

2024年3月の記事一覧




SD-webui-ForgeのブランチxDepth FM : paperspaceのコマンドと検証的なもの
最近、Forgeのアップデートがあまりありませんよね(2024/3末時点)。
Githubページを見ると、作者の方が非常に忙しいようです。これだけ優秀なアプリをたくさん開発出来る方ですから仕方がないのかもしれません。
そういった中で、他の方が作成したいくつかのブランチがあります。
その中で、新しいDepthプリプロセッサーを入れたブランチがあり、それを試してみるコマンドを作成しました。
修正点が


GiT: Towards Generalist Vision Transformer through Universal Language Interface
下記の文章は論文のアブストラクトをChatGPTに解釈させたものであり、正確性は保証しません。
本研究の背景について、詳しく説明してください。
本研究は、機械学習において、さまざまな視覚タスクを統一的に処理することができるモデルの開発を目指しています。これまでの研究では、大規模な言語モデル(LLM)が自然言語処理のタスクにおいて成功を収めてきましたが、視覚タスクにおいては、特定のモジュールが必要

Depthモデルの比較:2024/3時点
Txt2imgで、いくつかのDepthモデルを使用した際の比較をしてみたので、せっかくなので記事にしました。生成時間の比較がメインです。
参考になればと思います。
比較したDepthモデルは以下の5つです。正しい使い方ではないかもしれませんが、「diffusers_xl_depth_full」で全て行いました。これより小さいサイズだと生成時間は速くなると思います。精度が下がるかと思い(未検証)一番



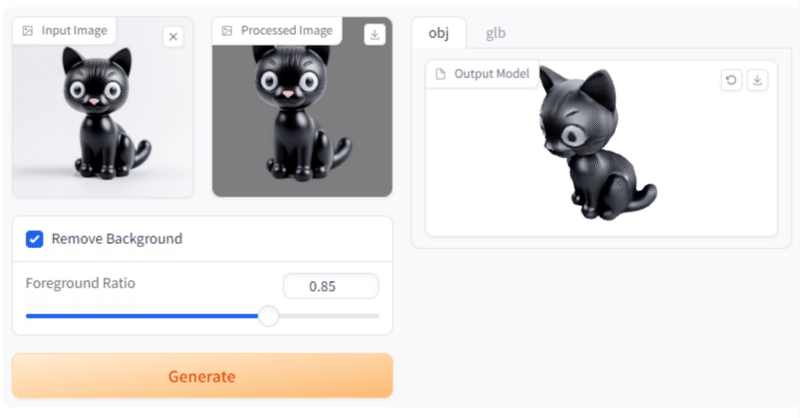
2D-to-3Dの「TripoSR」が話題になったので試してARで召喚してみたよ🐱
Tripo × Stability AI が公開した3D生成AIモデル「TripoSR」。
これが精度よく単一画像からの3Dオブジェクト生成をしてくれると話題になってたので早速試してみようと思います。
詳しくはweelさんの記事がとても分かりやすかったので貼っておきます!
インストール後の画面はこんな感じでした。
それではまずStable Diffusion Web UIで黒猫ちゃんを呼んで


「Depth Anything」: 画像と動画に新たな次元をもたらす革命的な深度推定ツール
私たちの生活には、革新的な技術が息吹を吹き込んでいます。特にAI(人工知能)の進化は、私たちが世界を理解し、それと対話する方法を根本から変えています。「Depth Anything」は、この技術の波に乗じて開発された、画像や動画から深度(奥行き)情報を抽出し、二次元データに三次元の豊かさを加えるオープンソースのAIツールです。
導入の詳細解説私たちの生活は、日々の技術革新によって大きく変化してい






Transformers.jsとDepth Anythingで2D画像を3Dへ 他 / Catch up on AI 2024.3.7
Pick up機械学習モデルをJavaScript環境で動作させることができるTransformers.jsとDepth Anythingを利用して制作された、2D画像を3Dへ変換するフレームワーク。
これがブラウザでできるのは色々と可能性を感じます。
https://x.com/taziku_co/status/1765545934317146165?s=20
オンラインデモ
Painti

2枚の写真から3Dシーンを構築「DUSt3R」 他 / Catch up on AI 2024.3.3
Pick up3Dシーンを生成するために今まで様々な角度からの入力画像が必要でしたが、DUSt3Rは最小2枚の画像から3Dシーンが生成できる新しいフレームワーク。
DUSt3R: Geometric 3D Vision Made Easy
Project:https://dust3r.europe.naverlabs.com
Code:https://github.com/naver/dust3

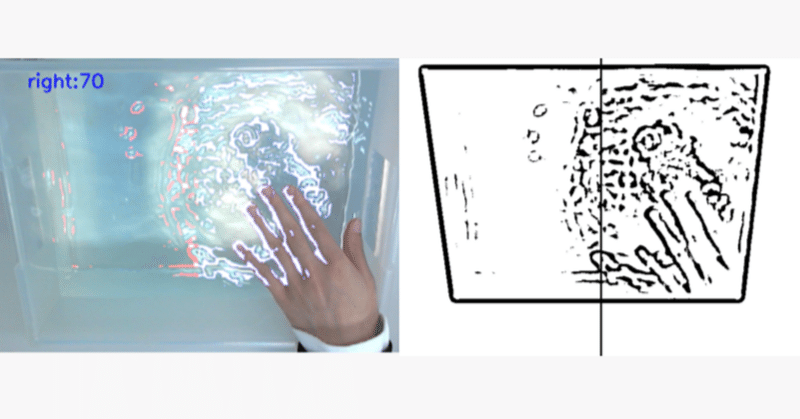
人間工学会で学会発表を行いました
令和5年12月1日(金)日本人間工学会九州・沖縄支部会 第44回大会で学会発表を行いました。
タイトル:画像処理を活用した水波紋インタラクティブ音響システム
URL:
https://www.ergonomics.jp/local-branch/kyushu-okinawa/ErgoKO44_4.pdf
抄録:
発表用資料:
動画:
