
データサイエンティスト検定 リテラシーレベル(DS検定)受けてみた

2025年1月8日合格発表がありましたので「データサイエンティスト検定(DS検定)受けたみた」です。


受検の動機
一つ目は、部長になって三部署目、そしてその期間も10年以上が経ち、ますます様々なデータを扱うことが増えたからです。部下にデータ整理を任せることはできますが、分析はいまいちのため、結局自分で行う必要があり、業務が増える一方です。データ分析を教えるにしても、体系的にどう教えるかまでは分からないので、自分自身の学びが必要でした。
二つ目は、「DX推進パスポート3」のバッジが欲しくなったからです。
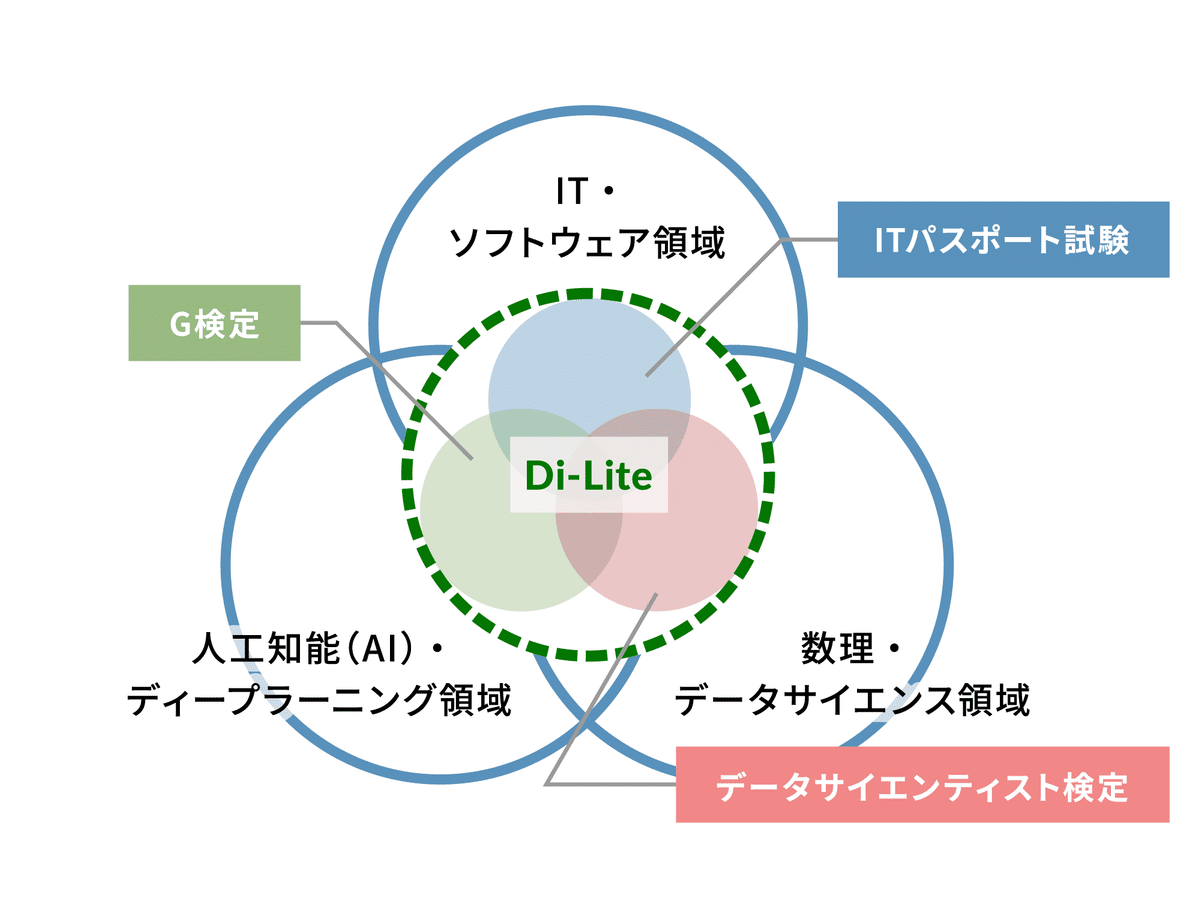
これはデジタルリテラシー協議会が定義する「IT・ソフトウェア領域」「数理・データサイエンス領域」「AI・ディープラーニング領域」の3領域において、全てのビジネスパーソンが持つべきデジタル時代の共通リテラシー「Di-Lite」を示すものです。
具体的には、ITに関する基礎知識を問う「ITパスポート試験」、データサイエンスの知識を問う「DS検定リテラシーレベル」、AI・データの知識を問う「G検定」の3試験が推奨されています。「DX推進パスポート」は、「ITパスポート試験」、「DS検定リテラシーレベル」、「G検定」の3試験に合格した人に与えられるバッジです。1個や2個でも申請できますが、やはり3個すべてを揃えてからと思っていました。情報という教科もあるぐらいなので、数年後の新入社員はこのぐらいのレベルの子が入って来るのだろうという意識を持つことが大事かなと。
受験後の当日の感想
2024/11/10 当日の受験後の感想
受験後の感想ですが、難しかったです。6割の合格ラインなら良いのですが、80%という高いラインでは不合格かもしれません。
内容的には基本的なことかもしれませんが、非IT系のビジネスパーソンにとっては、ちゃんと勉強しないとかなり厳しいと思います。
また「DX推進パスポート」の三つの試験の中でも、一番難しかったです。特に今年受けた基本情報処理試験よりも総合的に難易度が高いと感じました。一因として、合格ラインが高いためでしょう。一応80点だったので、ボーダーライン上にいます。年始明けの合格発表までドキドキしながら待ちます。
今回の試験はスキルチェックリストver.5の初試験でもあるため、もしかすると合格ラインが下がるかもしれません。とりあえず、今年の資格チャレンジはこれで終了です。
使用した教材
市販本を3冊利用しました。
①最短突破 データサイエンティスト検定(リテラシーレベル)公式リファレンスブック 第3版
いわゆる白本って呼ばれるものです。シラバスの内容ごとに簡単な説明がある。ほんと説明がほぼで最後の方に申し訳ない程度の問題が50問、ネット配信で100問あります。しょっぱなにこれ見て勉強できる人はすごいと思う。
ちらっと見たがまったく食指が動かなかった。ある程度勉強してから見るようになりましたね。
②データサイエンティスト検定[リテラシーレベル][徹底解説+良質問題+模試(PDF)] 最強の合格テキスト (まっすぐ合格シリーズ)
スキルチェックリストver.5対応の新発売ってことで、第一刷ですが正誤がいっぱいありありでしたね。出版社に何個間違えの指摘を送っただろうか。まぁしっかり正誤表に反映されて第二刷では対応していそうなので良しとしよう。こっちも勉強になったからね。青いから青本でしょうね。
さて内容ですが、いわゆる章立ててテキスト部があって演習問題がある普通のタイプのテキストです。ちょっと厚いですが、内容もわかりやすく説明してくれており理解を深めるにはよいです。私の勉強はこのテキストをメインに説明不足対応はいつもの生成AI(GPT4o&Copilot)でやっておりました。
③徹底攻略データサイエンティスト検定問題集[リテラシーレベル]対応
いわゆる黒本ですね。
残念ながらスキルチェックリストver.4までにしか対応していません。
ただ無いんですよ市販の問題集が・・・。
AMAZONのコメントとか正誤表の量が大量とのことでしたがさすがに販売して2年以上経っておりますのでそのあたりは修正済みです。ただ人工知能関係は弱いですね。問題もちょっと易しい感じします。
おまけ④合格対策 データサイエンティスト検定[リテラシーレベル]教科書
いわゆる緑本と言われるものです。
こちらは買いませんでした。理由はスキルチェックリストver.4までにしか対応していません。教科書タイプは青本購買したのでとりあえずこちらはパスしています。評判は良さそうです。
まぁ結局は本に載っていないことが問題に出てくるのですが・・・。
おまけ⑤gaccoのデータサイエンス講座
直接的にデータサイエンティスト検定の講座をしているわけではありませんが「データサイエンス」に関するオンライン講座が入門編からいくつかあり無料で受講できます。夏季休暇の時も受講しましたが入門としてはとてもよかったです。学習前にざっと受けておくとスムーズな学習ができると思います。
1週 この講義の概要とねらい
・データサイエンスとは
・公的データを入手する
・地域経済分析システム(RESAS)の利用
・政府統計の総合窓口(e-Statの利用)
・代表値
・標準偏差
・標準化
・ヒストグラム
・箱ひげ図
勉強時間
今回はある程度測っていました。10/1から始めて11/9まで11/10試験。
一日1時間ぐらいで週末は2時間はしていましたので50時間強ですね。
ただ、酒飲みながらとかしちゃっていたから質はよくないですね。
今年5つ目の試験ってことでちょい飽きてモチベーションが落ちていたのと、腰の調子もよくなかったのもありまして11/23(土)を設定していた試験日も前倒しして11/10(日)に受験しちゃいました。
一応「ITパスポート」2022年12月→「電気通信主任者伝送交換」→「生成AIパスポート」→「基本情報処理」2024年3月→「G検定」2024年5月→「一級土木施工管理技士一次検定」→「一級電気通信施工管理技士一次検定」→「DS検定」2024年11月という余計なものがいくつか挟まっているが王道の的な受験をしています。
結果
合格しました。合格ラインが前回の第7回(2024年6月実施)が76%、その前の3回~6回は79%が4回続いて初回と2回目が80%。
合格率を40%半ばで調整していると思いますので今回出題も変わったし合格ラインがわかりませんね。S
過去実施は更新されていないため今回のはわかり次第記載して更新予定。
白本利用時のアドバイス
通称白本の問題の解説は最小限です。この対策としては生成AIに解説をぶん投げるとよいです。例としてあげますと下記の白本からの模擬問題を1つ。
今回担当するプロジェクトでは、データサイエンスの専門家として 準委任契約の締結を勧められた。準委任契約に関する説明として、 次の中から最も適切なものを1つ選べ。
a. 準委任契約では、一般的に契約不適合責任を負う
b. 準委任契約では、業務の内容や成果物に対して完成の義務を負う
c. 準委任契約では、発注者が業務を管理できる
d. 準委任契約では、委任した業務の期間や工数に応じて費用が 支払われる
準委任契約では、業務の期間や工数に基づいて費用
が支払われるのが一般的です。よってdが正解です。
かなりさっぱりしています。該当ページみても答えの肢はともかく他の選択肢はそれほど詳しくはのっていません。そこで生成AIで解説まで依頼してい見ると例として下記が出力されます。
正解は、d. 準委任契約では、委任した業務の期間や工数に応じて費用が支払われる、だね。
準委任契約は、業務の完成ではなく、提供された時間や労力に基づいて報酬が支払われる契約形態です。他の選択肢も確認してみましょう
a. 準委任契約では、一般的に契約不適合責任を負うことは少ないです。契約不適合責任は、むしろ請負契約に関することが多いです。
b. 準委任契約では、業務の内容や成果物に対して完成の義務を負わない点が特徴です。完成義務は請負契約に該当します。
c. 発注者が業務を管理できる場合もありますが、それは契約の内容に依存します。準委任契約では、受託者が業務をどのように遂行するかについて、ある程度の裁量があります。
d. 準委任契約では、期間や工数に基づいて報酬が支払われるため、この選択肢が最も適切です。
どちらがわかりやすいかは一目瞭然とかと思います。この手の試験は答えの肢だけではなく他の肢の理解までが大事です。
また重要な対策ポイントは、模擬問題だけに依存しないことです。模擬問題を解くことは必要ですが、それだけに頼らず、基本的な理解と幅広い知識を身につけることが合格へのカギです。
公式教材(白本)をしっかりと読み込み、データサイエンスの基本概念やスキルを理解することが大切です。また、DS検定はスキル測定を目的とした試験であるため、出題範囲の知識をバランスよく学習することが求められます。特定の分野に偏らず、全体的な理解を深めていくことで、合格の可能性を高めると思われます。
頻出キーワード(おまけ)
CBT試験はもれなく試験問題出しちゃだめだよって規約があるため記載できないので教科書&問題集でも頻出問題って出されているキーワード。
頻出って書いてあるところは問い方が書籍と違いますが概ね出ている感じでした。
混合行列
きちんと意味を理解する。雰囲気ではいけない。
$$
\begin{array}{|l|c|c|} \hline & \text{予測:陽性} & \text{予測:陰性} \\ \hline \text{実際:陽性} & \text{True Positive (TP)} & \text{False Negative (FN)} \\ \hline \text{実際:陰性} & \text{False Positive (FP)} & \text{True Negative (TN)} \\ \hline \end{array}
$$
$$
\begin{array}{|l|c|c|} \hline & \text{実際:陽性} & \text{実際:陰性} \\ \hline \text{予測:陽性} & \text{True Positive (TP)} & \text{False Positive (FP)} \\ \hline \text{予測:陰性} & \text{False Negative (FN)} & \text{True Negative (TN)} \\ \hline \end{array}
$$
適合率(Precision)
$$
\text{Precision} = \frac{TP}{TP + FP}
$$
語呂合わせ:「プリンセスの正確な予測」
式の語呂:「TPをTP + FPで割る」 → 「TP(当たった予測数)をTP + FP(当たった予測数と間違った予測数の合計)で割る」
再現率(Recall)
$$
\text{Recall} = \frac{TP}{TP + FN}
$$
語呂合わせ:「リカちゃんが再現」
式の語呂:「TPをTP + FNで割る」 → 「TP(実際に当たった数)をTP + FN(実際に当たった数と見逃した数の合計)で割る」
協調フィルタリング・コンテンツベースフィルタリング
$$
\begin{array}{|l|c|c|} \hline & \text{協調フィルタリング} & \text{コンテンツベースフィルタリング} \\ \hline \text{推薦基準} & \text{ユーザーの行動・評価} & \text{アイテムの特徴} \\ \hline \text{主な方法} & \text{ユーザーベース、アイテムベース} & \text{アイテムのキーワード、属性} \\ \hline \text{データ必要性} & \text{ユーザーの評価データが必要} & \text{アイテムの詳細な特徴データが必要} \\ \hline \text{新規アイテム対応} & \text{データがない場合は推薦困難} & \text{特徴さえあれば新規アイテムも推薦可能} \\ \hline \text{計算コスト} & \text{多ユーザー・アイテムで高コスト} & \text{アイテム特徴次第で低コスト} \\ \hline \text{多様性} & \text{類似ユーザーやアイテムに依存} & \text{ユーザーの過去の好みに依存} \\ \hline \text{利点} & \text{ユーザーの嗜好を反映しやすい} & \text{新しいアイテムも簡単に取り扱える} \\ \hline \text{欠点} & \text{新規ユーザーやアイテムに弱い} & \text{ユーザーの好みを過度に反映しやすい} \\ \hline \end{array}
$$
標準化
標準化は、異なる尺度を持つデータを同一の尺度に変換する操作です。これにより、異なる変数間での比較が容易になります。標準化の方法の一つとして、平均を0、標準偏差を1にする方法があります。具体的には、以下の式で計算されます
$$
z = \frac{X - \mu}{\sigma}
$$
・z は標準化された値
・X は元のデータ
・μ(ミュー) はデータの平均
・ σ(シグマ)はデータの標準偏差です。
分散
分散は、データのばらつきを示す指標です。データが平均値からどの程度広がっているかを示します。分散は以下の式で計算されます
$$
\sigma^2 = \frac{1}{N} \sum_{i=1}^{N} (X_i - \mu)^2
$$
・σ^2 は分散
・Xi は個々のデータポイント
・μ はデータの平均
・N はデータの総数
分散が大きいほど、データのばらつきが大きいことを示します。
不偏分散
不偏分散は、母集団の分散を推定するための方法で、標本の分散に補正を加えたものです。不偏分散を求めるためには、分母として標本サイズ NN ではなく N−1N-1 を使用します。これにより、標本分散の推定が偏りのないものになります。
$$
s^2 = \frac{1}{N-1} \sum_{i=1}^{N} (X_i - \overline{X})^2
$$
s^2 は不偏分散
N は標本サイズ
Xi は個々のデータポイント
X‾は標本平均
標準偏差
標準偏差は、分散の平方根を取ることで得られる値で、データのばらつきの程度を直接的に示します。標準偏差は以下の式で計算されます
$$
\sigma = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (X_i - \mu)^2}
$$
・σは標準偏差
標準偏差は分散よりも直感的に理解しやすく、データの広がりを示す指標としてよく使用されます。
まとめ
標準化: データを同一尺度に変換し比較を容易にする。
分散: データの平均からのばらつきの程度を示す。
不偏分散: 母集団の分散を推定するために、標本の分散に補正を加えたもので、分母に N-1 を使用する。
標準偏差: 分散の平方根を取り、データのばらつきの程度を直感的に示す。
