
#14-S わかりやすく!信号検出理論

認知心理学の領域でたまにでてくる信号検出理論。名前と同様、内容も結構難しい。ネットで調べても難しい説明がならぶ…。
自分が学部の頃困ったので、同じような初学者へ向けて、なるべくわかり易い解説をします!ちょっと長いけど、読めばきっと全体像はつかめるはず!一般的な大学の心理系学部生ならこのくらい分かってれば十分、というレベルでの解説です。
なんのための理論か
この理論は「ある特定の信号が含まれているか否かを判断するプロセスをモデル化したもの」であり、そこから正確さに関わる指標とバイアスに関わる指標を算出する場合に使うもの。これら「指標」についてはあとで。例えば視覚探索課題でターゲットのあり・なしを答えるときや、短期記憶課題ですでにみた・みてないを答えるときのように、信号(ターゲット)の有無を判断する事態で使われる。つまり、解析したいデータが上記のようなパターンでない場合は不適な分析だと思っていい。
ちなみに、これは1950年代にレーダーシステムの通信工学的理論として考案されたもので、レーダーの性能(敵機とそうでないものを分別できるかどうか)を評価するために作られた。だから信号(敵機)あり・なしにの検出という事態を想定したものになってる。
つまり「検出すべき信号はノイズの中にある」という状況で用いられるものであり、その状態とノイズだけの場合とを弁別する能力を計測するのが目的なのだ。雑音の中に弱い信号が含まれているかどうかを判断する場合にどれだけ正しくその検出ができるかを知ることができる。
解析対象となり得るデータ
解析したいデータが上記のパターンのデータであるということは、以下の表が作成できるということ。

ここで、シグナル試行は、信号ありの試行。つまり「信号あり」と答えたら正答の試行。ノイズ試行は、その逆で信号がない試行。それぞれの試行でYES/NOの答えがありうるので、種類 × 反応は全部で4パタンになる。
当然、シグナル試行でYES(信号あり)って答えた場合が正解、NO(信号なし)って反応だと不正解になる。これはわかりやすい。一方で、ノイズ試行に目を向けた場合は、YES反応だと不正解、NO反応で正解となる。シグナル試行とノイズ試行での正解・不正解は意味が違うため、別々の名前をつける。それが表の内部にあるhit, miss, false alarm, correct rejectionである。
理論的な前提
信号検出理論の前提として、物理的刺激は被験者の内部でその強度に対応した1次元の心理量に変換されるとする。簡単に言うと、呈示された刺激はどんなものでも「心理量」という強さに変換され、その「心理量」は1つの刺激につき1つの値をとります、ということ。
例として、すごく単純化した視覚探索課題があったとします。この課題は羅列された「0」の中に「O」があるかないかを答えるもの。
刺激1「0000000000」
刺激2「0000000O00」
刺激1には「O」はなくて、刺激2にはある。つまり刺激1はノイズ試行で2がシグナル試行。すべての刺激が心理量に変換されるので、刺激1が心理量10だったとすると(値は適当)、刺激2は13くらいになる(値は適当)。なぜなら2はターゲット「O」分が刺激1に加算されているから。つまり心理量は基本的に ノイズ試行 < シグナル試行 となる。
これが理解できたら、次は心理量の誤差について。人間は機械じゃないので、刺激→心理量の変換には常に誤差が生じる。例えば、様々な強さの光を何度も見せられ、その明るさを1-100で回答する課題だったとしよう。その中で、たとえ同じ強さの光が何回かでてたとしても、その回答はきっとばらつくだろう(ある強さの光に対して、明るさを20と回答したり、25と回答したりすることは当然あるだろう)。物理量が一定でも、我々は常に一定の心理量を与えられるとは限らないのだ。その結果が誤差となって現れる。
そして、この誤差は正規分布をとるとする。また、その分散はノイズ・シグナルそれぞれの試行で等分散であるとする。次のセクションで説明する。
ノイズ分布・シグナル分布
ここまで理解できたら、下記のグラフがかける。

横軸は上記で述べた「心理量」、縦軸はその頻度。この図が最も重要で、最もわかりにくいところだろう。わかりやすく説明してみる。
ある刺激が呈示されたとき、それがノイズ試行であれシグナル試行であれ、ヒトの頭(心)で処理されるときに心理量に変換される。心理量は1つの値であり、大小関係がある(一次元)。ノイズを呈示されたときは小さい方の心理量が多く、左側に集まる。シグナルが含まれていれば心理量は大きく、右側に集まる。この図はノイズ試行とシグナル試行を何度も呈示し、その心理量の生起頻度を図示するとこうなるよ、というもの。
この図には2つの分布があって、同じ形をしている。これは正規分布と呼ばれる。これは統計で登場する分布のまさに基本で、いろいろなデータが正規分布することが知られている。例えばその辺を歩いている男性(女性)の身長を測って、横軸身長、縦軸頻度(人数)でプロットすると正規分布になる。まんなかのピークが平均で、だいたい170(女性なら160)くらい?平均あたりの人数が多いくて、もちろんすごく高い人も低い人もいるけどその数は少ない、という分布。統計学・数学的にもとても優れた性質を持っているけど、もっと知りたい人は本格的な統計学のテキストを。
信号検出理論ではN分布もSN分布もこの形になるよって前提のもとなので、こういう図がかけるわけ。
では判断基準の話。この理論が説明する事態では、被験者はYESかNOの反応をしている。ちゃんと課題をこなしていれば、被験者はこの心理量に基づいてYES・NOを回答するだろう。心理量は1次元(1つの値)なので、ある基準より大きければYES、小さければNOと答える(しかない)。その基準が判断基準である。
信号検出理論の本丸
d' (d-prime, ディープライム)
つまり、図1の判断基準の縦線より右に来ている分布は被験者はYES反応を示すもので、左がNO反応を示す。てことは分布の曲線に正解か不正解を割り当てることができる。しかも単純な正解・不正解ではなく、表1に示した4種のパターンを割り当てられる。

図2では、表1のhitはピンク、missが黄色、false alarmが水色、correct rejectionがオレンジで書かれている。判断基準より右がYES、左がNO反応で、N分布は信号なしの刺激、SN分布は信号ありの刺激に対応しているということがわかっているので、上記の割当は問題なく理解できるだろう。
そして、ここまで書ければ信号検出理論における重要指標であるd'(ディープライム)を理解する準備は万端。図で書くととても簡単で…

これ。N分布とSN分布のピーク(平均)の心理量の差がd'なのだ!どう?そこまで難しくないでしょ?このd'によって、その被験者の弁別力がわかる。つまりd’が小さいと弁別力は小さい、大きいと弁別力は大きい。どういうことか、図4がわかりやすい。
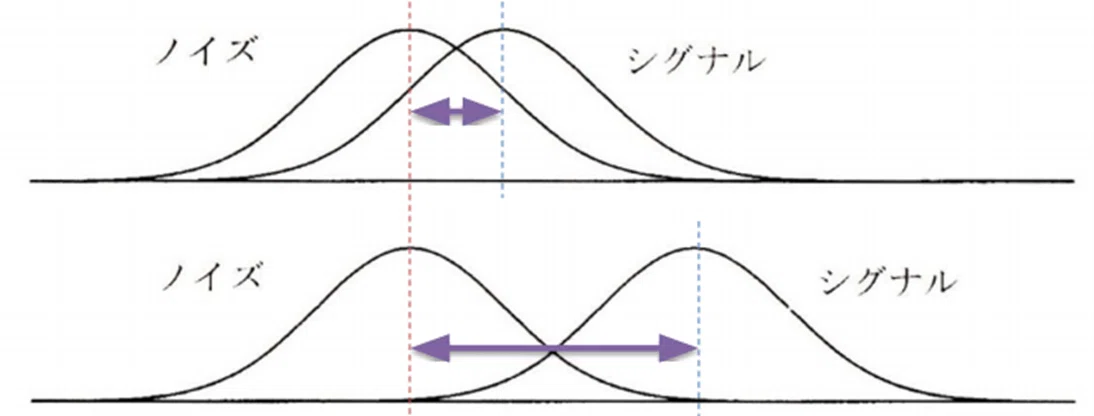
d'が小さいということは図4上のように、N分布とSN分布が近いことを示す。ということはノイズ試行とシグナル試行が心理量として結構交わっちゃってて、心理量だけではうまく分離できてない。つまり弁別できてない。一方でd'が大きいと当然ながらその逆で、心理量だけで十分に弁別ができているということになる。もちろん正答率は高い。
d’ = 0 とは刺激がない(あるいは全く認識できてない)ことで、d’ = 3 とは刺激がノイズ分布の標準偏差の3倍でありほぼ完璧な弁別ができていることを示す。
また、重要なのは正答率とは異なるということ。判断基準のことを思い出してほしい。正答率は判断基準の位置によって変動する。つまり、心のなかでは弁別できていても、判断基準がめっちゃ右側とか左側に来てしまうと、正答率は下がる。例えば、刺激があったような気が少しでもしたらとりあえずYES(あるいはNO)を押そう、というような方略をとった場合など。これを反応バイアスというが、d'は理論上正答率に拠らないので、バイアスのかかっていない弁別力を捉えられる。
ここから計算式***************************
このページの読者は手計算したいわけじゃないはずなのでざっと行きます。アスタリスクでくくったので、読み飛ばしても結構です。
各分布のピークの差分がd'であるが、これらのピークの値はデータとしては得られない。ここで、表1を再掲する。この4区分を思い出してほしい。解析したいデータからこの4つは計算できるといったが、よくみるとこの中で独立しているのは2つだけということに気づくだろう。
試行数は既知であるので、hitが決まればmissは決まるし、false alarmが決まればcorect rejectionは決まるのだ。この表の情報を短縮するとhit と false alarmの2つの値で表現できる。
この2つの情報から検出力のことを考えると、hitが高いときに高く、false alarmが高いときに低くなる必要がある。つまり、まず手元のデータから計算できそうなものとして「hit - false alarm」が考えられる。基本はこの考え方。d'は上記の正規分布の仮定を用いて、以下の式により求まる。
d' = z(hit)−z(false alarm)
z(hit)というのは、 Z変換のことで、hitの確率を正規分布における確率点に変換することを指し、N分布の標準偏差を単位とした値に変換する。z(hit)では、hit率が0.5 (50%)の場合はゼロになり、それ以上ならプラス、以下ならマイナスになる。そこからz(false alarm)を引くので、hit率が高くてfalse alarmが低い場合にd'が大きくなるという構造はそのまま、値がより洗練されたものになる。
以上がd'の計算式。*************************
β(ベータ)
d'はバイアスをなしにして、被験者の刺激弁別力を表現できる指標だと述べたが、βはそのバイアスの大きさを表現できる。図2を再掲する。
ここで、バイアスが無ければ、基準は2つの分布の真ん中(交点)にあるはずであるが、どちらかを多く答えていると、偏った位置にあることになる。これを表すには以下のような指標とすればよい。
β = 判断基準におけるSN分布の縦座標 / 判断基準におけるN分布の縦座標
これによって、偏りがなければ β = 1、N分布に偏っていれば β < 1、SN分布に偏っていれば β > 1という指標になる。

参考資料
たくさんの資料を参考にしました。作成者のみなさま、ありがとうございます!
http://cogpsy.jp/wp/wp-content/uploads/COGPSY-TR-003.pdf
http://www5e.biglobe.ne.jp/~tbs-i/psy/tsd/tsd.html
日本基礎心理学会 監修 (2018) 基礎心理学実験法ハンドブック
http://cogpsy.educ.kyoto-u.ac.jp/personal/Kusumi/datasem17/oh2.pdf
https://dictionary.apa.org/d-prime
https://nekomosyakushimo.hatenablog.com/entry/2017/09/09/000000
https://kassiopeia.exblog.jp/2655201/