「これはスモウ」「スモウってこれか」言語集団におけるラベル付けの発生【論文紹介】#18

話し手(Speaker)側の画面に3つの図形が表示され、そのうち一つがランダムに選ばれて黒枠を付けられる(下図a)。顔の見えないところにいる聞き手(Hearer)にも同じ3つの図形が見えていて、どれか1つを選択できるようになっている(下図b)。その聞き手に同じ図形を選んでくれるように、話し手は黒枠で選ばれている図形の特徴をアルファベット6文字以内で伝える。並び順はランダムに変えられているため、左、中、右という伝え方はできない。話し手と聞き手を交代しつつ、正解した数だけ両者ともに報酬がもらえるので、頑張ってうまく伝える。できるだけ齟齬が起こらず良いデータが取れるように、英語を母語とするアメリカ在住者に限定して参加者を募った。

この実験を人数を変えて行うと、あるところで急速にわかりやすい共通語彙に落ち着くという相転移的な振る舞いが見られた。しかもそれが6~8人程度という意外なほど少ない人数で発生し始めるのは、誕生日のパラドックス(23人集めれば、誕生日が同じ組が1組でも発生する確率が50%を超える)と同じロジックが人数と語彙数に対して働くことによるものである。
今回紹介する論文はこちら。
Experimental evidence for scale-induced category convergence across populations
集団間のスケール誘発性カテゴリー収束の実験的証拠
Experimental evidence for scale-induced category convergence across populations | Nature Communications
(その補足情報も重要な箇所が多いので適宜参照のこと)
41467_2020_20037_MOESM1_ESM.pdf (springer.com)
言語によるラベル付けは、言語や文化や個々人によっても異なる。
例えば、日本語で「くちびる」は口の周りのピンク色の部分のことだが、その訳語によく充てられる英語の“lip”は口の周りの柔らかい部分(概ねしゃべるときに動く部分)のことで、日本語の「くちびる」より範囲が広い。
本研究では、上の図5cのような新奇で曖昧な(視覚)刺激の連続体に対してどのようなラベル付けがなされるかを、冒頭で紹介した「グルーピングゲーム」によって実験し、その統計的な振る舞いを分析する。
実験は、2人組が80組と人数N=6, 8, 24, 50の集団それぞれ15組で行った。
50人で行うとは、50人の集団の中からランダムで2人組を選んで話し手と聞き手を1ターンずつやるのを何度も繰り返す。
参加者の割り振りもランダムで、何人組に割り振られたかは参加者には知らされない。何人組でやる場合も、1人がやるのは100ターン程度とした。
(トータル2年かかったそうだが実際に1480人も参加者を募って実験したのがすごい。)
まず、2人組と50人組の実験の結果は下図の通り。画像の連続体の領域について、どの範囲にどのラベルが付けられたかはDBSCANによってカテゴライズした。

横軸は1500枚の連続する画像、縦軸は各色で示される各ラベルで正解した頻度で、15回の別の実験の結果
例えば、50人の場合(b)では15回の実験セットのほとんどで、600あたりの図形はカニ(crab)、800あたりはカエル(frog)というラベルで正解が頻発した
2人組の場合は、組ごとに非常に多様なラベル付けが行われた。異なる組で共通していたラベルの付け方はわずか6%(クラスカル・ウォリス検定による)しかなかった。
それに対して50人組の場合は、異なる組でも50%(ウィルコクソンの順位和検定による)ものラベルが共通して付けられ、その範囲の分割の仕方も類似している。
分ける位置が個人によって違うか(生得的な差はあるか)を調べてみたところ、条件に関係なく、個人は連続体全体からほぼ同じ広がりで図形を分割した。このことは、条件間で個々人が見た画像の生の分布に有意差がなかったことからも示されている。(補足情報1.4章)
またDBSCANには、まとめ方をどれくらい荒っぽくするかを任意に変えられるパラメータ(MinPtsとε)があるが、最終的な語彙数(図1の1Trialに現れる山の数)を3~5以上になるように調整すればTrialを変えても類似度の値はほぼ同じになる頑健性のあるデータが得られる。(補足情報1.6章)
人数が増えると多様な意見が出てラベルの付け方はバラバラになるのではないか、と思われるかもしれないが、図1の2つの結果を見るとその直感とは反している。
一試行中で一度でも出たラベルの数を数えると、人数が多いほどラベルの多様性は多い(これは直感のとおり)。下図は、横軸を一度でも出たラベルの数、縦軸をJaccard係数による各試行ごとの類似度としてプロットしたものである。
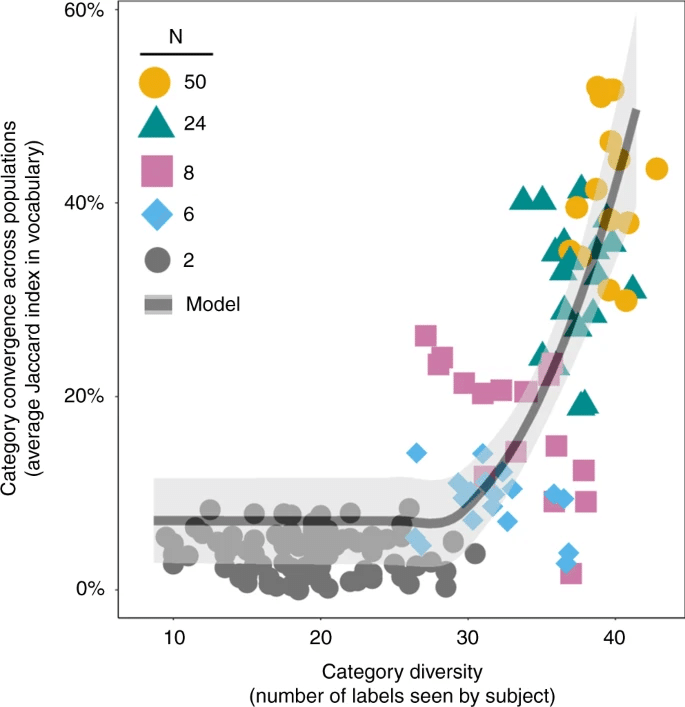
人数ではなく出される語彙数を横軸にすると、あるところで急激に類似性が高まるのがよく見て取れる。黒線で示される理論的予測(補足情報1.3章)ともよく一致している。
これはいわば、誕生日のパラドックスのロジックが語彙数に対して働き、「この語さっきも見た!」という事象が起こりやすくなり、正解される頻度が上昇して採用される語彙が急速に収束する。言い換えると、各単語が誰に正解されたかという"誕生日"の情報を持っていて(正解されることによってその語は生き残るようになる)、試行中に出される単語が増えるほど、同じ"誕生日"を持つ語がばったり出会う確率は高まる。つまり、出される語彙数が増えるほど、異なる人から独立に出されたのに「さっきも見た!」となる確率が高まる。そのようなメカニズムが働くので、人数が増えることによるラベルの収束は、ある転換点で流行が起こるように大人数に採用されるようになるのである。これがまず一つ、語彙数に対する誕生日のパラドックス効果である。
上記の説明では、いずれかの語彙に収束することは説明できるが、異なる試行でも類似の語彙に収束する理由はわからない。そこで、最初に出される語彙の頻度を調べてみると、下の図3aに示されるようなZipf の法則に近い頻度の偏りがある。

集団が大きいと、最初に頻出するラベルの広がりが増幅される
出された単語は、集団内でやり取りされるうちにどれが流行るかがだんだんと決められる。
図3bは、集団の人数(横軸)によって、選ばれたラベルが、小さな集団(N = 2)では、希少なラベルを採用する可能性が有意に高く、これらの個体群は乖離した進化の軌跡をたどることになった。しかし、集団サイズが大きくなると、「カニ(crab)」や「ウサギ(bunny)」のようなよくあるラベルが強化されて採用される可能性が有意に高くなり、一方、希少ラベルが普及する可能性は有意に低くなった。この結果は、独立した集団間の集団サイズとカテゴリー収束の間に直接的な関係があることを示している(図3c)
これらのラベルの採用は、その認知的魅力によって厳密に決定されるのではなく、むしろ、より大きな集団において強化され、臨界量に達する可能性が高いという事実によって決定されることを示唆している。
このことを理論的に説明する前段階として、誕生日のパラドックスがなぜ直感に反するかを簡単に説明する。
まず、ランダムに出会った相手が自分と同じ誕生日である確率は$${\frac{1}{365}}$$である(閏年や双子は考えない)。
人数が増えた場合、例えば下の図のような6人の場合は、自分と同じ誕生日の人がいるかを調べるには、辺で示される5組(自分以外の5人)で、誕生日が同じか調べることになるが、グループの中で1組でもいるかを調べるには、辺で示される15組で誕生日が同じか調べることになる。問題としては後者を考えたいのに、(自分と)同じ誕生日になる確率は$${\frac{1}{365}}$$だから……と考えると、直感としては前者のように考えてしまうのがまず間違いである。

感覚的には、自分と関係ないところを無視してしまいがちだがそっちのほうが多い
一般に人数がN人のとき、自分とつながる辺の数は$${N-1}$$になるが、
グループ内のすべての辺の数は$${\frac{N(N-1)}{2}=\frac{1}{2}N^2+\frac{1}{2}N}$$となる。
この、辺の数が人数Nの2乗に比例して増えるのが、直感と乖離する部分である。N=6ですでに3倍も違うし、人数が20人にもなれば、直感とは1桁違う数になってしまう。
グループの中に1組もいない確率は、$${1-\frac{364}{365}^{(組の数)}}$$なので、思ったよりも急速にこの確率は小さくなる(1組でもいる確率は大きくなる)。
本論文の実験結果の理論的説明としては、次のように考えられる。
サイズNの母集団のうちnの標本でk人の成功者が出る確率Pは、
$${P=\sum_{n,k}\frac{{}_KC_k・{}_{N-K}C_{n-k}}{{}_nC_n}}$$(補足情報 式(1))
本実験では、N=1480人の中から50人の集団(n=50)を選んでその中から共通のラベルを認識して正解する確率のことである。
やや複雑な式だが、言っていることは誕生日のパラドックスとほぼ同じである。これをグラフで表したのが下の図S2である。

人数が多いといわば、"ランダム性によるノイズ"の影響が少なくなり、少しでも頻度の多い(上図暖色系)ものが優勢になりやすい。逆に、人数が少ないとノイズが多く、頻度が低いもの(上図寒色系)も30~40%とかの確率で思いがけず優勢になりやすい。実際、2人組の場合には「カニ」が導入された後に他のラベルが入れ替わったりもした。
誕生日のパラドックスと絡めて説明すればこうなる。人数の多い集団では、自分を含まない組の数のほうがずっと多く、そこでいつの間にか「この範囲ならカニと言えば正解してくれる」といった合意形成が図S2に示されるように急速に進む。
これがもう一つの、人数に対する誕生日のパラドックス効果である。
前述の語彙数に対する誕生日のパラドックス効果との相乗効果によって、わずか6~8人という驚くほど少ない人数で急速に語彙の収束が起こり始めるのである。
上記の結果からは、どのラベルが採用されるかは、ラベル自体の認知的に顕著な特徴だけに依存するのではなく、集団における最初に出されるラベルの頻度にも依存するということがわかる。直感としては、あるラベルが人気になるのは本質的な魅力を持っているからだと思うが、そうではない。
そのことをさらに検証するため、あえてレアなラベルを流行らせることができるか、次のような実験を行った。
図1bの典型的なラベル付けとは違い、「スモウ」などの図3aでは非常にレアなラベルを採用した下図のようなリストを作り、それを覚えた人(合議体: confederationと呼ぶ)をグループに混ぜて、それでも同様の結果になるかという頑健性試験を行った。
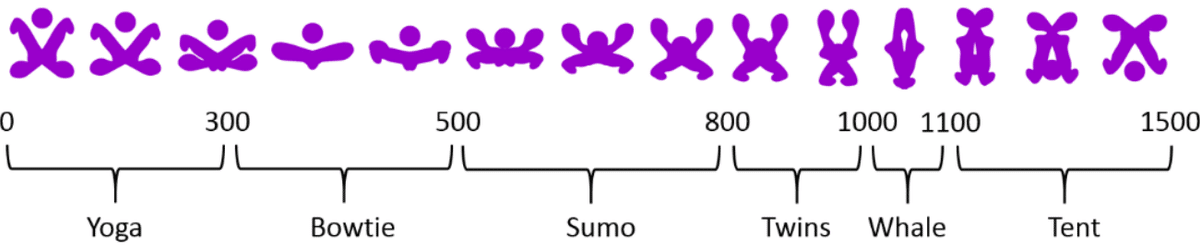
合議体は24人のグループに7人(37%)混ぜ、構成員は全員入れ替えて6回行った。合議体がいない場合、約25%は何もしなくとも最初にカニとラベル付けするという結果が得られているため、それに打ち克てそうな割合として37%にした。
下の図4は、6回の試行でのターン数1~100までの「カニ」と「スモウ」での累積正解数、図S10は100ターン後の画像の連続体全体での各ラベルの正解頻度。

実験を6回やっても全てで、「カニ」より「スモウ」での正解数が多くなった

スモウ以外も7人の合議体によってしっかりと上書きされている
カニが6回中2回共存しているのもすごいが
なんと、7人の影響で「スモウ」が常に優位になったのである。頑健性があると思いきや「カニ」があっさりと「スモウ」に抑え込まれてしまった(←日本の昔話みたい)。カニ以外の範囲でも、24人中7人の合議体の影響でことごとく上書きされてしまっている。
「カニ」のような最初に出される頻度が高いラベルに対して、「スモウ」のようなレアなラベルでもそれを上回る頻度で人為的に出せば人口に膾炙することができてしまうのである。
本論文で重要なのは、既存の客観的境界を持たない、任意かつ新規の連続的刺激に対して、語彙をやり取りする人数を増やすことによってによってカテゴリーが収束することを観察したことである。
この知見は、ソーシャルメディアにおける受容可能なコンテンツと受容不可能なコンテンツの分類における一貫性を向上させることなどが期待される。
本論文は上記の議論で締められているが、この実験結果は他にも非常に示唆に富むと私は思う。以下、関係ありそうなものからなさそうなものまで思いついただけ書いておく。
・同じ著者による先行研究は、人は使わずエージェントベースのシミュレーションで(こちらを参照)、Zipf則ではなくランダムな一様分布の文字列でやったために異なる結果が出た。
0509075.pdf (arxiv.org)
一様分布では共通語彙には収束せず、最終的に得られるラベルは初期状態のわずかな差が大きく影響して、試行ごとに大きく異なる結果となった。
似た例として、蔵本モデルは、固有振動数がランダムな一様分布では収束しないが、固有振動数(リンク先動画の$${ω_i}$$)に正規分布のような一峰性の偏りがあれば収束するということが示されている。蔵本モデルと本論文の結果とのつながりは不明だが、何らかの関係は示せそうだ。
・本論文の実験は、実験後に自分は何人組に割り振られていたと思うかを聞いてみたところ、面白いことに、何人組の参加者でも5~10人組という答えが多かった(補足情報1.5章)。これはつまり、言語の相転移は、統計的に見たとき明らかに起こっていても、その構成員はほぼ気付かないということだろう。
例えば、読者の皆さんは、日本語で使用頻度の高い単語(全品詞含む)トップ3を言えるだろうか?調べずに自分の言語行動を思い返して3つとも当てられる人はまずいないだろう(正解はこちら)。そしておそらく、今後日本語が変わってトップ3が大きく変わったとしてもほとんどの人は気付かないと思われる。(ちなみに、パソコンや携帯が普及したことによっても、予測変換によって漢字の使い方が大きく変わったと言われているが、それに自覚的な人はどれくらいいるだろうか。機械に弱い人が予測変換をうまく使いこなせなかったりするのは見るが。)
・TwitterなどのSNSで、自分が浮かばなかったピッタリな言葉に出会えたと思うことがある。しかしそれには注意が必要ではないだろうか。
我々は日常で、有形無形問わず様々な事象を言語化しようとする。その時に選ぶ言葉は実験で示されたように個々人によってばらばらだろう。そして、SNSで自分が浮かばなかったピッタリな言葉と思えるものがこの実験で言う「カニ」のような広く共有される語彙だろう。
実験では、2人の場合はカニと言うラベルを付けなかった人はたくさんいるが、そういう人でも50人のグループに入れられれば、カニがぴったりだと思って使い続けるようになるだろう。
しかしそれは、最初に思い浮かぶ言葉のわずかな頻度差が増幅されたものであって、一般大衆での語彙の頻度の偏りと、自分で思い浮かぶ語彙の頻度の偏りは違うものだろう。
自分でたくさん語彙を吐き出して、この世界に1人分は確実に自分の言語活動の影響を残していく、それが言語を受け身ではなく能動的に使う誠実な態度ではないかと思う。
(私のnote記事のシリーズもそういうことをちょっと意識している。)
もうちょっと言うと、こういう記事の執筆はAIによってかなり代替されつつあるが、AIはどれも"描き方が無難な絵柄"ばかりで、本実験で言う「カニ」ばかりになっているような印象がある。AIにはできない人間のやることとして、多様な語彙を生み出すことがあるのではないかと本論文を踏まえて思う。
(2024/09/04 追記)
興味深い論文を見つけた。
[2408.17325] Impact of ChatGPT on the writing style of condensed matter physicists (arxiv.org)
同じ筆頭著者でChatGPT登場前と登場後の論文を、Grammaryで文法的な質を調べた結果、英語を含むゲルマン語族話者はあまり影響を受けていないが、他の語族の話者は有意に質が上がっており、ChatGPTは母語の違いによる研究参加の障壁を小さくしたというのが↑この論文の主旨である。
その点よりも私が注目したいのは、論文中で1回しか出てこないunique word と英語全体で頻度5000位以下のrare word を調べた結果、ChatGPTの影響で、unique word の使用が大幅に増加し、一方でrare word の頻度は減少したという点。
これは、本実験でいう「カニ」ばかりになる傾向がChatGPTの登場前後で有意に強まっていることが示された結果と言えるかもしれない。
また最近見た、人間は乱数を出すのが下手だが、ChatGPTはもっと下手という事実とも似ているように思う。
https://youtu.be/WS-IFSZMVAE?si=UcxbjjRQn03lnVRn
・英語やフランス語など、話者の多い言語は文法がシンプルになる傾向があるとされている。本論文の結果を踏まえると、語彙だけでなく文法要素としても、少しでも発話しやすい文法に落ち着いていく力学が働くのだろうと、方向性としては納得できる。(語彙だけでなく文法要素も同様かどうかは不明だし、話者が億単位になるとまた別の力学が働いていそうだが。)
・本論文の実験は、言語外の思考の調査にもちょっと踏み入れているようにも思う。最初に出されるラベルの分布は人によって結構違う。グルーピングゲームを一人でやるバージョンもあり(補足情報1.9章)、その結果は2人でやったときと同様に人によって結構違う。最初に出すときは、これは何だろうなと思って、形から、なんとかして自分の語彙の中から近いものを選ぶという過程であり、1つでも語彙が出てくるまでの部分は言語外の思考だと思うし、それを調べる格好の実験手法にもなっているように思う。
また、画像に限らず、音声や動画、他の五感刺激でも同様な実験ができそうな優れた実験手法だと思う。
・本論文の実験と同様のことが、実験ではなく思いがけず現実に起こった事例として、ニカラグア手話が思い当たる。1977年に、それまでニカラグアになかった聾学校が新たに作られ、それまで各家庭のジェスチャーしか持っていなかった聴覚障害者の子供たちが集められ、そこで共通言語となる手話が、授業時間外で勝手に作られていったという事例。言語が自然発生する様子をリアルタイムで言語学者によって記録された世界初の例として言語学界隈では有名である。(その初動を見て言語学者を呼んだ人もすごいと思う。それに相当する人がいないためにまだ発見されていない人類の財産がどれほどあるだろうか。)
本論文の実験では、全員英語を母語とするアメリカ在住者に限定していたが、ニカラグア手話では背景がばらばらである。それでも子供たちが何とか通じ合おうと言葉をたくさん出して共通語を作り上げていく過程は、きっと本論文以上に興味深いものだろうし、ニカラグア手話についての論文もいつかちゃんと読みたいと思っている。
・本論文と同様の実験を日本語話者で行ったら同様の結果が得られるだろうか。あるいは、母語がばらばらの集団で行った場合はどのような結果になるだろうか(カニ化って人間の語彙にもあったりする?カニがやたらと何度も出てきて気になった)。
日本語でやる場合、文字数制限は平仮名か片仮名のみで4文字以内くらいが妥当かな。
・本論文の実験では、6人以上のグループでは、メンバー全員が全員とつながっている完全グラフで行われたが、これはあまり現実には見られない。
より現実の社会のネットワークに近いモデルとして、Watts-Strogatzモデルがある。友達関係をたった6回たどれば世界中のどんな人ともつながるというスモールワールド仮説の論拠ともなるモデルである。
本論文の実験をWatts-Strogatzモデルで行えば、おそらく部分的に(50人のうちの8人とかで)方言やエコーチャンバーが発生したりしてまた違った結果が見られると思われる。
(余談)
本論文のグルーピングゲームは、哲学者のウィトゲンシュタインが晩年の著作『哲学探究』で提示した「言語ゲーム(Splachspiel)」に端を発する。その最初の時点で次のように、驚異的なほど言語行動の本質を鋭く切り抜いた描写をしている(こういう言葉の鋭さと威力が哲学者の本領発揮という感じがする)。
>ある言語を考えよう。その言語は、石積み人のAと助手のBの意思疎通に役立たねばならない。Aは石材の上に家を建てている。石材には、台石、柱石、板石、梁石がある。Bは、Aが必要とする順番に石材を渡さなくてはならない。この目的のために彼らは一つの言語を使う。その言語は、「台石」、「柱石」、「板石」、「梁石」という4つだけの語から構成される。Aが叫ぶ ―― Bが、その叫びに応じて運ぶよう教わった石を運ぶ。 ―― これを完全で原初的な言語としてみなせ。
(哲学探究 (mickindex.sakura.ne.jp) 第2節より(Mick氏によるちょっと独特な訳ですがほぼ全文公開されています))
これは『哲学探究』のかなり序盤の記述で、「これを言語としてみなせ」と定義を示してそれについての議論がこの後しばらく続く。見てわかる通り、Aが話し手、Bが聞き手で、骨子としては本論文のグルーピングゲームとほとんど同じ説明である。
思うに、このような哲学の論述がこれほど精度よく実験的に検証されているというのは他に類を見ない面白い学術成果ではないかと思う。
(追余談)
グルーピングゲームの前身として、もう少し単純なネーミングゲームというモデルがあり、それは私が修士課程で研究したテーマなので思い入れがある。その紹介記事もそのうち書きたいと思っている。当時参考にしたネーミングゲームの論文も、著者は本論文と同じBaronchelli先生で、研究室や博士課程の入り方についてだいぶ調べたりもした。
また、これを調べるために、理学研究科棟の隣の人文学研究科棟の図書室に潜り込んで大元となったウィトゲンシュタインの文献などを読み漁ったりもした。
『哲学探究』はウィトゲンシュタインの最晩年の著作であり、急いでかき集めた感じの断片集のような書き方で、死後に編纂された部分も多い。初めて読むと話が飛び飛びな感じで読みづらく感じると思うが、何度も読んでいると、じわじわと、しかし着実にウィトゲンシュタインの思考が自分の脳に染み込んでくる感じの読み味だと思う。私は理系ながらなんだかんだハマったし、学生時代に一番思考を大きく変えさせられた本といえるかもしれない。
『哲学探究』を私なりに要約すると次のようになる。
単語の意味とは何か(知らない言語だと見聞きしても何もわからないが、知っている言語なら見聞きした瞬間に意味を感じるのはなぜか)を考えたとき、辞書的な意味が単語に付随していて、それを覚えては毎回思い出しているのではない。単語の意味は、やり取りすることによって感じるようになってくるものである。例えるなら、トランプのジョーカーは、ババ抜きでは手元にあってほしくないが、大富豪なら手元にあってほしいものだ。大富豪のルールには「ジョーカーは手元にあってほしいものだ」などとは書いてなくても、大富豪のルールに則ってやっているうちに「ジョーカーは手元にあってほしい」とジョーカーの意味を感じるようになる。単語の意味も同じように、相手の反応や現実世界との関係を見ながら言葉をやり取りしているうちに意味を感じるようになるものだ。そのように、言葉のやり取りから意味を感じるようになる過程を言語ゲームと呼び、人間の言語活動の多くはそれで説明できる。
そんなことを踏まえて、こんなイベントをやったりもした。
次回(ぐらい)、ネーミングゲームについての私の修士研究の解説(かも)、乞うご期待!