
書類をスキャンして作成したPDFの文字検索をできるようにする:Acrobat活用術

書類をスキャンする時に「PDFファイル」として保存すると、PDFに対応したアプリで開けるようになり、活用の幅が広がります。ただしこの段階ではデータは画像として保存されていますので、文字検索ができません。
Adobe AcrobatはOCR機能で画像から文字を認識してテキストとして保存できますので、文字検索ができるようになります。ページ数や文字量が多い書類、文字検索ができるととても便利です。
OCRでテキスト認識する
書類をスキャンしてPDFで保存すると、デジタル化で劣化を防ぎ、保存も楽になります。またメールやアプリケーションに添付できるなど活用の幅が広がります。ただしスキャンしただけの状態では、データは画像ですので文字検索ができません。
Adobe AcrobatのOCR機能を使うと画像から文字を認識して、ファイルにテキストを埋め込むことができます。テキストの情報があれば文字列検索ができるようになり、必要な情報を見つけやすくなります。特に文字量やページ数が多い書類を扱うときに便利です。
それではOCR機能を使ってみましょう。スキャンしたPDFを開き、すべてのツールパネルにある「スキャンとOCR」を選択します。ここで「このファイル」をクリックし、「テキストを認識」ボタンをクリックします。


OCR機能を実行するページを指定する場合は、「ページ」のドロップダウンリストからページや範囲を指定します。
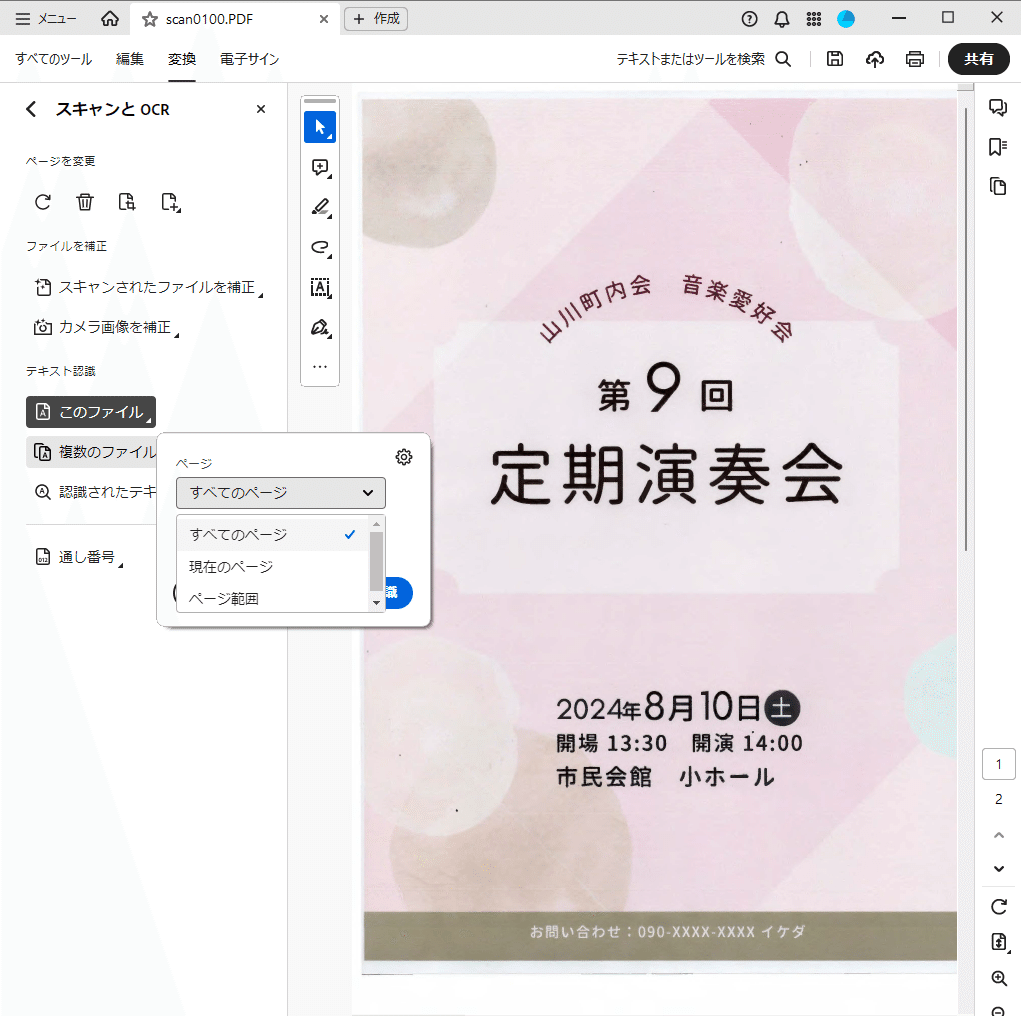
なお、ページ数や文字の量によって、処理にかかる時間が変動します。処理の進行状況は画面下から確認できます。
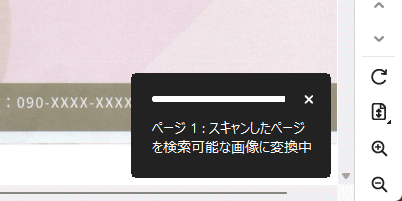
OCR処理が終わると、検索窓から文字列検索ができるようになります。
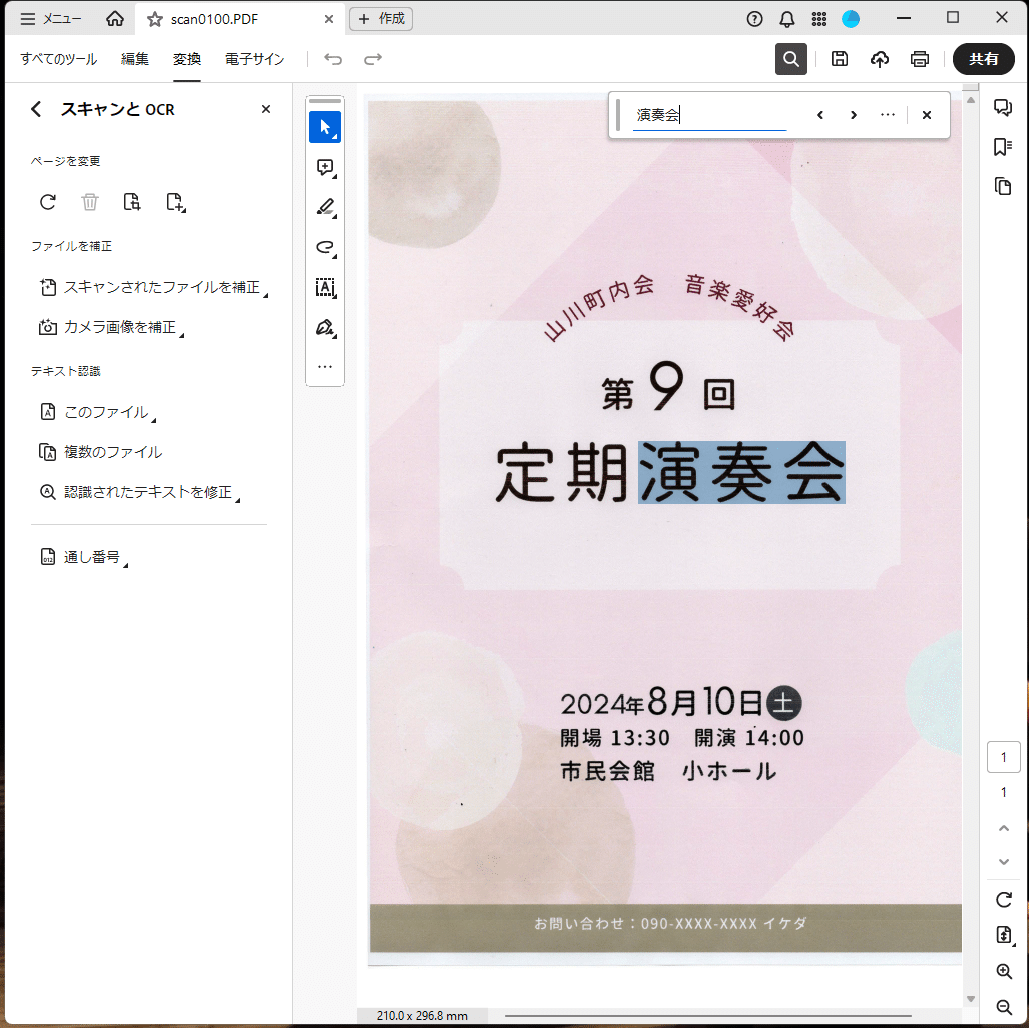
認識されたテキストを確認する
特殊なフォントやスタイルが施されている文字ですと、誤認識やエラーが起きる場合があります。文字列検索でキーワードがヒットしない場合、OCR機能でテキストがどのように認識されたかを確認してみましょう。先ほどと同じく、すべてのツールパネルにある「スキャンとOCR」を選択し、今度は「認識されたテキストを修正」をクリックします。すると、誤認識の可能性がある部分に、認識されたテキストが赤枠で囲われた状態で表示されます。
誤認識された文字は、赤枠の該当部分を選択したうえで、「認識」のテキストボックスに正しい文字列を入力して「確定」をクリックすることで修正することができます。
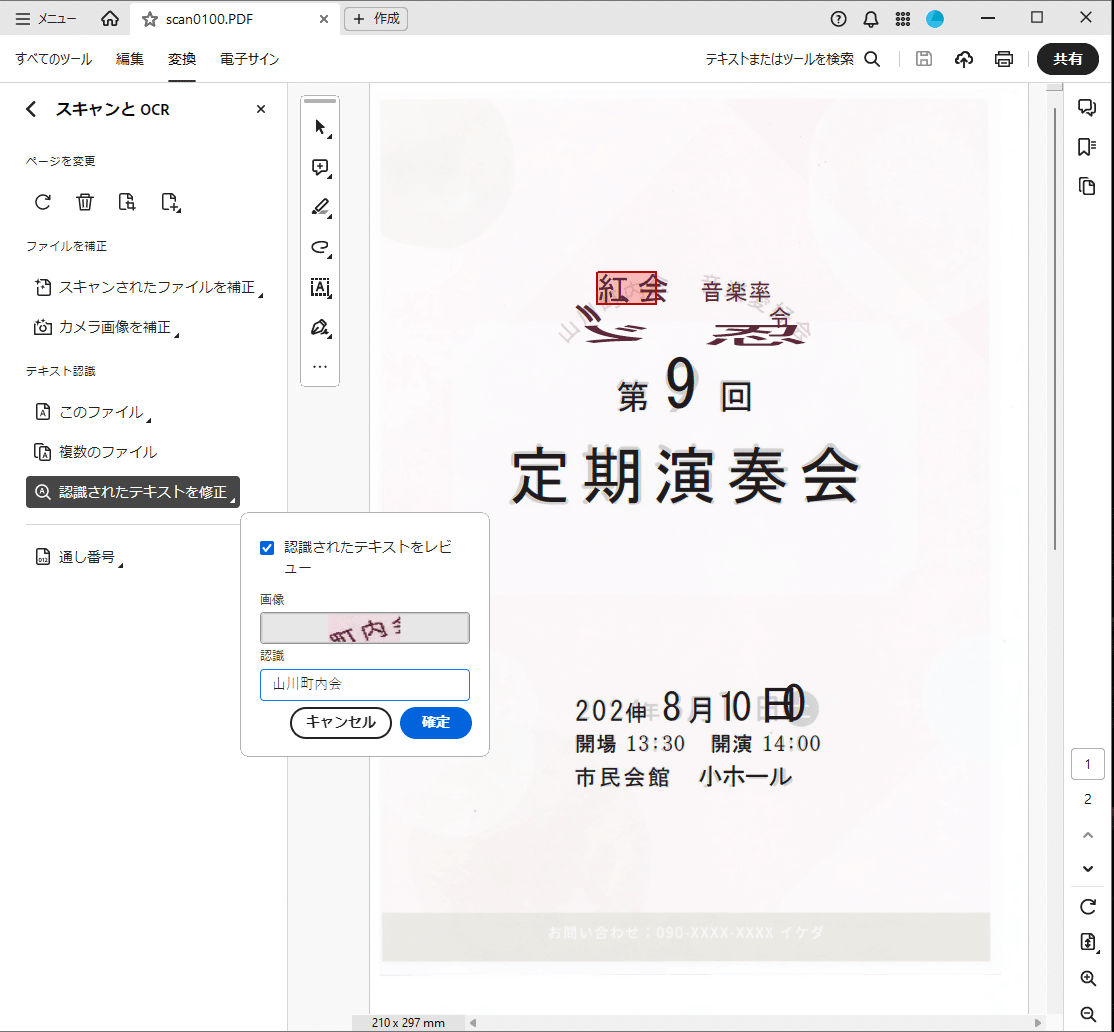
紙からのスキャンですと認識や修正に限界があるものの、文字列検索ができるようになるととても便利です。スキャンした書類なら、テキスト認識をしておきましょう。上記画面にある「複数のファイル」から複数のPDFファイルをまとめて認識することもできます。
より詳しくお知りになりたい方は、チュートリアル記事をご覧ください。