
クローラーブロック対策、robots.txt以外でクローラーを拒否する方法(.htaccessなど)

クローラーのアクセスは意外と多く、サイトによっては人間のアクセスを超える場合もあります。ちょっと具合的な数字は出しづらいのですが、弊社の管理サイトではクローラーのアクセスが人間のアクセスよりも約4倍のサイトや約9倍のサイトがあります。事業によってはそのクロールがサーバー負荷を高めるので拒否したくなりますね。まずはその方法から。
①robots.txtでクローラーを拒否する
robots.txtにクローラーのUA(ユーザーエージェント)を記述して拒否します。以下は一例。robots.txtの仕様に準拠しているクローラーはその指示に従い、クロールをしなくなります。
User-agent: Googlebot
Disallow: /
②.htaccessでクローラーを拒否する
.htaccessではUAまたはIPアドレス、ホスト名でクローラーを拒否できます。まずはUAでクローラーを拒否する方法です。
SetEnvIf User-Agent "Googlebot" deny_ua
order allow,deny
allow from all
deny from env=deny_ua
大手検索エンジンはUAを明示していますが、UAは偽装できるのでこの場合は.htaccessでIPアドレスを拒否します。そのIPからのアクセスができなくなるので、当然慎重に進めないといけませんね。
order allow,deny
allow from all
deny from xxx.xxx.xxx.xxx
※xxx.xxx.xxx.xxxはIPアドレス
ちなみにGoogleはクローラーのIPアドレスを公開していません。そしてIPアドレスは変わる可能性があります。詳しくはこちらをご覧ください。
▼GooglebotのアクセスをIPアドレスで確認するときには注意が必要、DNSリバースルックアップを使う
https://www.suzukikenichi.com/blog/using-reverse-dns-lookup-to-verify-googlebot/
未知のクローラーに対する防衛方法は?
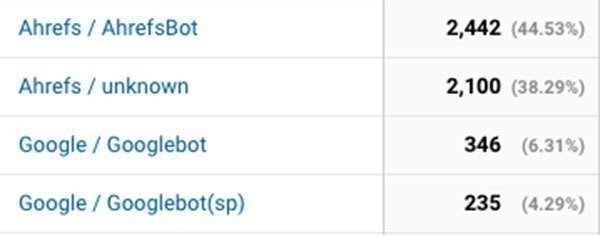
前述はクローラーが適切に情報を発信してくれる場合に有効です。しかし中には情報を隠してクロールするものもあります。弊社ではクローラーによるクロールを解析していますが、Googlebotを偽装しているクローラーや情報不明なクローラーもあります。情報不明なものはデータを蓄積しておくと対処が考えられます。備えあれば憂いなしですね。
ちなみに某SEOツールのクローラーも結構あります。Googlebotと比較しても桁違いであったりします。データを収集するのは構わないのですが、もう少し考えてほしいものです。
このnoteは株式会社Webの間のコラムの転載です。オリジナル記事はこちら。
クローラーブロック対策、robots.txt以外でクローラーを拒否する方法(.htaccessなど)
この記事が気に入ったらサポートをしてみませんか?