
【Python】Spotify Web APIで楽曲データを分析してみる

はじめに
こんにちは、分析屋の長田です。
Spotify(定額制の音楽配信サービス)の存在は説明するまでもないとは思いますが、そんなSpotifyがWeb APIを公開していることはご存じでしょうか。
Spotifyでは楽曲ごとにさまざまな指標が数値化されていて、APIを叩いてデータを呼び出すことができます。そしてこれが結構面白いです。
そこで、今回はSpotifyの楽曲データを利用して、2000年代、2010年代、2020年代(2023年まで)の3つの年代で流行したヒット曲にどのような違いが現れるか見ていきたいと思います。
調査対象
詳細は後述しますが、楽曲データの取得は基本的にプレイリストから行います。
今回は2000年代、2020年代、2020年代のヒット曲で比較したいのですが、特に公式でそのようなプレイリストは見つからないため、誰かが作ってくれているものを探して取得します。
2000年代
2010年代
2020年代
公式ではなく何をもって100曲選んでいるか明確ではないが、中を見てみると概ね各年代のヒット曲が入っていそうなので良しとします。細かいことは気にしない。
一部Spotifyに入っていないアーティストもいるが、今回の調査対象はSpotifyに入っているアーティストのみなのでそこだけご了承願います。
事前準備
今回はPythonで実装するので、Python実行環境を用意しましょう。
また、Spotify for Developersに登録してごちゃごちゃする必要があるので、以下手順に沿って設定してください。
Spotifyのアカウントがない方はアカウントを作成しましょう。
Spotify for Developers にログインして、右上の「dashboard」からダッシュボード画面へ遷移

3.「Create app」からアプリを作成します。入力項目に沿って入力したら、「Save」で完了です。
4. 作成できたら、アプリ画面の右上の「Setting」から、Client IDとClient secretを控えておきます。

これで事前準備は完了です。
実際にAPIを叩いてみる
事前準備と各種指標の確認ができたら、データを取得するためのコードを書いていきます。
使用している言語はPython3.11です。
実装の流れはこんな感じです。
1.先ほど用意したClient IDとClient secretで認証情報を設定する
2.データを取得したい楽曲のIDをプレイリストから持ってくる
3.取得した楽曲IDを使ってSpotifyからデータを取りだす
まずはライブラリのインポートです。
spotipyは、pythonでAPIを叩くのに必要なライブラリです。
取得したデータをデータフレームで操作するため、pandasもインポートします。
残りのライブラリですが、一定時間にリクエストを送りすぎるとAPIのリクエスト制限(429 Too Many Requests)がかかってしまうので、楽曲間での待機時間を設ける必要があるため入れています。
# ライブラリのインポート
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
import time
import requests
from requests.exceptions import HTTPError
import pandas as pd認証情報を設定します。Client IDとClient secretの出番です。
# クライアントIDとクライアントシークレットを設定
client_id = 'あなたのclient_id'
client_secret = 'あなたのclient_secret'
# 認証情報を設定
client_credentials_manager = SpotifyClientCredentials(client_id=client_id, client_secret=client_secret)
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)認証ができたら、用意した年代別ヒット曲がまとまっているプレイリストから。楽曲情報を取得していきます。プレイリストを読み込む際にはプレイリストIDが必要ですが、これはURLの/playlist/と?si=の間にある文字列がそれになります。
playlist_url = 'https://open.spotify.com/playlist/6KfKvkN7YEUFTwJHkczxdb?si=5d285aa4dade4002'
playlist_id = playlist_url.split('/')[-1].split('?')[0] #プレイリストIDを取得
# プレイリストの楽曲一覧を取得
results = sp.playlist(playlist_id)取得したデータを見てみると、このように辞書型で入っています。

‘tracks’の中の’items’リストに楽曲の詳細情報が格納されているので、その中から楽曲ID、曲名、アーティスト名を取り出してそれぞれのリストに入れてデータフレーム化します。
# 楽曲のタイトル、アーティスト名、IDをリストに格納する
tracks = []
artists = []
ids = []
for item in results['tracks']['items']:
track = item['track']
tracks.append(track['name'])
ids.append(track['id'])
artists.append(', '.join([artist['name'] for artist in track['artists']]))
# データフレームを作成
id_2000s = pd.DataFrame({
'Track': tracks,
'Artist': artists,
'ID': ids
})
id_2000sid_2000sという変数に、プレイリストに入っている楽曲のID、曲名、アーティスト名を格納できました。
次に、取得したIDを使って楽曲ごとのデータを取り出します。ここでは100曲分のリクエストを送ることになり、リクエスト過多で制限がかかるので待機時間を設定しています。
# 空のリストを作成
track_list = []
# プレイリストにある100曲分のデータを取得
for i in range(100):
while True:
try:
# idをtrack_idに格納して、楽曲データを取得
track_id = id_2000s['ID'][i]
track = sp.audio_features(track_id)
break
except spotipy.SpotifyException as err:
# Spotify APIから429エラー(リクエストが多すぎる)が返された場合
if err.http_status == 429:
# 再試行までの待機時間を取得(デフォルトは1秒)
retry_after = int(err.headers.get('Retry-After', 1))
# 指定された時間だけ待機
time.sleep(retry_after)
# 取得した楽曲データをリストに格納
track_list.append(track)
# リストをデータフレームに変換
df_2000s = pd.concat([pd.DataFrame(t) for t in track_list], ignore_index=True)こんなようなデータが取得できました。(左以降見切れていますが先述した各指標データが入っています)
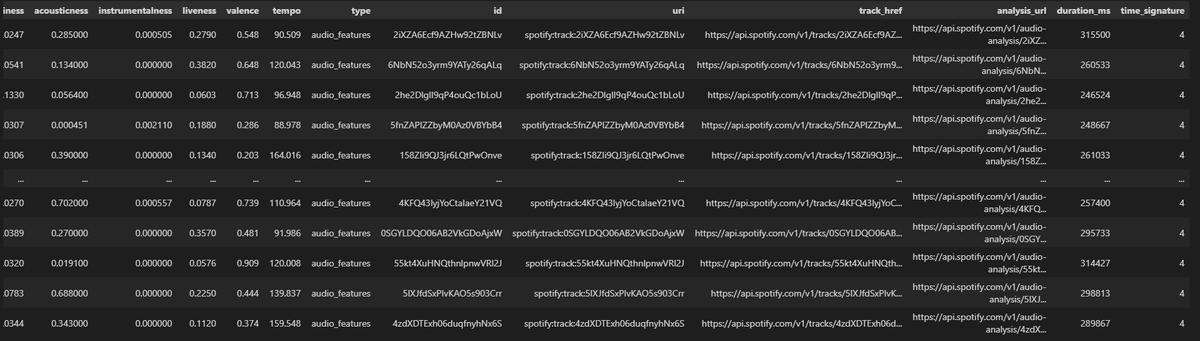
このままだとSpotifyURLなど今回使わない指標がいくつかあったり、アーティスト名や楽曲名もURLから飛ばないと確認できず、データとしてわかりにくい状態になっているので、以下のように少し調整します。
・アーティスト名と曲名を追加します。
・曲の長さ(duration_ms)がミリ秒で表示されているので、秒に直してduration_secsカラムを作ります。
・可視化する際にいらないカラムがあるので削除します。
・なんとなくアーティスト名と曲名が後ろにあるのが気持ち悪いので、前に持ってきます。
# アーティスト名、楽曲名の列を追加(id_2000sから持ってくる)
df_2000s['artist_names'] = id_2000s['Artist']
df_2000s['track_name'] = id_2000s['Track']
# duration_msをミリ秒(ms)から秒(s)に修正(小数点切り捨て)
df_2000s['duration_secs'] = df_2000s['duration_ms'] // 1000
#2.不要な元カラムを削除
df_2000s = df_2000s.drop(['type'], axis=1)
df_2000s = df_2000s.drop(['uri'], axis=1)
df_2000s = df_2000s.drop(['track_href'], axis=1)
df_2000s = df_2000s.drop(['analysis_url'], axis=1)
df_2000s = df_2000s.drop(['time_signature'], axis=1)
df_2000s = df_2000s.drop(['id'], axis=1)
df_2000s = df_2000s.drop(['duration_ms'], axis=1)
# # 順番を整理して表示
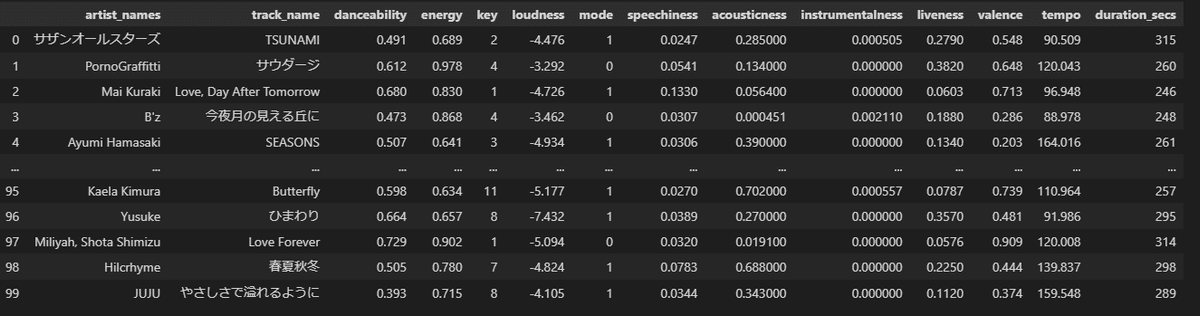
df_2000s = df_2000s[['artist_names', 'track_name', 'danceability', 'energy','key', 'loudness', 'mode','speechiness','acousticness','instrumentalness','liveness','valence','tempo','duration_secs']]
df_2000sこれで曲名、アーティスト名、各指標が揃った綺麗なデータになりました。
ここでは2000年代のプレイリストから取得しましたが、プレイリストIDだけ変えれば同様に他のプレイリストからもデータを取得できるので、2010年代、2020年代の楽曲データも同じように取り出して、年代ごとに比較してみましょう。
各指標の定義を確認
可視化する前にSpotify APIから取得できた指標の定義を確認します。
公式リファレンスを見たい方はこちら。
acousticness
アコースティック感があるかどうか。0~1の値を取り、1に近いほど楽器本来の音とのこと。
danceabillty
踊りやすさを表す。テンポや安定的なリズム、ビートの強さなどで決まるとのこと。
0~1の値を取り、1に近いほど踊りやすい曲ということでしょう。
duration_ms
曲の時間。
energy
長々書いてあるが、要はエネルギッシュさ。デスメタルは高く、バッハの前奏曲は低くなると書いてあります。0~1の値を取り、1に近いほどエネルギッシュ。
instrumentalness
インスト感。0~1の値を取るが、歌詞がある曲はほぼ0.1未満。0.5を超えるとインスト曲判定らしい。
liveness
ライブ感がどれだけあるか。0~1の値を取り、0.8以上でライブ判定らしい。ライブ音源でないと基本は0.8未満っぽい。
loudness
音量、音圧の平均値。
mode
調性のこと。マイナーコード(0)とメジャーコード(1)の2択。
speechiness
語り調の曲かどうか、話し言葉の割合から算出しているらしい。0~1の値を取り、スピーチ感の強い曲。
tempo
ざっくり言うと曲の速さ。
key
0=Cを基準とした楽曲のキー。
valence
ポジティブ度合いを測る指標。0~1の値を取り、悲観的であれば0に近く、楽観的であれば1に近い。
データを見てみる
年代ごとに各指標の平均値をまとめてみました。だいぶ簡単なものですが、以下のような感じになりました。

増加傾向
・ライブ感
・スピーチ感
・ポジティブさ
・テンポ
減少傾向
・アコースティック感
・インスト感
・秒数
横ばい
・踊りやすさ
・エネルギッシュさ
テンポが速く&秒数が短くなっているのは、サブスクの普及が大きく影響していそうです。定額聞き放題が故に、少し聴いて気に入らなければスキップされてしまうので、必然的に短時間で心を掴めるような楽曲の人気が出ているのでしょうか。SNSショート動画の普及も同じく影響を与えていそうです。
アコースティック感とインスト感が減少傾向にあるのは、ヒップホップやラップのジャンルの人気が増えてきたからでしょうか。スピーチ感が増加傾向にあることともつながります。
踊りやすさはSNSの普及から増加傾向になると思っていましたが、意外にも大きな変化はなかったです。Spotifyのアルゴリズム的な踊りやすさと、SNSユーザーが考える踊りやすさは違うのでしょう。
まとめ
今回はSpotify APIを利用して楽曲データを取得し、昨今のヒット曲の特徴を比較してみました。Spotify APIは誰でも簡単に使えて楽曲データを閲覧できる、とても面白いものなのでぜひ使ってみてください。
今回はざっくり年代別での比較でしたが、楽曲の歌詞を流行するアーティストの特徴なども見たり、2000年代以前の楽曲(Spotifyにあれば)も見てみると、より粒度の細かい分析ができるともっと面白い結果が見られるかもしれないので、またの機会にSpotify APIのお世話になろうかと思います。
ここまでお読みいただき、ありがとうございました!
この記事が少しでも参考になりましたら「スキ」を押していただけると幸いです!
株式会社分析屋について
弊社が作成を行いました分析レポートを、鎌倉市観光協会様HPに掲載いただきました。
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。