
SnowflakeでStreamlit使ってみた

分析屋の中田(ナカタ)です。
SnowflakeでStreamlitを試してみました。
Streamlitとは
Streamlit | Snowflake Documentation
読み方はそのままで「ストリームリット」です。
Webアプリ開発用の、オープンソースのPythonフレームワークです。
Web系の言語(HTML/CSS/JavaScript)を書かずにお手軽に実装できます。
2022年にSnowflake社により約8億ドルで買収されています。
現在、Snowflake上でStreamlitを実装できるようになっています(プレビュー機能)。
今回やること
SnowflakeでStreamlitを試してみます。
サンプルコードの解釈、テーブルデータとの連携などなどを行います。
環境
Snowflakeのエディション:エンタープライズ版
クラウド:AWS(東京リージョン)
スタートラインに立つまで
空のWebアプリを作成し、エディタを開くところまで進めていきます。
Snowflakeにログインし、画面左のメニューから「Streamlit」をクリックします。
画面右上の「+ Streamlitアプリ」ボタンをクリックします。
※「いくつかの権限を付与する必要があります!」というメッセージが表示されています。
翻訳すると「権限付与していないロールではStreamlitでWebアプリを作成できないよ!」ということです。
今回は最強ロールのACCOUNT ADMINで進めていきますのでいったんスルーします。
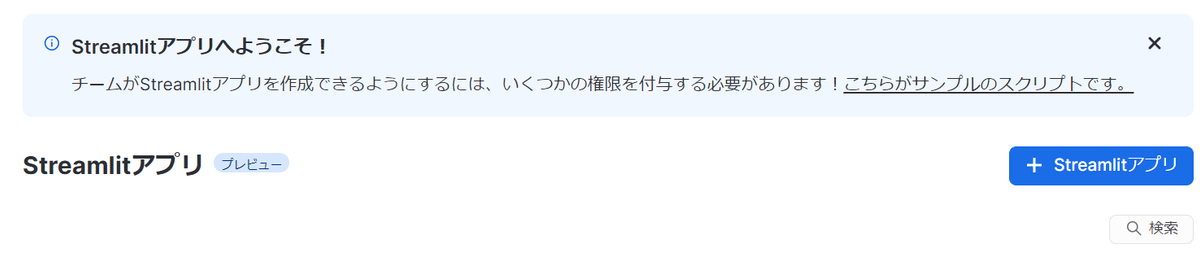
ポップアップウィンドウが表示されます。
ここでは以下の項目を指定して、「作成」ボタンをクリックします。
アプリ名:Webアプリの名称(デフォルトではアカウント名と日時が入っています。)
ウェアハウス:Webアプリを動かすためのコンピューティング環境を指定します。
アプリの場所:Webアプリの置き場(データベース名とスキーマ名)を指定します。
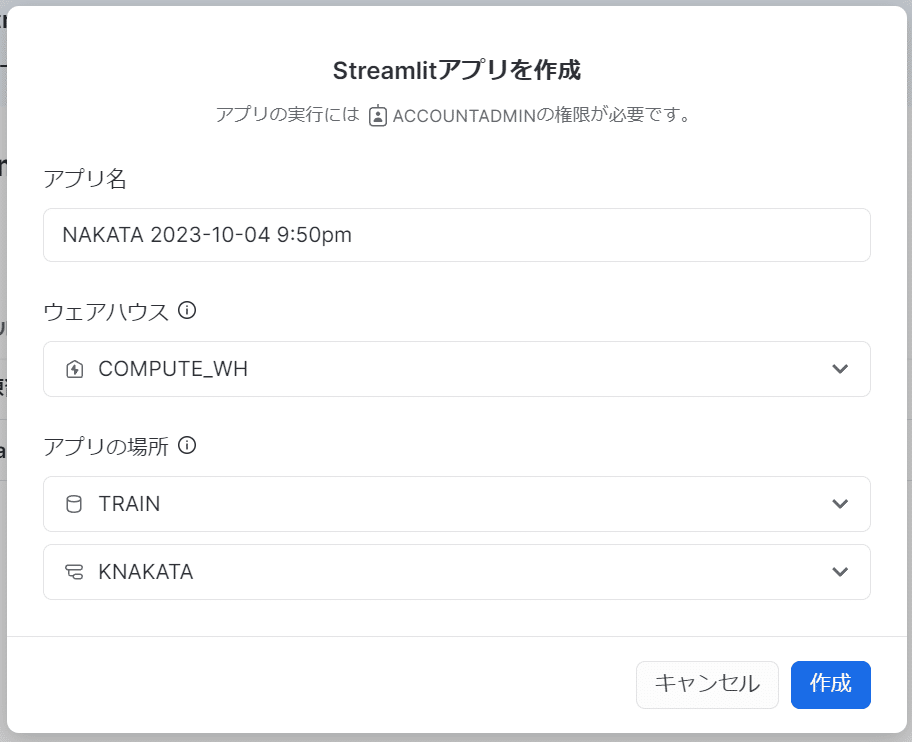
Streamlitの編集画面が表示されます。
以下の3分割の構図になっています。
左:オブジェクトブラウザ
真ん中:エディタ(サンプルコードつき)
右:プレビュー画面
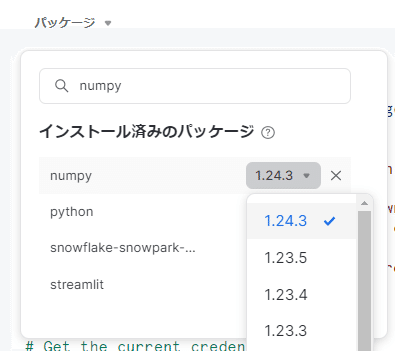
画面中央のエディタ最上部では、インストールするパッケージを指定できます。
以下の画像ではnumpyのバージョン1.24.3をインストールしています。

画面右上には「共有」「実行」ボタンがあります。
「共有」ボタンでは権限設定ができます。
ロール単位で、閲覧・編集権限を割り振りますが
現時点ではSnowflakeアカウント以外への一般公開は不可となっています。
「実行」ボタンではプレビュー画面を更新できます。
画面中央のエディタで編集しただけでは、プレビュー画面は更新されません。
サンプルコード解説
デフォルトで表示されているサンプルコードを解説していきます。
# Import python packages
import streamlit as st
from snowflake.snowpark.context import get_active_session必要なパッケージをインポートしています。
SnowParkは、Snowflake上でPythonを動かすためのパッケージです。
サンプルコードでは、get_active_session関数(後述)をインポートしています。
# Write directly to the app
st.title("Example Streamlit App :balloon:")
st.write(
"""Replace this example with your own code!
**And if you're new to Streamlit,** check
out our easy-to-follow guides at
[docs.streamlit.io](https://docs.streamlit.io).
"""
)上記のコードで、Webアプリ上に以下が表示されます。
マークダウン形式で書いたテキストを表示しています。

# Get the current credentials
session = get_active_session()現在の認証状態(セッション)を取得しています。
コード上に認証情報を直接記載せずに済むところが良きです。
# Use an interactive slider to get user input
hifives_val = st.slider(
"Number of high-fives in Q3",
min_value=0,
max_value=90,
value=60,
help="Use this to enter the number of high-fives you gave in Q3",
)以下のスライダーを表示しています。
スライダーで指定した数値を、変数hifives_valに格納しています。
どうでもいいですが「ハイタッチ」は和製英語で、英語では”High Five”らしいです。

# Create an example dataframe
# Note: this is just some dummy data, but you can easily connect to your Snowflake data
# It is also possible to query data using raw SQL using session.sql() e.g. session.sql("select * from table")
created_dataframe = session.create_dataframe(
[[50, 25, "Q1"], [20, 35, "Q2"], [hifives_val, 30, "Q3"]],
schema=["HIGH_FIVES", "FIST_BUMPS", "QUARTER"],
)適当なサンプルデータ(3行×3列)を作っています。
3行目の1列目には、先ほど作った変数hifives_valを指定しており
スライダーと連動する動的な値にしています。
# Execute the query and convert it into a Pandas dataframe
queried_data = created_dataframe.to_pandas()先ほどのサンプルデータをPandasのデータフレームに変換しています。
ちなみに、.to_pandas()を省略しても後続の処理でエラーは発生しませんでした。
もしかしたら、明示的に変換しておかないとうまくいかない場面もあるかもしれません。
# Create a simple bar chart
# See docs.streamlit.io for more types of charts
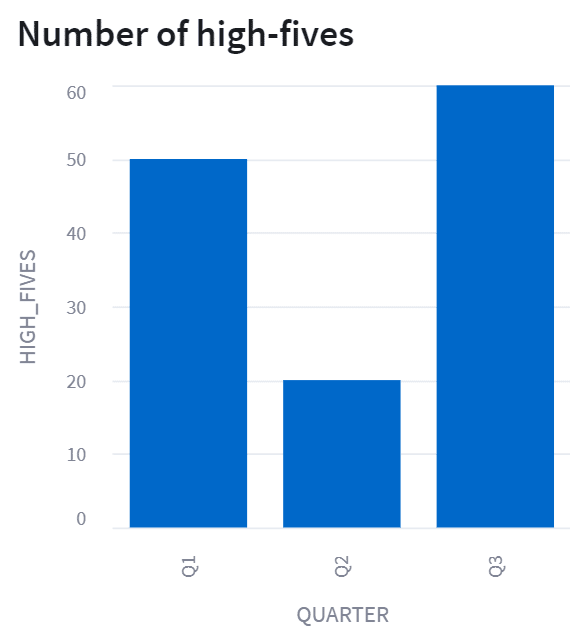
st.subheader("Number of high-fives")
st.bar_chart(data=queried_data, x="QUARTER", y="HIGH_FIVES")棒グラフが表示されました!
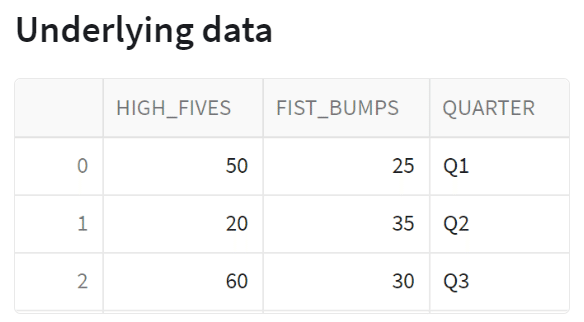
st.subheader("Underlying data")
st.dataframe(queried_data, use_container_width=True)データフレームをそのまま表形式で表示しています。
引数use_container_widthはテーブルの幅に関する設定値です。
Trueを指定すると、親コンテナの幅に合わせます。
いろいろ試してみる
Streamlitの様々なコードをサポートしているようなので試してみます。
テーブル表示
肝心のSnowflakeテーブルとの連携を行います。
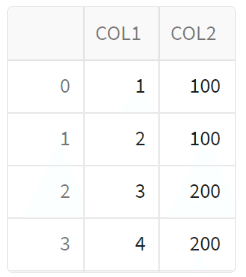
# Snowflake上のテーブルを参照
sample_tbl = session.table("TRAIN.KNAKATA.Streamlit_Sample")
st.dataframe(sample_tbl)データベース名:TRAIN
スキーマ名:KNAKATA
テーブル名:Streamlit_Sample
を上記のように指定しています。
これで表形式で画面に表示できます。
SQL文
# SQLでも実装できるぽい
sql_test = session.sql("SELECT * FROM TRAIN.KNAKATA.Streamlit_Sample").collect()
st.dataframe(sql_test)上記のようにSQL文でも実装できます。
ここでGROUP BY句を書いて集計ロジックを持たせることもできますが
以下のデメリットが考えられます。
・データ量や処理によっては、表示されるまでに時間がかかる
・文字列でSQLを記載するため、自動候補表示での補完ができない
できることなら、Snowflakeでデータマートを作ってシンプルに表示するだけの方がよさげですが
例えば以下のコードのような使い方もできます。
GROUP BYの集計軸をプルダウンから選択して、動的に変化させています。
# GROUP BY
selected_col = st.selectbox(
'集計軸を選んでね',
('col1','col2'))
sql_result = session.sql("SELECT "
+ selected_col
+ ", SUM(col2) FROM TRAIN.KNAKATA.Streamlit_Sample GROUP BY "
+ selected_col).collect()
st.dataframe(sql_result)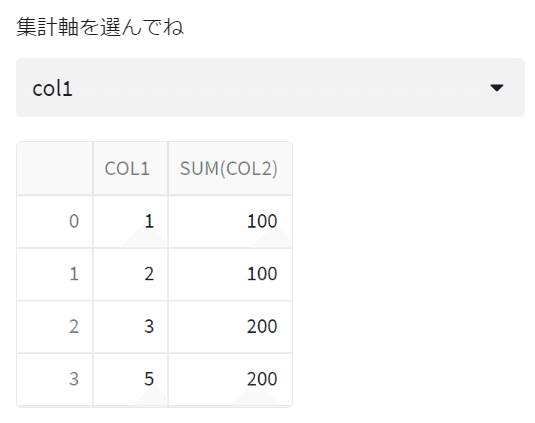
GROUP BYメソッド
agg_tbl = sample_tbl.group_by('col2').sum('col1')
st.dataframe(agg_tbl)SQLのGROUP BY句ではなく、group_byメソッドで
テーブルの結果を集約して表示することもできます。
チェックボックス
if st.checkbox('UPDATE'):
is_updated = session.sql("UPDATE TRAIN.KNAKATA.Streamlit_Sample SET col1 = 5 WHERE col1 = 4;").collect()チェックボックスを実装しています。

さらに、チェックを入れるとUPDATE文が走るようにしています。
このようにして、データを表示するだけの可視化ツールだけではなく
CRUDできるWebアプリを作ることもできます。
折れ線グラフ
# 折れ線グラフ
st.line_chart(sample_tbl)折れ線グラフも簡単に表示できました。
最後に
作成したWebアプリをSnowflake上で開くと、ウェアハウスの起動準備中はクッキーやケーキなどのイラストが表示されます。
ライ麦食パンのようなものもあります。

ここまでお読みいただき、ありがとうございました!
この記事が少しでも参考になりましたら「スキ」を押していただけると幸いです!
これまでの記事はこちら!
株式会社分析屋について
弊社が作成を行いました分析レポートを、鎌倉市観光協会様HPに掲載いただきました。
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。