
自分の文章を係り受け解析してみる

ここ最近、筆者の所属するVRChat創作グループ『ヴィルーパ観測機構』 (旧称:観測者) の内輪向けに、小説・ショートストーリーの執筆ノウハウに関するnoteを作っています。
その中で、いわゆる「文章のリズム」について解説するのをどうしたもんかと考えていたら、いつの間にか言語類型論だとかの学術的な領域に踏み込み始めました。
そんな「ほんまに趣味かコレ?」な領域の中に、日本語の語順について触れる部分があります。日本語では連体修飾語・連用修飾語が他の主語・述語を補足するような構造になりますが、語順によって語句同士の関係が変化することがあります。
この「語句同士がどういった関係を持っているか」というのを係り受けと言います。私が書く文章では係り受けを曖昧にしないために、単語の意味が向かう先を意識するようにしています。
一方、意識しているとはいってもほとんど手癖と勘で文章を書いているので、私は係り受けを体系的に理解していませんし、理論立てて説明できません。説明する側になるとこれはちょっと困ります。
そこで何かしらのツールを使うことで係り受けを客観的に分析し、それを読み解くことで自らの直感を上手く言語化できないかと考えました。
という訳で調べたところ、どうやら係り受け解析をやってくれるシステムがあるようです。
この記事では係り受け解析システムの実行環境を構築し、自分の書いた文章に対して実際に係り受け解析を行います。それを通して係り受けに関する自分の直感を言語化し、説明できるようになることを狙います。
利用するソフトウェア
今回利用するソフトウェアは、いずれも京都大学 大学院情報研究科 知能情報学コースの言語メディア研究室によるものです。
KWJA : Kyoto-Waseda Japanese Analyzer
KWJAは『汎用言語モデルに基づく高精度な統合的日本語解析器』です。入力した文章に対して単語正規化・形態素解析・分かち書きなどの分析を経て係り受け解析を施し、結果をKNPフォーマットで出力します。
同研究室のWebページにはKWJAのデモが用意されています。仮に公開されても気にしない文章であれば、そちらを使ってお試しで解析してみるのもいいでしょう。
PyKNP
JUMAN/Juman++およびKNPのPythonバインディングライブラリです。今回は付属コマンドを利用し、KWJAの分析結果を構文木として分かりやすく図式化するために使います。
【補足】
JUMAN/Juman++は形態素解析を行うシステム、KNPはJUMANの結果を使って構文・格・照応解析を行うシステムです。いずれも同研究室で開発されています。KNPの分析結果を示す記法がKNPフォーマットです。
JUMANとKNPを組み合わせることでも係り受け解析は可能です。が、今回はJUMAN・KNP・Pythonともにほとんど使わないので、説明は割愛します。
環境構築
なんかいい感じに環境構築をします。基本的にはKWJAとPyKNPをpipで持って来るだけなので楽チンです。
Pythonのインストール
私のメインPC環境はmacOSなので、HomebrewでPythonをインストールします。
Windows向けには、個人的に使いやすい環境ということでGitBashにて動作確認を行いました。Windows用Pythonのダウンロードページは以下からどうぞ。
# macOSの場合
$ brew install python@3.11
$ python -3.11 -V
Python 3.11.9
# GitBash(Windows)の場合
# インストーラでPythonを導入しておく
$ py -3.11 -V
Python 3.11.9以降はそれらの環境を前提に記述していますが、Pythonの実行環境さえ動けば類似のコマンドで同様のことが可能なはずです。
【補足】
PyKNPの公式サポートはPython 3.7.11ですが、やってみたら動いたので今回はPython 3.11を使用しています。
ただし執筆時点で最新のPython 3.12では、pkg_resourcesパッケージがdeprecatedとなっているため後述の図式化コマンドが動きません。
仮想環境を作る
私のPCでは以前にもPython実行環境を作っていたようですが、あまり使っていなかったためパッケージ類をどう管理していたか忘れてしまいました。
素の環境ではpipによるインストールが上手くいかなかったため、適当に仮想環境を作り、その中にKWJAとPyKNPを持ってきます。
Pythonのバージョンが複数あるような場合・パッケージの導入状況を汚したくないような場合も、仮想環境を作っておくことをおすすめします。
$ mkdir path/to/dir
$ cd path/to/dir
$ python -3.11 -m venv env_name仮想環境に入る
仮想環境が有効になっていると、その名前がシェルの頭に表示されます。
# macOSの場合
$ source env_name/bin/activate
(env_name) $ python -V
Python 3.11.9
# GitBash(Windows)の場合
$ source env_name/Scripts/activate
(env_name) $ py -V
Python 3.11.9KWJAをインストール
(env_name) $ pip3 install kwjaPyKNPをインストール
(env_name) $ pip3 install pyknp仮想環境を抜ける
(env_name) $ deactivate
$ echo "抜けると仮想環境の名前が消える"使ってみる
実際に係り受け解析を行ってみます。テスト用の文字列として、私の書いたショートストーリー『【本】に関する思考実験』から以下の一文を使います。
観測者の社内サーバーに保管された情報量は、一介の企業が持っているそれの比ではない。
KWJAで分析する
以下のようなコマンドで、KWJAによる分析ができます。
複数の文章を一括で解析したい場合、1行=1文となるようテキストファイルに記述すればそれぞれ個別の文章として扱ってくれます。
# オプションとしてテキストを入力する場合
(env_name) $ kwja --text "解析したい文字列" > knp_out.txt
# テキストファイルから入力する場合
(env_name) $ echo "解析したい文字列" > input.txt
(env_name) $ kwja --file input.txt > knp_out.txtテスト文をKWJAに入力して処理すると、以下のようなKNPフォーマットによる出力が得られます。
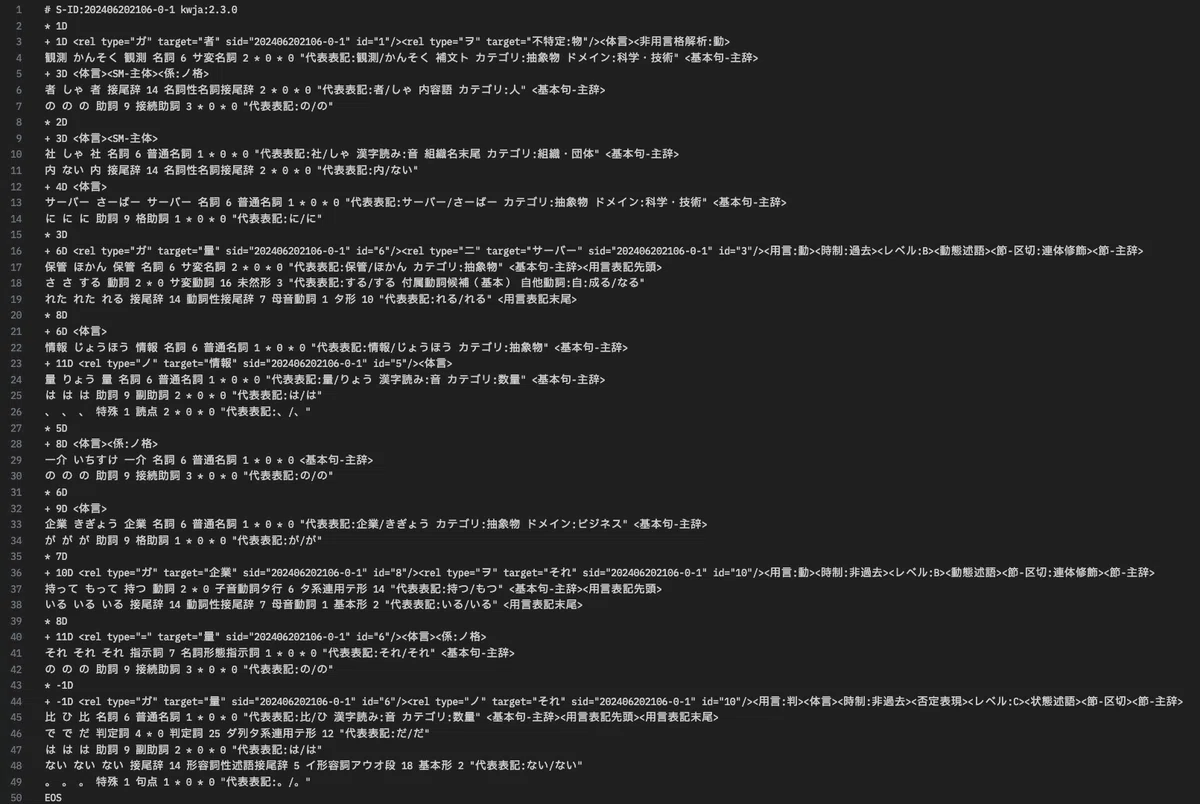
knp-drawtreeで図式化する
PyKNPのパッケージには、入力されたKNPフォーマットを構文木にしてくれるコマンド「knp-drawtree」がついてきます。今回はこれを利用し、KWJAの出力を構文木に描き起こしてもらいます。
(env_name) $ knp-drawtree --input knp_out.txt > result.txt【補足】
Windows(GitBash)環境においては、入力されるファイルの改行コードがCRLFだとknp-drawtreeのスクリプトが上手く働かず、図式化してくれませんでした。
この場合、VSCode等で改行コードをLFに変更すれば動作するようになります。
knp-drawtreeに図式化させ、体裁を整えたものが以下の通り。全角スペースを半角スペース2個に置き換え、VSCodeに等幅フォントを設定して表示しています。

係り受けによる繋がりが罫線で示されており、文節同士の関係が一目瞭然です。罫線の流れを追ってみると、この文章の係り受け関係には特に違和感もなく、おおむね私の意図した通りであることがわかりました。
せっかくなので、同SSから他にもいくつか解析してみました。結果は以下の通り。



また、これらとは別に、他のメンバーが作った『観測者』世界観の設定文をいくつか拝借して解析にかけ、自分が書いたものと比較してみました。
その結果なんとなく感じたのは、どうも私の書いた文章は『係り受け関係にある単語同士が近い位置にある』ことが多いっぽいです。離れていたとしてもせいぜい文節4つほど。
逆に言えば、係り受け関係にあるべき単語同士が離れすぎていると、文章の解釈に困難が生じうるといえるかもしれません。
関係のある単語同士がもっと離れている分析結果で、文章の解釈には特に問題ないような例も当然ながらありました。それはそれで、単語がかかる先に誤解が生じないような構造を成立させる文章になっているようです。
そのようなケースについては、単なる語順とはまた別の文法ルールが関わってきそうなのでひとまず置いておくことにします。
少なくとも、私にとっては係り受けが離れすぎない文章の方が読みやすく、そういう文章を好んで使う傾向があるようです。
まとめ
係り受け関係にある単語同士の距離感が、文章を解釈する際の容易さに影響してそうだな、というのがなんとなく判明しました。
日本語の文法構造に関する他の理論と組み合わせれば、語順に関する話はうまく説明できそうです。そのあたりの記事はまたいずれ。
ぶっちゃけ内輪で消化するものに関して言えば、こんな学術的な考えを持ってまで文章を作る必要はありません。ですがグループとしての活動、あるいは公にするコンテンツとなると、読みづらい・解釈が難しいような文章は格好がつかんよなとも思う次第。
この記事は、そういうシチュエーションに備えるような意味もあります。
分かりやすい文章が書きたいとか、あるいは自分の文章で意味するところが正しく伝わっているか自信がないとか。そういうケースの参考になれば幸いです。
参考
京都大学 大学院情報研究科 知能情報学コース 言語メディア研究室
https://nlp.ist.i.kyoto-u.ac.jp/KWJA GitHubリポジトリ
https://nlp.ist.i.kyoto-u.ac.jp/PyKNP GitHubリポジトリ
https://github.com/ku-nlp/pyknp
投稿日:2024-06-27
最終更新:2025-02-03 グループ名の変更に伴う微修正
#ヴィルーパ観測機構 #観測者ログ
#創作
#小説 #SS #ショートストーリー
#小説の書き方 #執筆ノウハウ #創作論
#Python
#自然言語処理 #形態素解析