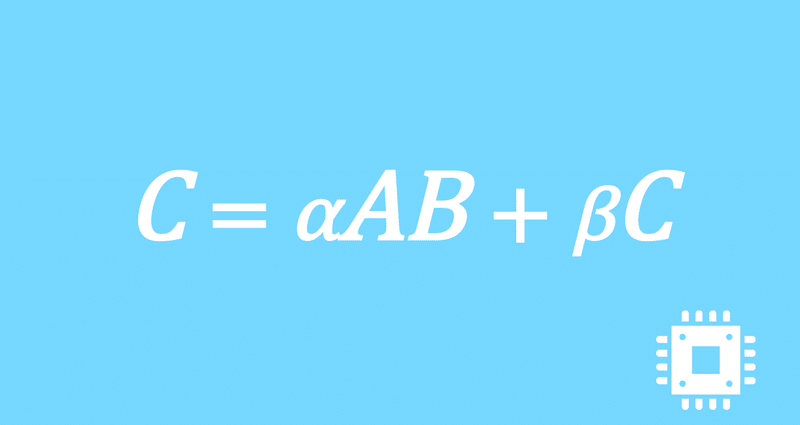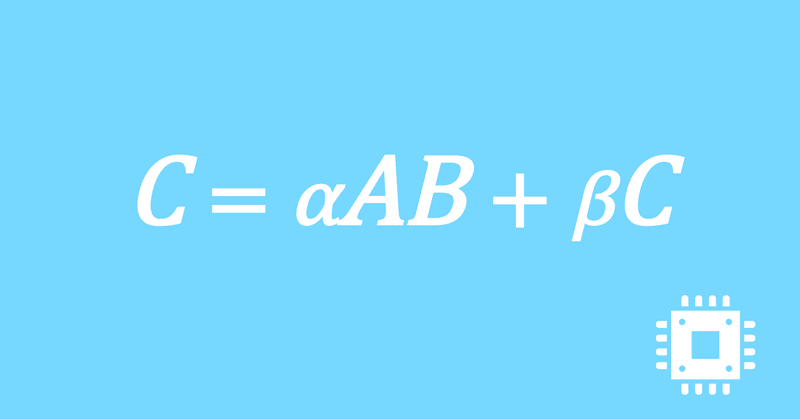ブロッキングサイズの改良|行列積高速化#26
当初の設計(下記の記事)では、I,J,Kループのキャッシュブロッキングサイズは、キャッシュメモリの容量に収まるように決めました。
しかし、L1キャッシュブロッキングの有無がカーネル関数の性能を左右していたため、性能実測しながらL1~L3のブロッキングサイズを変更することにしました。前回の記事のカーネル関数の性能は、ブロッキングサイズ改良後の測定値になります。
改良したブロッキングサイズ当初の設計では、キャッシュメモリのブロッキングサイズを下記のように設定していました。