
- 運営しているクリエイター

記事一覧

noteがやるべきSEO対策を調査しました
Twitterで「noteがやるべきSEO対策」を求めていたので調べてみました。
ただ、note.muを使ったことがなかったので、調査も含めてアカウントを作成してみました。シンプルな画面設計なので迷いが少ないUIですね。最初記事を投稿したときはシンプル過ぎて戸惑ってしまいましたが、記事を一つ投稿したら慣れることができました。
note.mu利用前のSEOイメージnote.muのコンテンツはAn

クローラーブロック対策、robots.txt以外でクローラーを拒否する方法(.htaccessなど)
クローラーのアクセスは意外と多く、サイトによっては人間のアクセスを超える場合もあります。ちょっと具合的な数字は出しづらいのですが、弊社の管理サイトではクローラーのアクセスが人間のアクセスよりも約4倍のサイトや約9倍のサイトがあります。事業によってはそのクロールがサーバー負荷を高めるので拒否したくなりますね。まずはその方法から。
①robots.txtでクローラーを拒否する
robots.txtに
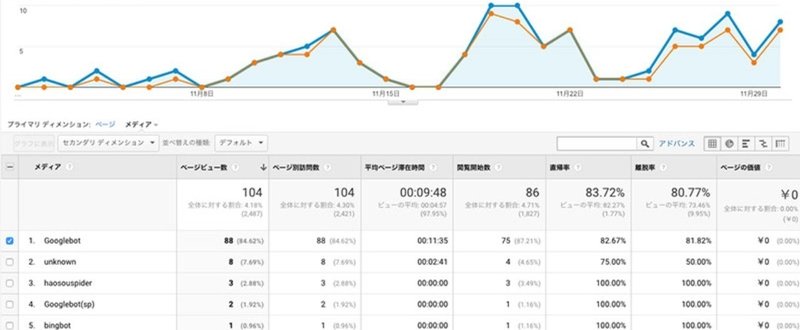
![[SEOクローラー対策]どのクローラーがrobots.txtの指示を無視しているのか?](https://assets.st-note.com/production/uploads/images/5864533/rectangle_large_07807d05bf63021f2e35c4e2ef1ff41f.jpg?width=800)
[SEOクローラー対策]どのクローラーがrobots.txtの指示を無視しているのか?
インターネットの世界では検索エンジンを始め、SEOツールなど多種多様な目的でクローラーが徘徊し情報を収集しています。法律の専門家ではないので正しい解釈ではないかもしれませんが、ウェブ上でクローラーがコンテンツを収集するスクレイピング自体は問題ありません。以前、某図書館の蔵書検索システムを使いやすくするためのシステムを開発した方が逮捕されるという事件もありましたが、最終的に不起訴となりました。
ウ