
SDWebUI-Forge の LayerDiffuse(旧:Layer Diffusion)の使いかたを解説!漫画やサムネイルなどにも使える、レイヤー構造を理解した新しい画像生成。

どうも、皆さん!夜寝る前は、ミルクを飲むタイプの女、葉加瀬あいです🫡
以前、こちらの記事でStable Diffusion WebUI Forgeを使用して、LayerDiffuse(旧名:Layer Diffusion)の完璧な透明背景の画像やレイヤー構造を理解した画像編集について解説をしたんですけども、今回はその実践編ということで、実際に画面で操作しながら実行時の注意点やTipsなどをお伝えしていけたらと思っています!
LayerDiffuseの画像

なお、大まかな流れとしては、
まずStable Diffusion WebUI Forgeをインストール
そこにStable Diffusion WebUI Forge用のLayerDiffuseの拡張機能をインストール
そして必要な学習モデルを使用して、実際にレイヤー構造を理解した画像生成を行っていく
といった流れになります。
Stable Diffusion WebUI Forgeのインストールが必要になりますので、こちらの投稿を参考にインストールなどを行っておいてください。
また、私の記事を読む上での注意事項などをこちらのプロフィール記事で説明しておりますので、ご一読いただいた上で閲覧するようお願いいたします。
それでは、早速続きを解説していきたいと思います!
LayerDiffuseのインストール方法
それでは、早速、LayerDiffuseのインストール方法を解説していきます!
前提条件
前回の記事やこちらの記事の冒頭でもお伝えした通り、画像生成AIのツールはStable Diffusion WebUI Forgeを使用しますので、それはインストールされていることを前提に進めていきます。まだインストールが完了していない方はこちらを参考にインストールしてみてください!
なお、基礎知識に関しては、こちらの記事にて解説をしておりますので、そもそもStable Diffusion WebUI Forgeが何なのかということがわからない方や、本家のStable Diffusionとどういったことが違うのかを知りたいと言った方は、こちらのリンクからご確認していただけると良いかと思います!
なお、私はこちらのようにローカル環境でStability Matrixというものを使用して解説していきます。こちらもアップデートの多いStable Diffusion WebUI Forgeをわずか1-Clickで更新することができて、なおかつ他の画像生成AI系のパッケージなどとも、学習モデルやLoRAなどが共有できるといった優れものなので興味のある方はぜひ使ってみてください!こちらも先程のURLにて解説をしております。
インストール手順
前置きが長くなりましたが、早速LayerDiffuseの拡張機能をインストールしていきます。
まずは、こちらのURLをコピーして「Extensions」タブ内の「Install from URL」タブを開いてインストールを行ってください。
https://github.com/layerdiffusion/sd-forge-layerdiffuse1番上の欄に貼り付けてインストールボタンを押すだけで大丈夫です。インストールが完了したら、Stable Diffusion WebUI Forgeを一旦停止させてから再起動してください。
(画像)
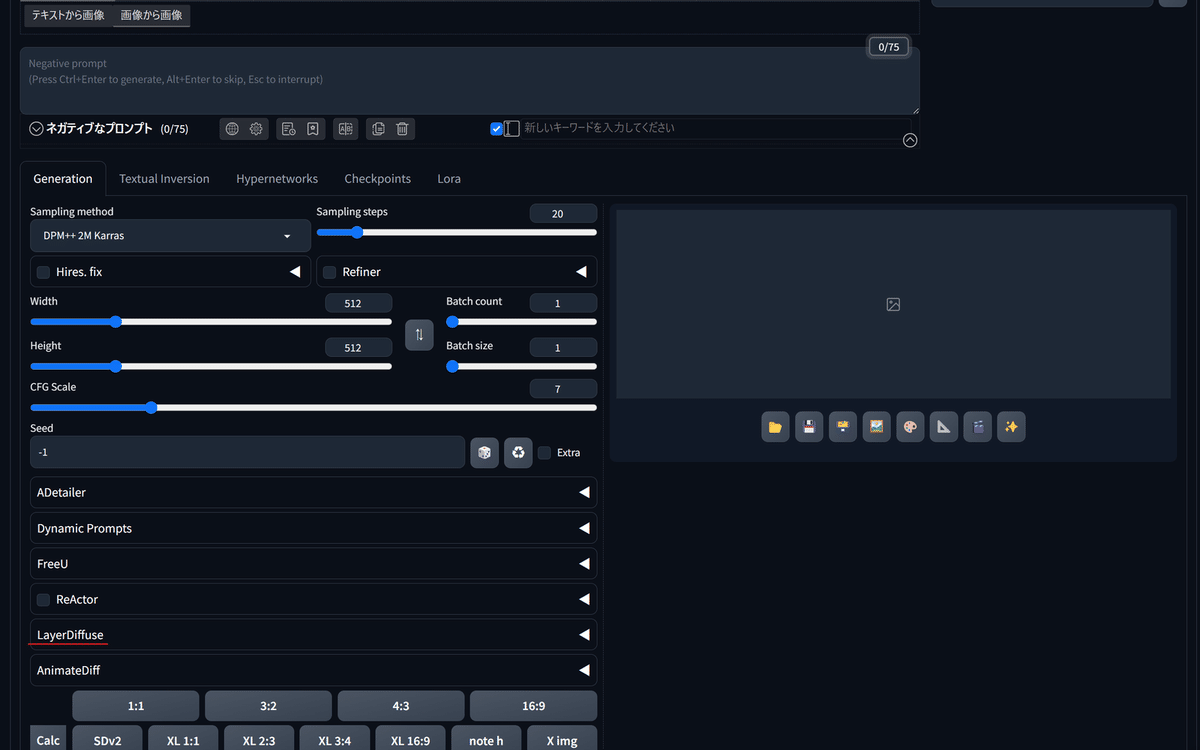
すると、こちらの画像のようにLayerDiffuseというタブが表示されているのが確認できるかと思います。
(画像)
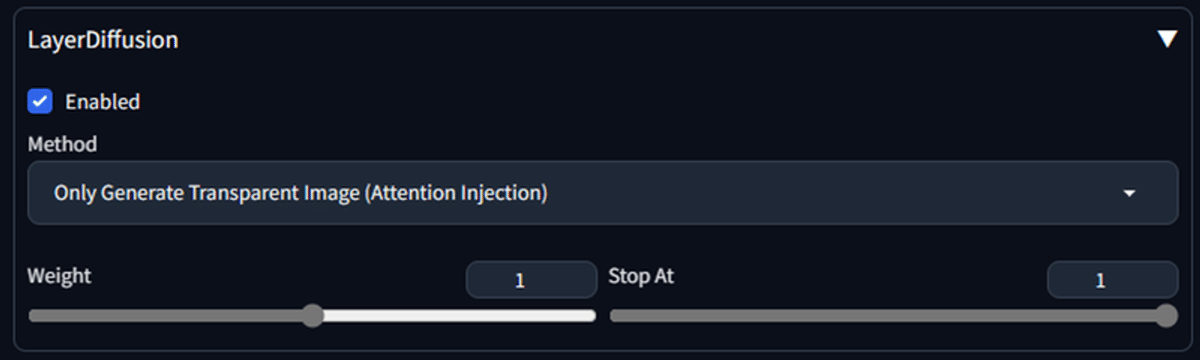
また、以前にもお話しした通り、Stable Diffusionをこちらのメニューを展開して、チェックボックスにチェックを入れるだけで、簡単に背景が透明な画像(透過画像)を作ることができます。
(画像)
LayerDiffuseで使用することができるモデルについて紹介!
なお、LayerDiffuseで使用することができる学習モデルは以下のようになります。
このようにSD 1.5とSD XLでできることが違うみたいですね。こちらに関しては執筆時点でのものになるので、今後アップデートなどがあればさらに便利になるかと思います!
(画像)

ちなみに、簡単に上記の学習モデルについてまとめると以下のようになります。
SD1.5モデル
透明画像のみ生成(Attention Injection)
前景から背景を生成(バッチサイズ2が必要)
背景から前景を生成(バッチサイズ2が必要)
全てを一緒に生成(バッチサイズ3が必要)
SDXLモデル
透明画像のみ生成(Attention Injection)
透明画像のみ生成(Conv Injection)
前景からブレンド画像を生成
前景とブレンド画像から背景を生成
背景からブレンド画像を生成
背景とブレンド画像から前景を生成
透明画像のみ生成(Attention Injection)
こんな感じで、SD 1.5とSDXLではできることが違うのがわかりますよね!
LayerDiffuseで、内部的にインストールされる学習モデルについて
LayerDiffuseでは、上記の学習モデルを選択して画像生成を行う際、学習モデルがインストールされていない場合は自動でインストールされます。
この時にインストールされる学習モデルを簡単に説明すると、以下のようになりますので、クラウド環境で容量を整理したい方などは覚えておくと便利かと思います!
layer_xl_transparent_attn.safetensors
SDXLを透明画像ジェネレータに変換するためのランク256のLoRAモデル
モデルの潜在分布を、特別なVAEパイプラインでデコード可能な「透明な潜在空間」に変更
この記事が参加している募集
この記事が気に入ったらチップで応援してみませんか?