
統計検定2級に向けて、基本統計量をおさらいしよう

はじめに
分析屋の小泉と申します。
前回は統計学の勉強を始めるに当たり、その前提となる微分積分についてのお話をしました。
前回の記事はこちらです。
今回は微分積分と直接関わりはしませんが、
統計学の中でも最も初歩となるステップの1つ、基本統計量についてのお話です。
統計学をかじったことがない人でも、合計や平均は求めたことがあるはずです。
データの分析を行う上で合計と平均は特に重要な指標ですが、
他にも基本統計量と呼ばれるパラメータはいくつもあります。
今回は統計検定2級に向けて、基本統計量の求め方を今一度まとめてみようと思います。
「もう知ってるよ!」という内容もあるかもしれませんが、
意外と忘れていたり、今後の検定・推定に繋がる重要な式もあったり、きっと損はしないはずです。
また、今後内容が深くなるにつれて、数式も増えてきます。
今回の記事で提示する数式を用いて、公式への当てはめから実際の計算過程まで記載していきます。
よく知ってる内容も数式で表すことで、徐々に数式への抵抗感も減らしていきましょう。
基本統計量とは
データは様々なことの履歴として残されますが、その一つ一つについて考えることは多くありません。
データ一つ一つについて考えるより、データを一つのまとまりの群として考え、全体としてどんな状態か、何が言えるかと考えることの方が多いです。
データ群を要約するということで、要約統計(記述統計)とも言われます。
基本統計量にはさまざまありますが、
今回は統計検定2級の範囲に従ってこれらについて説明します。
合計
最大値
最小値
範囲
中央値
最頻値
平均
期待値
分散
標準偏差
変動係数
皆さんがよく知る簡単なものから、ちょっとトリッキーなものまでさまざまです。
数式に表す際の前提
これから数式を多数出していきますので、統計学における慣例などをあらかじめ説明します。
昔からの数学者が使ってる文字だと思って、諦めて覚えてください。

最初は見慣れないかもしれませんが、慣れれば様々な文献が読みやすくなるはずですよ。
なお、文字については文献によって多少異なることもありますが、
数字を文字で置き換えるという操作に慣れていきましょう。
データ群において、全データ数は$${n}$$と表します。
例えば10個のデータ群なら、n=10といえます。
また、データのことを$${x}$$と呼びます。
データの取得順に1から番号を振っていったとき、番号名をiと呼び、
i番目のデータを$${x_i}$$と呼びます。
具体的には、1番目のデータなら$${i}$$=1なので$${x_1}$$、5番目のデータなら$${i}$$=5なので$${x_5}$$という感じです。そのため、$${i}$$の最大値はnとなります。
例として、次のようなデータ群のとき。
3 6 7 4 2 9
このとき、データは6個なのでn=6。

という風にテーブルとして文字とデータ番号が与えられます。
また、Σ(シグマ)という記号にも慣れましょう。

この場合、
iが1のときの○○の計算を行う
iが2のときの○○の計算を行う
iが3のときの○○の計算を行う
・・・
iがnのときの○○の計算を行う
↓
最後に全て合計
ということを表します。
各基本統計量の求め方
さて、ここからは実際の求め方に入ります。
1度全ての求め方を提示しますが、この後に例題を提示しますので、そこで実際に計算してみましょう。
・合計
個々のデータを全て足し合わせた値を合計と言います。

データ全体の大きさやベクトルを表します。
・最大値、最小値
データ群の中で最も大きい値を最大値と言います。反対に、最も小さい値を最小値と言います。
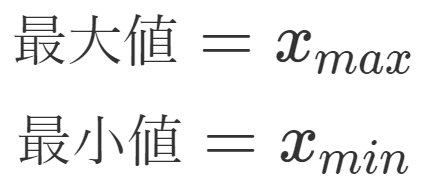
データ全体を表すというより、「どんなデータがあるか」を調べるときによく求めます。
・範囲(レンジ)
データの最大値と最小値の差を範囲(レンジ)と呼びます。
データ群内の分布がどれだけ広がっているかを表します。
範囲が大きいと、それだけデータが広がっているということを表します。

後述する標準偏差(分散)でもデータの分布の広がりを表すことが出来ますが、
最大値・最小値が非常に簡単に求めやすく、範囲も引き算なので非常に計算しやすいという特徴があります。
それを活かし、生産管理や品質管理などの現場で「とりあえずざっくり知りたい」という時によく用いられます(X-R管理図など)。
また、研究開発においては、データの外れ値を求めるQテスト法にて、この範囲(レンジ)が大活躍します。
上記2つはどちらも統計検定では使いませんが、意外と活躍するところがあるとだけ覚えておいてくださいね。
・中央値(メディアン)
データを小さい順(もしくは大きい順)に並べたとき、
中央に位置する値を中央値(メディアン)と言います。
データ数が奇数の時はそのままですが、偶数の時は足して2で割ります。
x1,x2,x3,…,xnを大きい順もしくは小さい順に並べ、x’1,x’2,x’3,…x’nとしたとき、

として計算されます。
数式で書くとちょっと見慣れないですが、
「データ個数から見て真ん中の値だ!」と思って頂ければ結構です。
・最頻値(モード)
データ群において、重複した回数が最も多いデータを最頻値と言います。
最頻値は複数現れることもあります。
あまり求めることはありませんが、どのデータも重複しない場合は全てのデータを最頻値として扱われます。
度数分布表を作成するとすぐに分かりますが、式で表す方法がないため公式はありません。
・平均
データの合計値をデータ数で割ったものを平均値と言います。
データの中間的な値を指しますが、中央値とは区別してくださいね。

ちなみに、$${\overline{x_A}}$$の読み方は「エックス・バー」です。バーが平均を表すので、$${\overline{x_A}}$$で「xの平均」という意味になります。
中央値と平均値の差を取ることで、分布の偏りを簡単に求めることが可能です。
これについては後述の例題にてご紹介します。
・分散
各データと平均値の差をとって二乗し、その合計をデータ数で割ったものを分散と言います。
データのばらつき具合を表します。
値が大きいとデータのばらつきが大きいといえます。
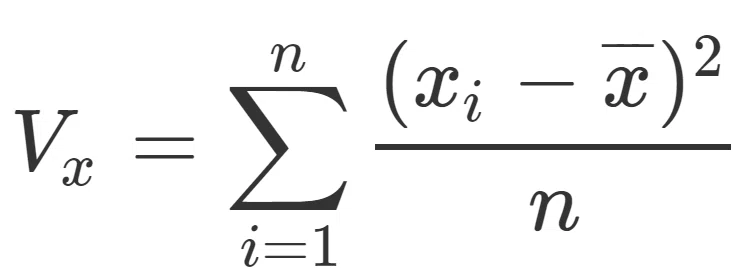
なお、「各データと平均値の差」のことを偏差(≠偏差値)といいます。
また、「二乗して合計した値」を平方和といいます。
そのため、「分散は偏差平方和の平均」とも言えます。
この考え方はいずれ使います。またそのときに記載しますが、そんな言葉もあるんだなーと思って頂ければ。
・標準偏差
分散の平方根をとったものを標準偏差と言います。
分散と同様にデータのばらつき具合を表し、値が大きいとデータのばらつきが大きいといえます。
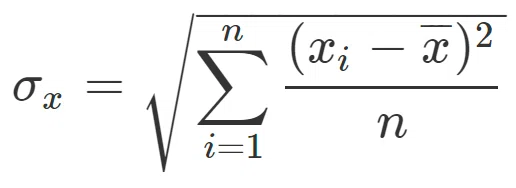
ちなみに、$${\sigma_x}$$は「シグマ・エックス」と読みます。ギリシャ文字の小文字の一つです。
シグマは標準偏差を表すので、$${\sigma_x}$$で「xの標準偏差」という意味です。
ついでにいうと、合計を表すΣは大文字です。同じシグマでも全然意味が違うんですね。
分散を求める過程で2乗し、パラメータの単位がおかしくなっているのを直すために平方根(ルート)を取っています。
そのため、標準偏差は各データや平均値などと単位が同じくなり、
データやパラメータ同士を足したり引いたりできます(線形性があるといいます)。
・変動係数(CV)
標準偏差を平均値で割ったものを変動係数(CV)と言います。
相対的なデータのばらつきの大きさを表します。
データが大きいほど標準偏差も大きくなるため、
異なるデータ群では標準偏差同士でばらつきを比較するより、変動係数で比較した方がよい場合があります。
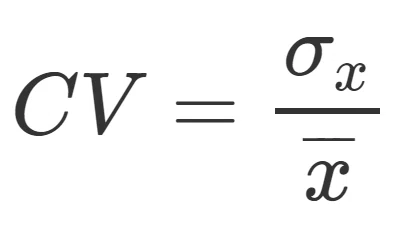
標準偏差も平均値も単位が同じため、CVに単位はありません(無次元数といいます)。
そのため、「平均値に対してどれくらいばらついているか」を相対的に比較でき、
本来全く違うデータ群や尺度同士での比較も可能です。
お疲れ様でした。ここまでで基本統計量の求め方は大丈夫でしょうか。
数式で書くとちょっと慣れないかもしれませんが、今後に向けて覚えていきましょう。
例題:実際に求めてみる
このようなデータ群を用意しました。
便宜上、こちらをデータ群Aと呼びます。

n=10のデータです。
これについて、平均値と中央値、標準偏差、変動係数を求めてみましょう。
データ群Aについての統計量なので、各パラメータの添え字にAを付けていますが、求め方は同じです。
初めてなのでなるべく丁寧に計算を書きます。少々文字が多く長いですが、頑張って付いてきてくださいね。
平均値
公式は
ですね。今回はデータ群Aに対しての平均値$${\overline{x}}$$なので、$${\overline{x_A}}$$と表します。Aのデータ数は$${n_A}$$と表し、各データ番号は$${A_1}$$、$${A_2}$$、$${A_3}$$・・・と表され、最大値は$${A_n}$$となります。以上の内容を公式に当てはめると、次のように求めることが出来ます

よって、平均値は4.6となります。
なお、小数点以下の桁数は、実データよりも一桁増やして表すことが一般的です。
今回は実データが整数なので、平均値は小数点第一位まで求めました。
中央値
データを小さい順に並び替えると次のようになります。

n=10は偶数なので、偶数の時の公式を使います。すなわち、これです。

並び替えた後、データ数の真ん中にある2つを足して2で割ると言うことですね。
数式がちょっと分かりづらいですが、同じように代入すると、

よって、中央値は4.5となります。
標準偏差
公式は以下の通りです。
平均値は先ほど求めた値を使います。$${x_i}$$は各データですね。
データ数が10個あるので、偏差を求めて2乗するのも10回必要です。
…めんどくさいですか?私もそう思います。
ちょっと計算が大変ですが、頑張りましょう。

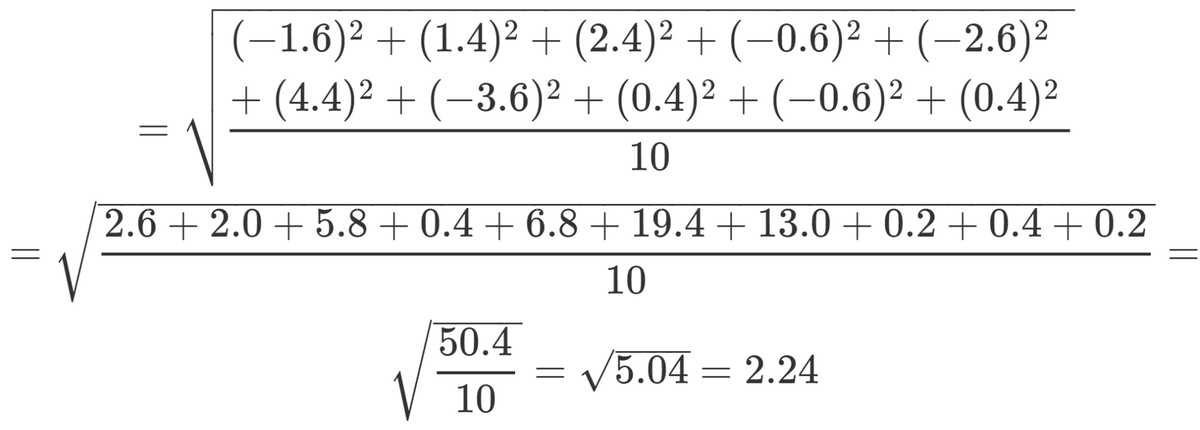
よって、標準偏差は2.24となります。
なお、実際は小数点以下の桁数は平均値と合わせる、もしくは平均値より一桁増やすことが一般的です。ただし分野によっても異なります。
変動係数
ここまでで求めた標準偏差と平均値を利用すればすぐ求められます。
標準偏差を平均値で割るだけですね。

よって、変動係数は0.49となります。場合によっては%(今回の場合は49%)で表すこともあります。
どうでしょうか。ここまで求めることが出来ましたか?
標準偏差を求めるのはデータ数が多くなると本当に大変です。
「なんでわざわざ2乗してから合計してルートするんだ」と思ったかもしれませんね。

私も同じ壁にぶつかりました。
もちろん、ちゃんと理由があります。
ただ、意外と説明が難しくピンとこないことも多いため、またの機会にしたいと思います。
本当はこの記事で書くつもりだったけど、この記事自体も長くなったので。ごめんなさい。
なお、理由については統計検定2級では覚える必要がないので、とりあえず式さえ覚えていれば全然OKです。
さて、それではもう1つ例題を。
次のデータ群Bに対して平均値、中央値、標準偏差、変動係数を求めてみましょう。
計算方法は同じです。
なお、実際の統計検定では電卓を使って求めることとなります。
二乗をするときには、✖(かける)ボタンを2回押して=(イコール)を押すと簡単に求められますよ。

いかがでしょうか。以下のようになったら正解です。
平均値 167.6
中央値 126
標準偏差 82.09
変動係数 0.49
基本統計量の比較
さて、データ群AとBの基本統計量が求められましたが、ちょっとこれを見比べてみましょう。
データ群 A B
平均値 4.6 167.6
中央値 4.5 126
標準偏差 2.24 82.09
変動係数 0.49 0.49
まず、平均値と中央値について。
A群では平均値と中央値の差が0.1しかありませんが、B群では41.6もあります。
この差はなんなのでしょうか。それとも、各データの値が大きいからしょうがないものなのでしょうか?
それぞれのデータ群をプロットすると次のようになります。
また、平均値を▲、中央値を◆で表しています。


データ群Aについては、平均値の▲も中央値の◆もデータの真ん中くらいに位置しているのに対し、
データ群Bでは、平均値の▲は真ん中ですが中央値◆が左に寄っています。
これは、データの偏りという観点から説明が出来ます。
データ群Aでは、平均値より小さい(グラフで言うと左側)データが5個。
平均値より大きい(グラフだと右側)データが5個。
平均値基準で左右のデータ数が同じです。
一方でデータ群Bでは、平均値より小さいデータが5個。
平均値より大きいデータが4個と、数に差が生まれています。
中央値はデータ数に依存することから、平均値よりも小さくなったのです。
「たった1個でしょ?」と思うかもしれませんが、データ数が9個のうちの1個ですから、割合的にはそれなりに大きいです。
よって、先に述べた通り中央値と平均値の差からデータの偏りを評価することが出来ます。
データのばらつきという観点から見るとどうでしょう。
標準偏差を比較するとデータ群Bの方が圧倒的に大きいですが、平均値・中央値がそもそも大きいため、
単純に「Bの方がばらついている」という結論には至りません。
そこで、変動係数で比較してみましょう。
変動係数を比較するとAもBも同じ0.49です。
相対的な比較ですが、「ばらつき具合」という観点で考えると、データ群AもBも変わらないのです。
このように、適切なパラメータとそれに適した観点でデータ同士を比較することが、
統計学を利用したデータ分析において重要です。
終わりに
いかがでしょうか。思いのほか長くなってしまいました。
基本統計量の求め方と何を表しているかは、十分に答えられるようにしていきましょう。
エクセルでも簡単に求められる値ですが、それぞれを求めて適切に評価できるようになったら、データ解析が一歩前に進むはずですよ。
ここまでお読みいただき、ありがとうございました!
この記事が少しでも参考になりましたら「スキ」を押していただけると幸いです!
株式会社分析屋について
弊社が作成を行いました分析レポートを、鎌倉市観光協会様HPに掲載いただきました。
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。