィール」を作成するコードを書きます。
テキストのプログラム5.3「データセットの構築」の実行後に動かしてみてください。
### 表5.1 データセットのプロフィールの作成
## 設定
# データフレームをリスト化
df_dic = {'Covertype': df1, 'Abalone': df4, 'CTG': df3, 'Pageblocks': df2}
# プロフィール表の列名をリスト化
col_names = ['Dataset', '#Var', '#Minority', '#Majority', 'Ratio(%)']
## データ作成処理
# プロフィール用データフレームの初期化
dataset_prof_df = pd.DataFrame(columns=col_names)
# 4つのDatasetについてプロフィール作成処理を繰り返し実施
for name, data in df_dic.items():
# Datasetの行数、列数の取得
num_row, num_col = data.shape
# 多数クラス件数, 少数クラス件数の算出
num_majority, num_minority = data.iloc[:, -1].value_counts().sort_index()
# 少数クラス比率(%)の算出
ratio = round(num_minority / num_row * 100, 2)
# 説明変数件数, 少数クラス件数, 多数クラス件数, 少数クラス比率を一時df化
tmp_df = pd.DataFrame([name, num_col-1, num_minority, num_majority, ratio],
index=col_names).T
# プロフィール用データフレームに一時dfを結合
dataset_prof_df = pd.concat([dataset_prof_df, tmp_df], axis=0)
# indexの再設定
dataset_prof_df.reset_index(drop=True, inplace=True)
# 完成したプロフィール用データフレームの表示
display(dataset_prof_df)【実行結果】
Ratioは目的変数の少数クラスの割合を示す「不均衡度$${r}$$」です。
4つのデータは不均衡度$${r<0.1}$$であり、不均衡データです。

学習時のエラー対策
私は3つのエラーに遭遇しました。
何となくコードをイジって(試行錯誤とも言う)、エラーを潰しました。
① 謎の「0」エラー
メッセージだけでは原因が分からない謎の0エラーです。
【エラーメッセージ(一部分)】

【原因】
目的変数 Y の学習データ・テストデータに問題がありそう、と考えて、試行錯誤を重ねた結果、対策案を思いつきました。
【対策案】
プログラム5.5「RFによる学習と性能検証」の Y_train、Y_test に代入する値に「.values」を追加します。
# 学習と検証の繰り返し
for train_index, test_index in kf.split(X):
# trainデータとなる行のみ抽出します
X_train = X.iloc[train_index, :].values
# trainデータの正解ラベル
Y_train = Y.iloc[train_index].values # ★ .valuesを追加
# testデータの行を抽出します
X_test = X.iloc[test_index, :].values
# testデータの正解ラベル
Y_test = Y.iloc[test_index].values # ★ .valuesを追加
② データ「Covertype」、アルゴリズム「AdaBoost」の学習時のエラー
AdaBoostの学習データ X に NaNが含まれている、と言われています。
見に覚えのないNaN・・・。
他のデータ・アルゴリズムでも発生するかもしれません。
【エラーメッセージ(一部分)】
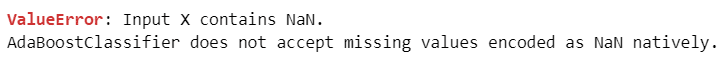
ValueError: Input X contains NaN. AdaBoostClassifier does not accept missing values encoded as NaN natively.
【原因】
データ標準化の際に、分母の不偏標準偏差が0になることで、データ標準化処理後の X の値がおかしくなっているようでした。
【対策案】
不偏標準偏差が0にならないように、テキストオリジナルコードファイル「scale.py」を変更します。
具体的には、scale.py の以下の「★」マークの行を追加します。
< scale.py の抜粋>
def autoscale(X):
meanX = np.mean(X, axis=0)
stdX = np.std(X, ddof=1, axis=0)
stdX[stdX == 0] = 10e-20 # ★追加
Xscale = (X - meanX) / stdX
return Xscale, meanX, stdXdef scaling(x, meanX, stdX):
stdX[stdX == 0] = 10e-20 # ★追加
xscale = (x - meanX) / stdX
return xscale.astype(float)
def rescaling(xscale, meanX, stdX):
stdX[stdX == 0] = 10e-20 # ★追加
x = np.multiply(stdX, xscale) + meanX
return x
③ データ「Abalone」を用いた学習時のエラー
ゼロ割り算エラーです。
エラー発生箇所が特定でき、かつ、エラー原因を想像しやすいです。
【エラーメッセージ】

【原因】
Abaloneデータの推論時、テキストオリジナルコードファイル「func5.py」の「calc_score関数」にて、「TP+FP=0」になり、PPVの計算処理でゼロ割り算エラーが発生したものと思われます。
【対策案】
テキストオリジナルコードファイル「func5.py」の「calc_score関数」を変更します。
学習処理時に PPV の計算は不要なので、PPVの行をコメントアウトします。
# プログラム5.2 分類問題の性能
# 感度、特異度の計算 ゼロ割り算を考慮してif文で場合分け
if (TP+FN != 0) and (FP+TN !=0):
sensitivity = TP / (TP + FN) # 感度・再現率
specificity = TN / (FP + TN) # 特異度
# PPV = TP / (TP + FP) # 適合率(precision) # ★コメントアウト
学習の一括実行化
プログラム5.4「データの読込」からプログラム5.9「ADASYNによるオーバーサンプリング」までを合体して、全データ・全アルゴリズムを一括して実行できるコードを書きます。
テキストのプログラムを引用させていただいています。
まずはインポートです。
「テキストオリジナルコード」はオーム社HPからダウンロードできる書籍掲載のプログラムであり、書籍購入者のみ利用できるとのことです。
### インポート
# 数値計算
import pandas as pd
import numpy as np
# 機械学習
from sklearn.model_selection import KFold
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from imblearn.ensemble import RUSBoostClassifier
from imblearn.over_sampling import ADASYN, SMOTE
# テキストオリジナルコード
from func5 import calc_score
from scale import autoscale, scaling
# ユーティリティ
import time
# ワーニング表示の抑制
import warnings
warnings.simplefilter('ignore')続いて自動化のための設定値を作ります。
### 設定 ★自動化するための各種値の設定
# datasetのファイル名の辞書化
datasets = {'Covertype': 'cover_type_im.csv', 'Abalone': 'abalone_im.csv',
'CTG': 'CTG_im.csv', 'Pageblocks': 'pageblocks_im.csv'}
# 学習器の辞書化
clfs = {'RF': RandomForestClassifier(), 'AdaBoost': AdaBoostClassifier(),
'SMOTE': DecisionTreeClassifier(), 'ADASYN': DecisionTreeClassifier(),
'RUSBoost': RUSBoostClassifier()}
# オーバーサンプリング器のリスト化
ovss = [None, None, SMOTE(random_state=42), ADASYN(random_state=42), None]そしてファイル読み込み関数と学習関数を作成します。
### 関数定義 ★書籍のコードを関数化
## ファイル読み込み関数の定義 ※フォルダ名は環境に合わせて設定してください
def read_dataset_file(file_name):
df = pd.read_csv('./data/' + file_name)
return df
## 学習関数の定義
def exec_train(df, clf, ovs_method):
## 初期値設定
senses, specs, g_means = [], [], []
## モデルインスタンスの生成
ovs = ovs_method
model = clf
## データセットの準備
# 学習用データと検証用データを10回ランダムに組み替え
kf = KFold(n_splits=10, shuffle=True, random_state=42)
Y = df.iloc[:, -1] # 正解ラベル
X = df.drop(df.columns[-1], axis=1) # 正解ラベル以外
## 学習と検証の繰り返し(10回)
for train_index, test_index in kf.split(X):
## 学習データと検証データの作成
# trainデータの行を抽出します
X_train = X.iloc[train_index, :].values
# trainデータの正解ラベル
Y_train = Y.iloc[train_index].values # ★ .valuesを追加
# testデータの行を抽出します
X_test = X.iloc[test_index, :].values
# testデータの正解ラベル
Y_test = Y.iloc[test_index].values # ★ .valuesを追加
# オーバーサンプリング(必要なモデルのみ実施)
if ovs != None:
X_train, Y_train = ovs.fit_resample(X_train, Y_train)
# データの標準化
X_train, mean, std = autoscale(X_train)
X_test = scaling(X_test, mean, std)
## 学習の実行
model.fit(X_train, Y_train)
## 検証
# 検証データのラベルの予測
Y_pred = model.predict(X_test)
# 性能評価
sense, spec, g_mean = calc_score(Y_pred, Y_test)
senses.append(sense)
specs.append(spec)
g_means.append(g_mean)
return np.array([senses, specs, g_means])これで準備は整いました。
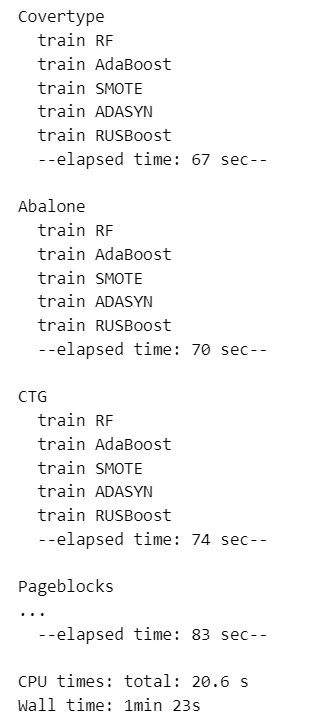
学習処理を実行しましょう。
%%time
### 全モデルの学習の実行 ★書籍のコードを自動化
# 評価指標を格納するリストの初期化
train_results = []
# 処理時間の計測開始
start_time = time.time()
# データセットごとに学習処理を繰り返し実行
for dataset_name, filename in datasets.items():
print(f'{dataset_name}')
# データセットの読み込み
df = read_dataset_file(filename)
# モデルごとに学習処理を繰り返し実行
for i, (model_name, clf) in enumerate(clfs.items()):
print(f' train {model_name}')
# 学習の実行
result = exec_train(df, clf, ovss[i])
# 評価指標をリストに追加
train_results.append(result)
print(f' --elapsed time: {int(time.time() - start_time)} sec--\n')【実行結果】
処理時間は 1分23秒です。
データ Covertype の処理時間が一番長いです。
最後にモデル学習結果である表5.2「モデル学習結果」を作成します。
### 表5.2 モデル学習結果の作成 ★書籍に無いコード
## データの準備
# 評価指標リストをnumpy配列化
train_results = np.array(train_results)
# 評価指標の平均値と標準偏差算出
means = train_results.mean(axis=2).reshape(4, 5, 3)
stds = train_results.std(axis=2).reshape(4, 5, 3)
## データフレームの作成
# モデル学習結果データフレームの初期化
train_result_df = pd.DataFrame()
# データセットごとに繰り返し処理
for i, dataset_name in enumerate(datasets.keys()): # 4
# 一時格納dfの準備
tmp_merge = pd.DataFrame()
# モデルごとに繰り返し処理
for j, clf_name in enumerate(clfs.keys()): # 5
# データセット×モデルの評価指標の平均値・標準偏差を一時格納dfに結合
tmp_mean = pd.DataFrame(means[i, j, :])
tmp_std = pd.DataFrame(stds[i, j, :])
tmp_merge = pd.concat([tmp_merge, tmp_mean, tmp_std], axis=1)
# データセットの各モデルの評価指標をモデル学習結果データフレームに結合
train_result_df = pd.concat([train_result_df, tmp_merge], axis=0)
## データフレームの修飾
# データセット名、評価指標名の列を追加してインデックス化
train_result_df.insert(0, '評価指標', ['感度', '特異度', 'G-mean'] * 4)
train_result_df.insert(0, 'Dataset', np.repeat(list(datasets.keys()), 3))
train_result_df.set_index(['Dataset', '評価指標'], inplace=True)
# 列名の設定
train_result_df.columns = [np.repeat(list(clfs.keys()), 2),
np.tile(['平均', 'std'], 5)]
## 完成したモデル学習結果データフレームの表示
display(train_result_df.round(2))【実行結果】
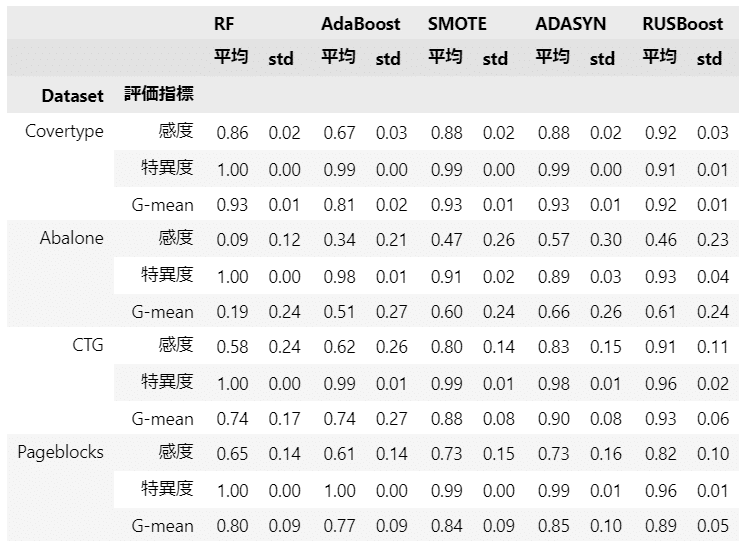
簡単なまとめです!
【テキストの精度と比較して】
テキストの結果とほぼ同じなのはデータ Covertype だけです(汗)
Abalone は ADASYN と RUSBoost がテキストと違っています。
CTG はテキストよりもかなり良い精度になりました。
Pageblocks も概ねテキストより良い精度になりました。
テキストの精度と異なる結果になったのは何故でしょう・・・
気になります。
【不均衡データの機械学習について】
決定木のバギング&ブースティングアルゴリズムや、データの割増し/削除による均衡化の措置が、不均衡データの機械学習モデルの精度向上をもたらすことを体感できました。
また、データによっては、決定木、オーバーサンプリング/アンダーサンプリング実施による精度向上効果に差が出ることも分かりました。
第5章の寄り道写経は以上です。

シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。