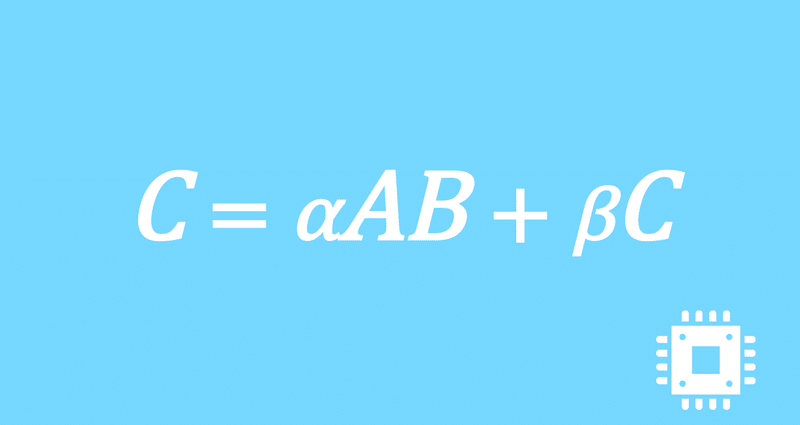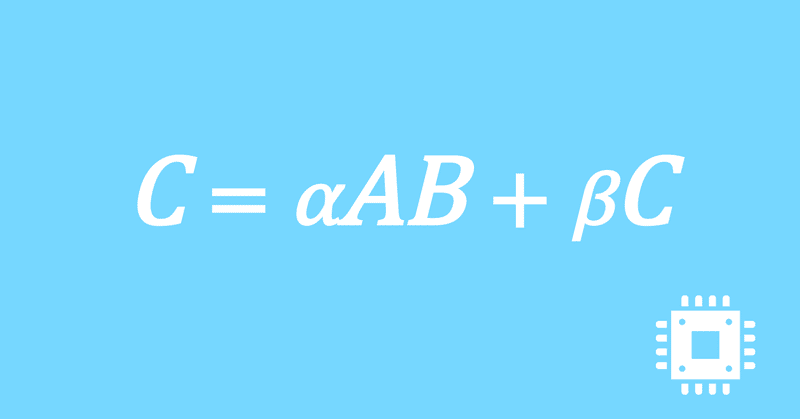ループ交換2回目|行列積高速化#10
この記事は、以下の記事を分割したものです。
[元の記事]行列積計算を高速化してみる
一括で読みたい場合は、元の記事をご覧ください。
さて、カーネル関数を切り出したため、myblas_dgemm_main関数はだいぶスッキリしました。
// scaling beta*Cblock2d_info_t infoC = {M,N,1,1};myblas_dgemm_scale2d(beta,C,ldc,&infoC);double* A2 = calloc( MYBLAS_B