
ポーカーAI開発 part7 ~スタッツを報酬に加えてうまくいった話~

こんにちは!ナガメ研究所です。人を楽しませるポーカーAIの開発をしています。今回は、前に書いたpart4の記事の続編です。よろしくお願いします。
はじめに
前回、WTSDという、ポーカーのプレイ傾向を指す指標を元に、AIの学習をコントロールできないか試しました。結果は芳しくないとまとめましたが、今回は手応えを感じたのでその続編です。AIの学習方法やこれまで何をしてきたかなどの細かい話は前回の記事をぜひご覧ください。
WTSDを報酬に加えた前回のアプローチとの相違点
注意!この記事で話す「WTSD」は、フロップ以降のフォールド割合を示しています。本来の意味とは異なるのでご了承ください。
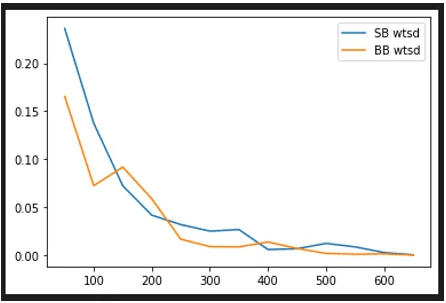
前回のグラフを以下に示します。縦軸がWTSD率、横軸が学習の進み具合です。
フロップ後にfoldを1回するごとに0.05加算し、上限0.5まで報酬を追加します。この値に、勝利した場合はさらに+0.5します。負けた場合は-1です。
セルフプレイは報酬が-1or1となる必要があると何かの記事でみましたが(曖昧)、報酬がAIのアクションで変動してしまっています。これが良いのか不明です。
グラフの曲線をみると、学習が進んでいってもWTSD値が向上するような行動を獲得できていないことが分かります。
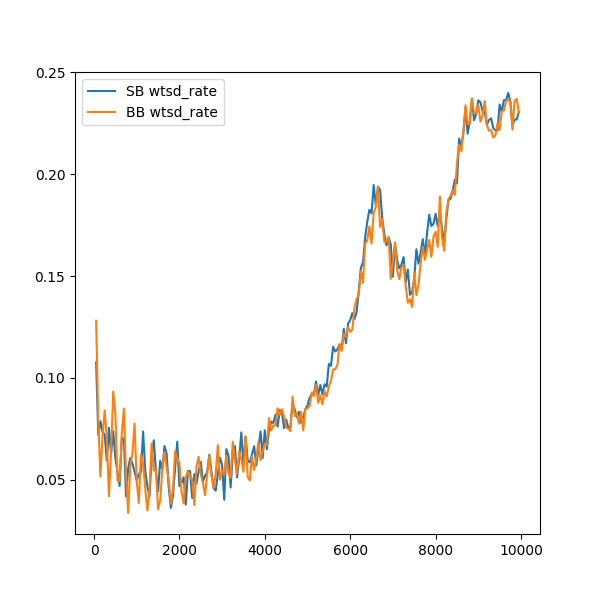
次に、学習環境を変更し、再度同じ報酬設計で試したのが以下になります。
主な相違点は以下です。
・ゲーム中、固定だったポジションを交互に変化させた。
これは、通常のゲームでは当たり前のことですが、常にSBだけをやり続ければSBの勝ち方を学習するのではないかと考えていました。結果から言うと、間違いだったようです。これは強化学習でも機械学習でも基本ですが、なるべく要素はランダム・均等にして入力することで、学習がうまくいく場合があります。
・学習率を0.001→0.0001に変更
学習率とは、AIモデルのパラメータを更新する幅のようなものと捉えてください。失敗したと思った行動も、長い目で見れば良かったかもしれません。学習率が高いと、失敗したらもうやらない!といった極端な学習に陥ったり、学習が安定しません。逆に小さすぎると、なかなか正解の行動を学習できなかったり、学習に時間がかかりすぎたりします。この値は、学習環境を変えたら常に適正な値を検討し続ける必要があると思います。
・学習を沢山回した
上記の変更前も沢山回したのですが、WTSDが下降しっぱなしだったので止めてしまっていました。前回より15倍ほど時間をかけて学習を行ったところ、徐々にWTSD値が上昇していきました。このグラフは、1GPU(RTX 3090)で約24時間ほどです。CPU計算部分がボトルネックになっているので、あまりGPUの性能は関係ないかも・・・。
考察のようなもの
スタッツを報酬に加えることで、学習をコントロールできることが分かりました。WTSDをどれくらい報酬に加えるかは難しいところですが、今回の発見は大きな進歩だと思います。アグレッシブやタイトなどのプレイスタイルをコントロールすることで個性的なポーカーAIを作れそうです。
学習率に関しては、小さすぎる気もするので徐々に上げていって実験しようと思います。
おわりに
実験的にWTSDを加えましたが、他にも考慮すべきスタッツがいくつかあるので、複数組み合わせてみるのも面白そうです。
進捗がありましたらまた記事を書こうと思います。面白かったら、ぜひスキ・フォローよろしくお願いします!
この記事が気に入ったらサポートをしてみませんか?