
『FABRIC』 : フィードバックベース画像Editor

こんにちはこんばんは、teftef です。今回はユーザーのお気に入り画像をフィードバックし、ファインチューン無しでその画像に寄った画像を生成してくれるツール「 FABRIC 」についてです。 FABRIC はユーザーのフィードバックを基に、LDMs にそのフィードバック情報を追加することでユーザーエクスペリエンスと出力品質を向上させています。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、GPT-4 による校正、修正が含まれています。
出典
人間による評価
生成された画像の品質を評価する指標として FID や CLIP Score などがあげられますが、これら評価指標は以前にも書いた通り、統計に基づいた機械的な定量評価であり、現在のモダンなモデルから出力された画像に対応した評価指標ではなくなっています。そのため、人間の感覚による評価指標が多く提案されています。
最近では、生成された画像の評価に人間の評価が使われ、人間の好みの画像と Prompt を学習する手法があります。またこれらの人間による評価を基に、 CLIP を学習(ファインチューン)し、人間の好みのスコア(HPS)を評価する分類器として扱うことに用いられたりしています。また定量評価指標として、ユーザーの好みをベースとしてた PickScore が提案されています。
好みの画像を出力するために
ユーザーの好き嫌いに応じた高品質な画像を生成するために様々な手法が研究されています。
ファインチューン
画像生成手法には GAN や VAE といった手法から始まり、拡散モデルをベースにした手法によって高品質な画像を短時間で生成することができるようになりました。しかし、これらの手法には学習データに含まれていない特定の概念を出力することが困難となっています。指定した、あるの概念を出力させるためには、その概念の画像をモデルに学習させるファインチューンを用いる方法があります。DreamBooth や Lora などは学習データとして指定した概念を持った複数の画像を用意し、ベースのモデルの重みをスタートにモデルのパラメータを更新します。それによって、モデルは新しい概念を強く学習することができます。
StyleDrop はユーザーが提供する画像の色、シェーディング、デザインパターン、局所的・全体的な効果などを捉え、人間、または自動化されたフィードバックを用いた反復的な学習を通じて画像の品質を向上させます。
強化学習
Text to Image を使用する際に、ユーザーは通常、プロンプトを思いつき、そのプロンプトで画像を生成し、結果を検討し、プロンプトを調整し、結果に満足するまでこのプロセスを繰り返します。この負担をなくす、Tang 等は、人間のフィードバックによる強化学習(RLHF)のような、ゼロ次最適化アルゴリズムを提案しています。人間のランキングフィードバックを使用して拡散生成モデルによって生成される画像の品質を改善することができ、既存のRLHFメソッドに対する有望な代替手段となっています。
学習をしない手法
これらはベースモデルに特定の概念の画像を再学習する必要があり、それなりの計算資源と時間を必要とします。何より、特定の概念の画像を複数枚用意する必要があるので、場合によってはその画像を用意することがネックになってしまうこともあります。
Textual Inversion は画像から意味的な Text 埋め込みを Inversion 処理を通じて探し出します。それを擬似的な Prompt として入力すると、指定した概念の画像を出力することができます。
Prompt-Free Diffusion では SeeCoder と呼ばれる手法によって、入力を意味ある視覚的埋め込みに変換します。変換された入力は、Text to Image の条件付き入力として利用され、高品質でカスタマイズされた出力を生成することができます。
FABRIC
これらファインチューンや Inversion といった手法は、高品質な画像を生成することができますが今回は人間のフィードバックをほぼリアルタイムで反映させるというモチベーションで FABRIC を提案しています。
Self Attention
LDMs 内の Unet に含まれる Self Attention は画像の各ピクセルが他の全てのピクセルとどの程度関連しているかを計算します。各ピクセルのクエリと他の全てのピクセルのキーの間の「一致度」(Attention Score) を計算し、SoftMax 関数を用いて正規化し、それを重みとしてバリューに乗算されます。 直感的には重みが画像内の他のピクセルに「注意を払う」ように学習しています。参照画像から追加のキーとバリューを追加することで、追加の情報を挿入することができます。(単純に画像を concat するだけではうまくいかないため、工夫が必要)
ControlNet の Refarence Only ではUnet の Self Attention にノイズ化した参照画像を通すことでその画像の概念が抽出された画像が生成されます。(非常に直感的に書いているので厳密にいうと間違っている。)

FABRIC では、生成された画像に対して、ユーザーがフィードバックとして、好みか嫌いかを評価します。好みの画像と嫌いな画像それぞれについて別々の Unet パスに Concat されます。画像を Self Attention に入力し、Attention Score を計算します。生成プロセスの各ステップで、どれだけ参照画像(フィードバック)が生成画像に影響を与えるかを制御するために好みか嫌いかによって重みを変更して、重みづけされ、バリューの重みとして計算されます。この際の重みは、参照画像の影響の強さを制御することも可能になります。

Refarence Only と異なる点として、ノイズ除去のステップに応じて重みをスケジューリングすることによって、ノイズ除去の一部のステップにのみフィードバックを含めることが可能になります。今回はノイズ除去過程の前半にフィードバックを取り入れることで最良の結果が得られました。
実行時間
注意すべき点として、参照画像からのフィードバックをU-Net のデノイズ処理に埋め込む必要があり、 Forward の計算時間が時間が大体2倍になります。さらに、Self Attention 層に追加のキーとバリューを concat することも推論時間を増加させ、必要なメモリのスケーリングがフィードバック画像の数の2乗に比例します。(メモリ効率の良い実装の注意が使用された場合は線形になります)
定量評価
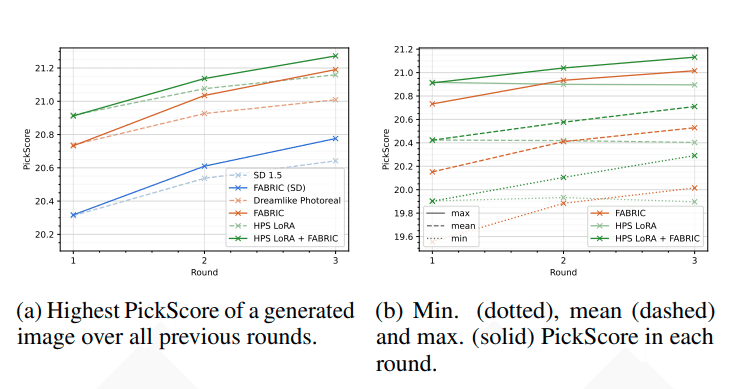
このように FABRIC はフィードバックを繰り返していくと PickScore が大きくなっているのがわかります。
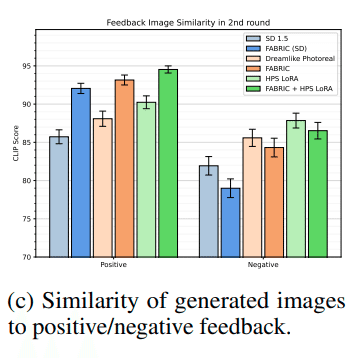
また、 FABRIC はCLIP Score において SD1.5 モデルや LoRA を上回ったことから、 望んだ Prompt に忠実な画像が生成されていることがわかります。LoRA と組み合わせることにで、より大きな効果があることがわかります。
定性評価

うーん、あんまりよくわからないので、自分で試してみます。
実験と使い方
今回はこちらの extention を使って実際に試してみました。
Hires.fix に適応する操作を忘れずに。

実験①
設定は上の通り
FeedBack は前半の 8割
Min weight : 0 , Max weight : 0.8
として
生成された画像が出てくるので、👍を選択します。
生成された画像をそのままフィードバックに使います。
つまり、一つ前の画像を参照する感じです。
結果①

だんだん色がくすんできます。また、 512 × 512 にしないとなぜか上図のように余白が出てきます。
実験②
今度は、参照画像を用意します。
FeedBack は前半の 8割
Min weight : 0 , Max weight : 0.8
Hiresfix をオンにして、 512 × 512 の画像を生成します。
Prompt は無難に 1 girl とします。Seed も固定します。

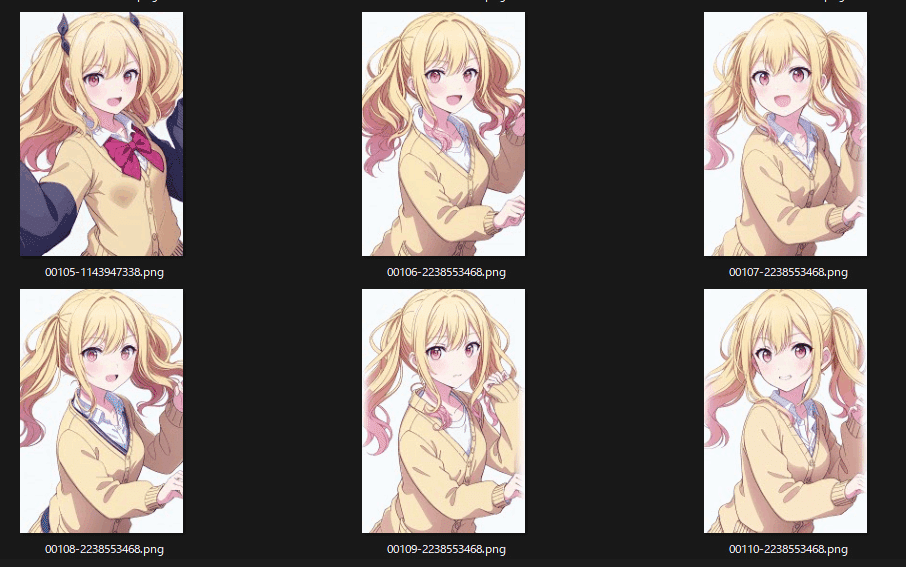
結果②
重みを上げすぎたのか、2枚目から画像が崩れてしまいました。Refarence Only とほぼ同じなので 1枚目が最もいい結果になるのは直感的にも自明な気もする。

実行時間はこのようにほぼ線形になっています。

実験③
今度は 👎を選択します。
実験条件はこのようにしました。少し重みが強すぎる気がしたので、前半 2割だけ、フィードバックし、重みも 0.2 に変更しましたが、…

結果③
うーん、わからん

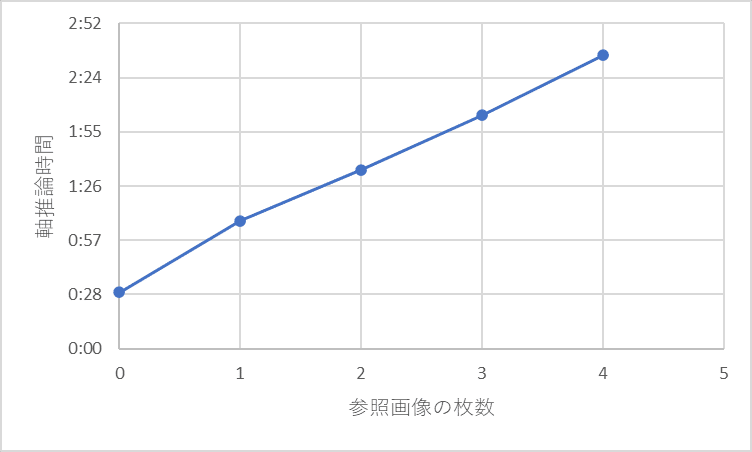
推論時間は線形
実験 ④
参照画像の多様性を増やします。
少し weight も変更します。

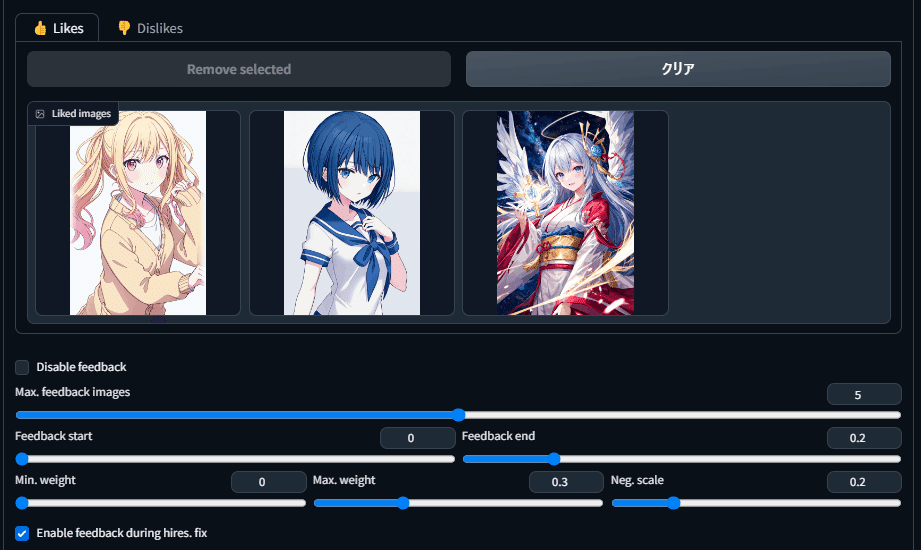
結果④
確かに混ざった画像が出てきましたが…
あまり実用的ではないかもしれない。

余談
画像サイズを 512 × 768 にして参照画像を6枚にすると、推論に 30 分かかり、画像がぶっ壊れました…

結論と考察
推論時間が線形になるのは予想通りで、1枚の画像につき、Self Attention の計算に用いられるためです。
参照画像1枚の場合は Controlnet Refarence only とほぼ同じ挙動をするのですが、それ以上、参照画像を入れると壊れます。 weight の取り方に最適値があったりするかもしれませんが、今回はそこまではやりませんでした。
一方で、実験④でわかるように複数の画像を混ぜることができており、論文の目的は達成されていると考えられます。
画像サイズが 512 × 512 に適応されているのは、実装上の不具合なのでしょうか?ちょっとわかりませんが、今度コードを読んでみます。(府不具合じゃないって思ってる。)
参考文献
最後に
最後まで読んでいただきありがとうございました。今回は ControlNet Refarence Only の派生版として FABRIC を紹介しました。正直、実用には少し物足りないような気もしますが、2~3枚の画像に対して、 weight を低くして適応すると効果が期待できるのかもしれません。
宣伝
最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(4500 字,teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
※注意 : 支援してくださる方へ
※注意 : ここから先は何も内容がありません。しかし、この記事をお読みいただき、良かったと感じていただけたのであれば、この記事と開発の支援お願いいたします!
ここから先は
この記事が参加している募集
この記事が気に入ったらチップで応援してみませんか?