
簡単に Stable Diffusion のモデルを試せる Google Colab の使い方ガイド (Ver2)

こんにちはこんばんは、teftef です。今回は Colab で動かす Stable Diffusion Ver2 の使い方についてです。
Stable diffusion の WebUI がGoogle Colab 上で警告が出るようになったため、 Diffusers 実装です。今回は大幅なアップデートとなっています。 前回の Version では Diffusers が用意した PipeLine を用いた画像生成なのですが、今回はほぼすべての モデルに対応した形となります。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。
それでは行きます。
Colab で動かす Stable Diffusion Ver 2 ↓
Stable Diffusion WebUI は非常にわかりやすく、多機能なローカル環境用のソフトですが、それを動かすだけの GPU が必要になります。しかし、初めて AI に触る方は GPU をお持ちでない方も多く、また多機能なためどこをどのように操作すればよいか、インストールの仕方などで苦労される方が多いと思います(主もそうでした)。そのためGPUがなくても、 URL をコピーしてボタンを数回だけ押すと画像が生成されるGoogle Colab のコードを作成しました。
Google Colab
Google Colab というのは Google が提供するクラウドベースの無料のJupyterノートブック環境です。要するにプログラミングをしてそれを動かせるソフトです。Pythonコードを実行したり、GPUやTPUを使って高速に実行することができます。また、Google Driveとの相互運用性もあり、Google Drive上のファイルにアクセスすることもできます。なので、容量が少なく GPU を搭載していない PC でもインターネット環境と Google アカウントがあれば、だれでも高性能な PC を一時的に借りることができます。
GPU
先ほどから書いている 「GPU」 というのは、画像処理や 3D グラフィックスを高速に処理するために設計された部品です。 GPU は大量の並列処理を行うために設計されており、特に数値計算や機械学習などのタスクにおいて高速な処理を行うことができます。しかし GPU はとても価格が高く、最新の NVIDIA GPU は 40万円を超える代物となっています。それを Google Colab は無料で高性能な GPU Tesla T4 (GPUメモリ : 16 GB) を最長 12 時間使うことができます。
Colab で動かす Stable disffusion Ver2
GPU の用意
それでは使い方です。このリンクを右クリックしていただき、このような画面に飛びます。
ランタイム設定
そしたらこの赤矢印の「ランタイム」をクリックします。
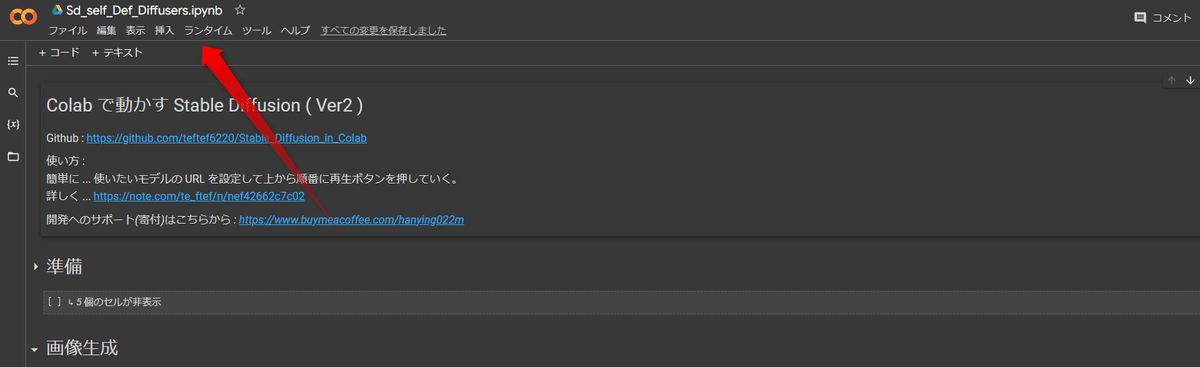
するとこのように(↓)選択しが出てくるので、この「ランタイムのタイプを変更」をクリックします。
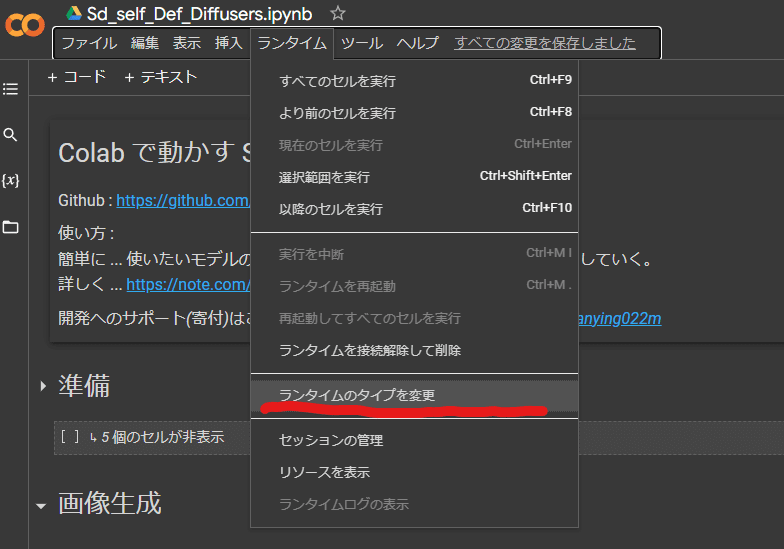
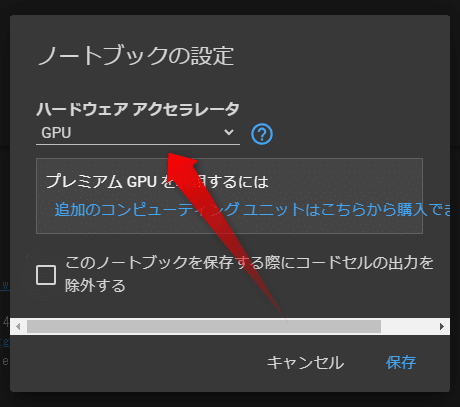
最初はこのようにNone になっているところをクリックし、
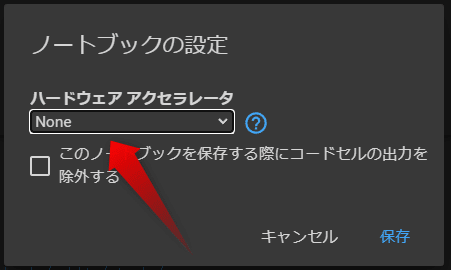
「GPU」に変更し、右下の保存を押しましょう。
準備
Google Drive と接続
自分のGoogle Driveと接続します。 それではこの一番最初の再生ボタンをクリックします。
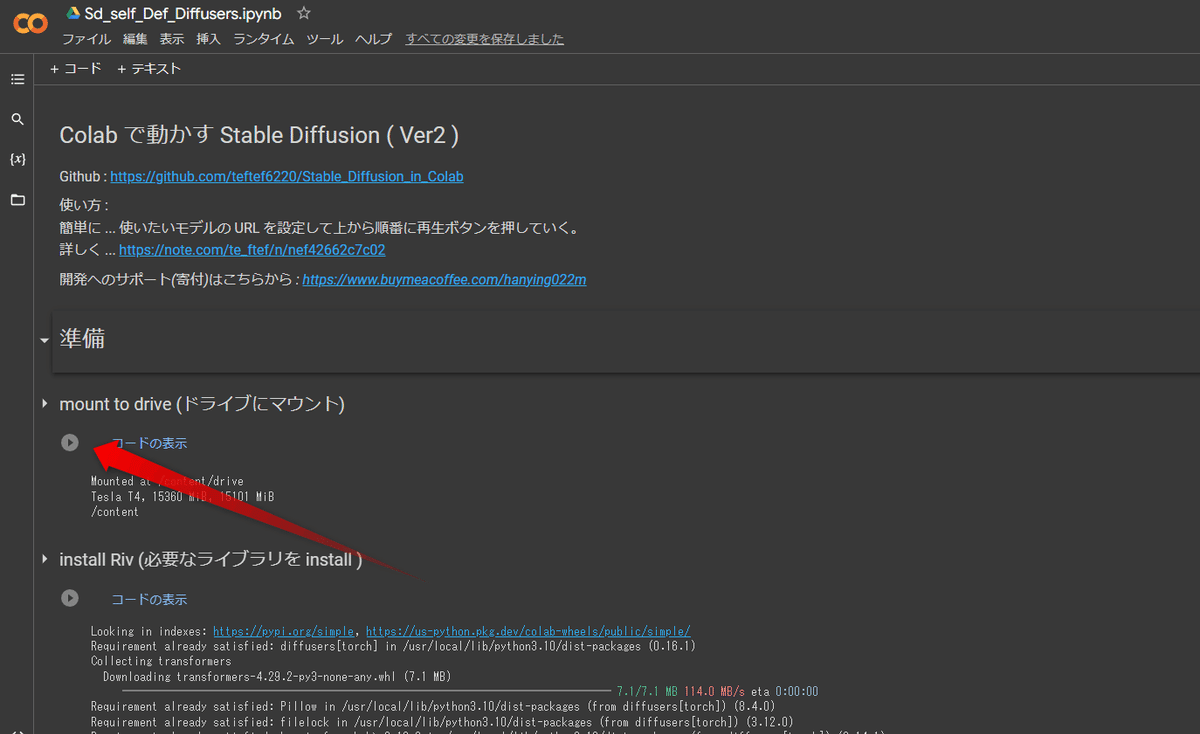
少し待つと、このような画面が出てくるので 「Google ドライブに接続」をクリックしてましょう。
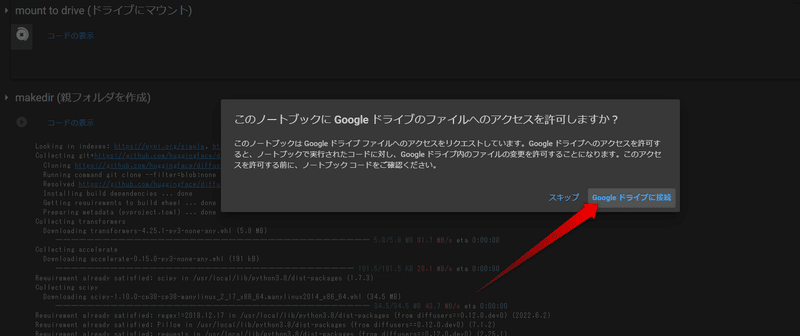
このような画面が出てくるので自分のアカウントをクリック
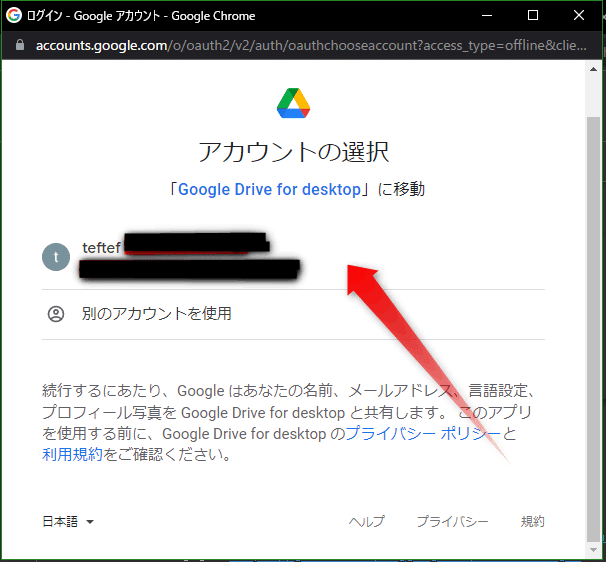
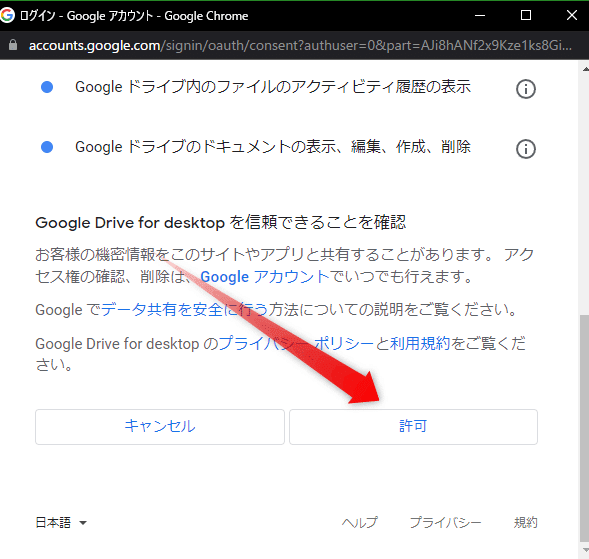
このような画面に進み、一番下までスクロールし、「許可」を押します。
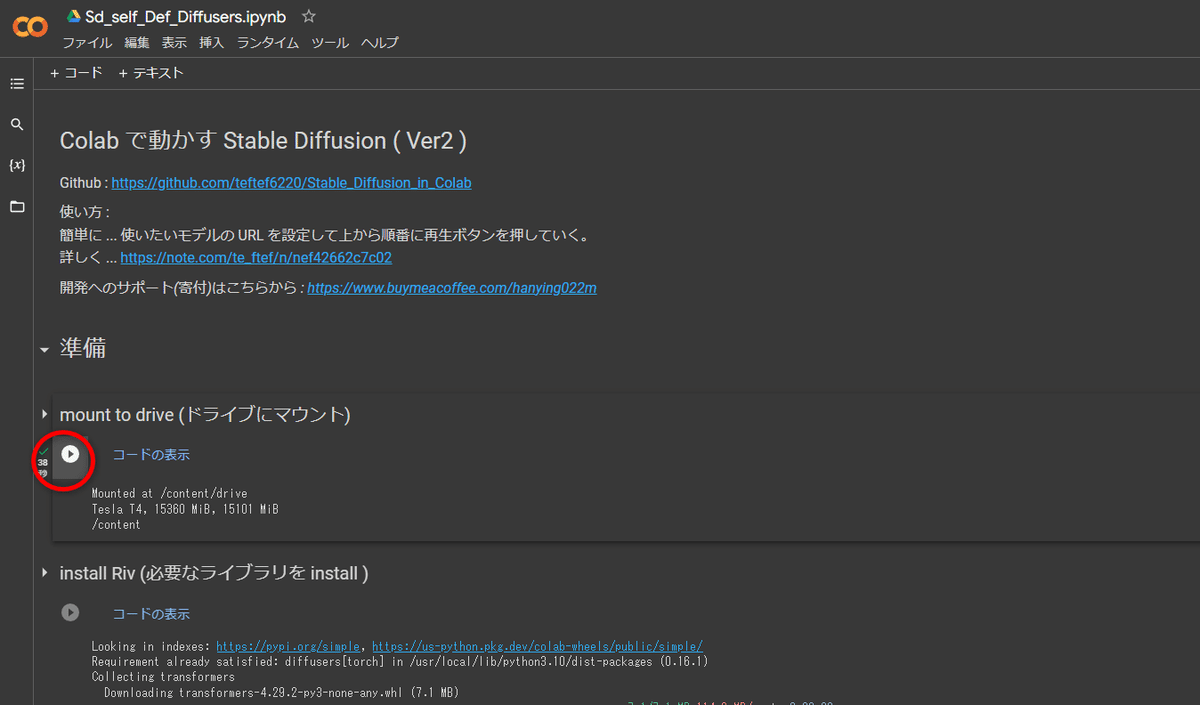
するとこのように緑色のチェックマークがつきます。
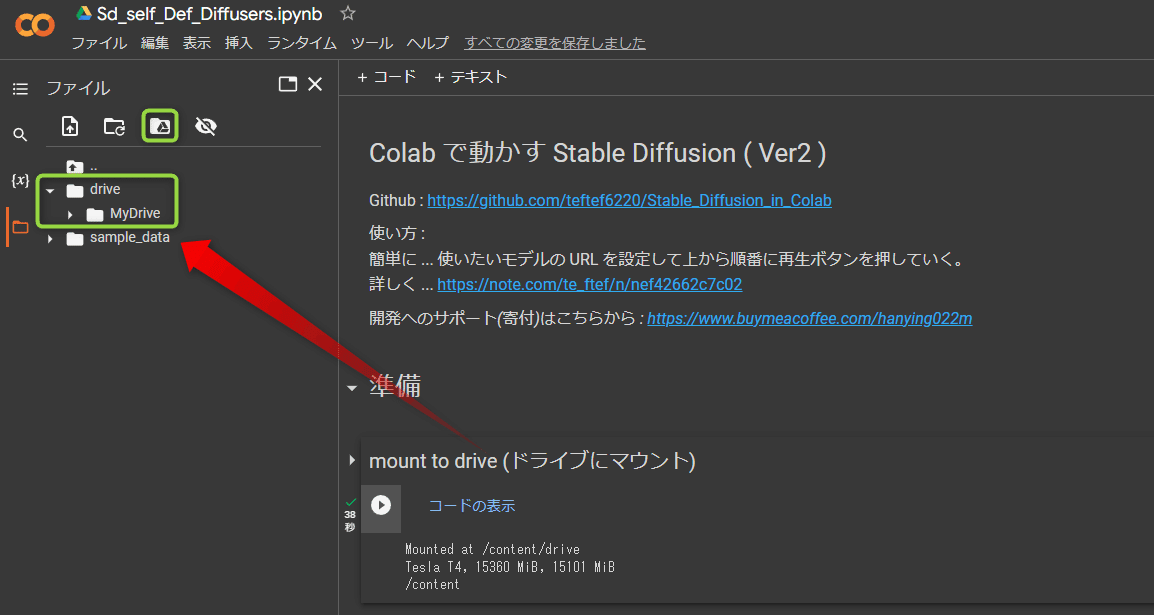
ちゃんと接続されているかどうかを確認するためにこのチェックマークの左にある「フォルダ」をクリックします。このように緑色で囲んだところのフォルダに△マークがついていて、 drive という名前のフォルダがあれば OK です。これで Google Colab 内から自分の Google Drive とアクセスができるようになりました。
各種設定、インストール
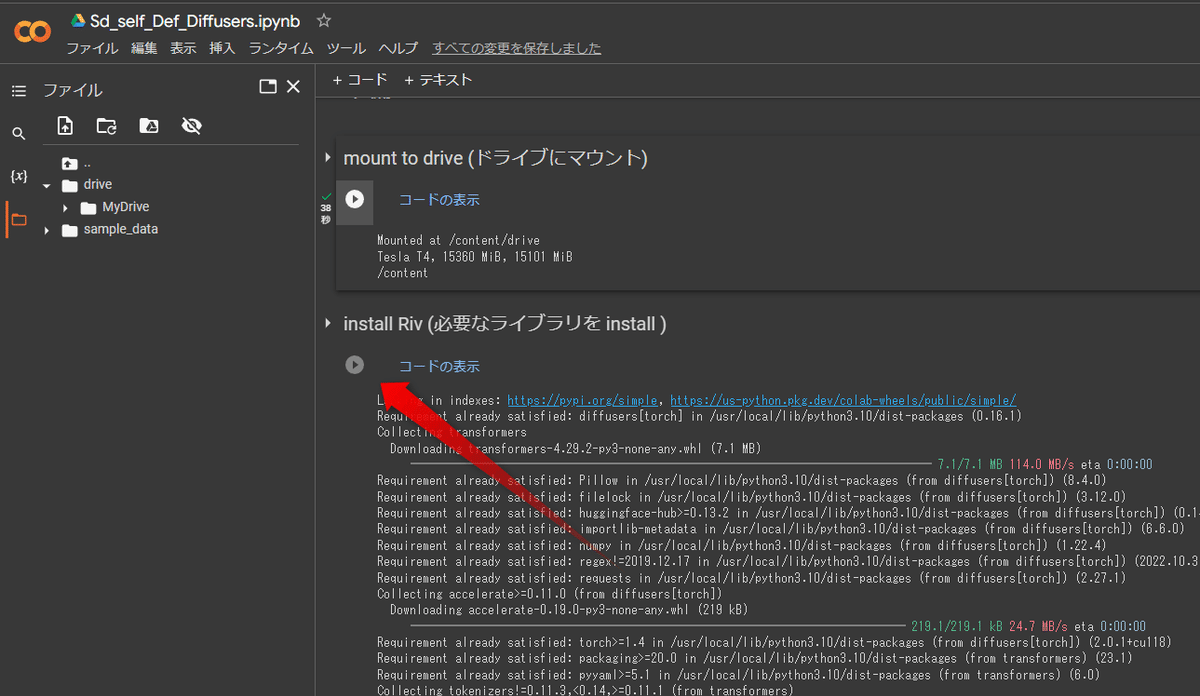
そしたら一つ下の再生マークを押します。1分ほど時間がかかるかもしれませんが、画像生成に必要なツールをインストールしてくれます。
モデルと VAE を入力
続いてどんどん、実行していくと、このようにモデルの URL と VAE を選択するところにたどり着きます。
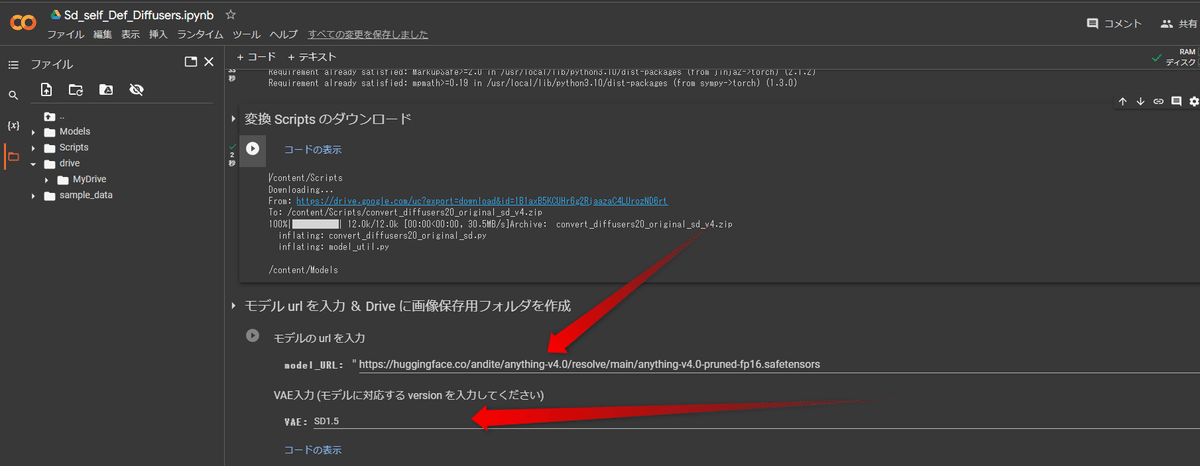
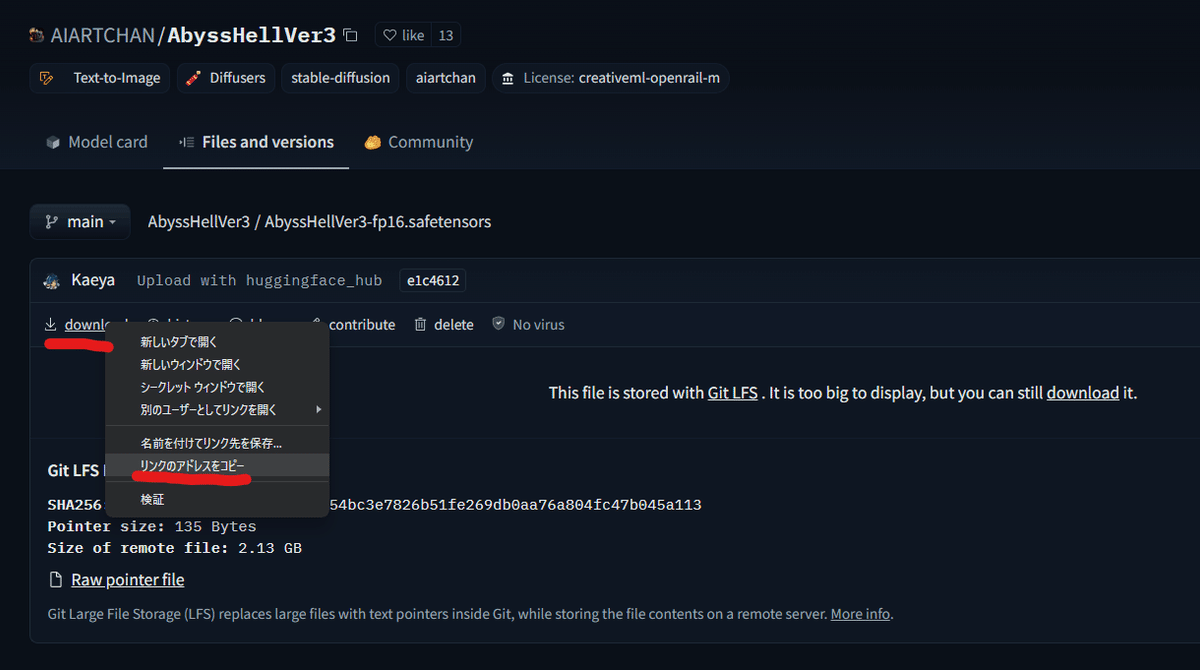
ここで、この入力欄に モデルの URL を入力します。モデルの URL は Hugging Face から直接 ダウンロード URL を取得して貼り付けてください。
VAE はそのモデルに合ったものを選択してください。
例えば V1 なのであれば SD1.5 や Anyv4 の VAE を、V2 であれば WD 1.4 のVAE を選択してから実行してください。
Diffusers に変換
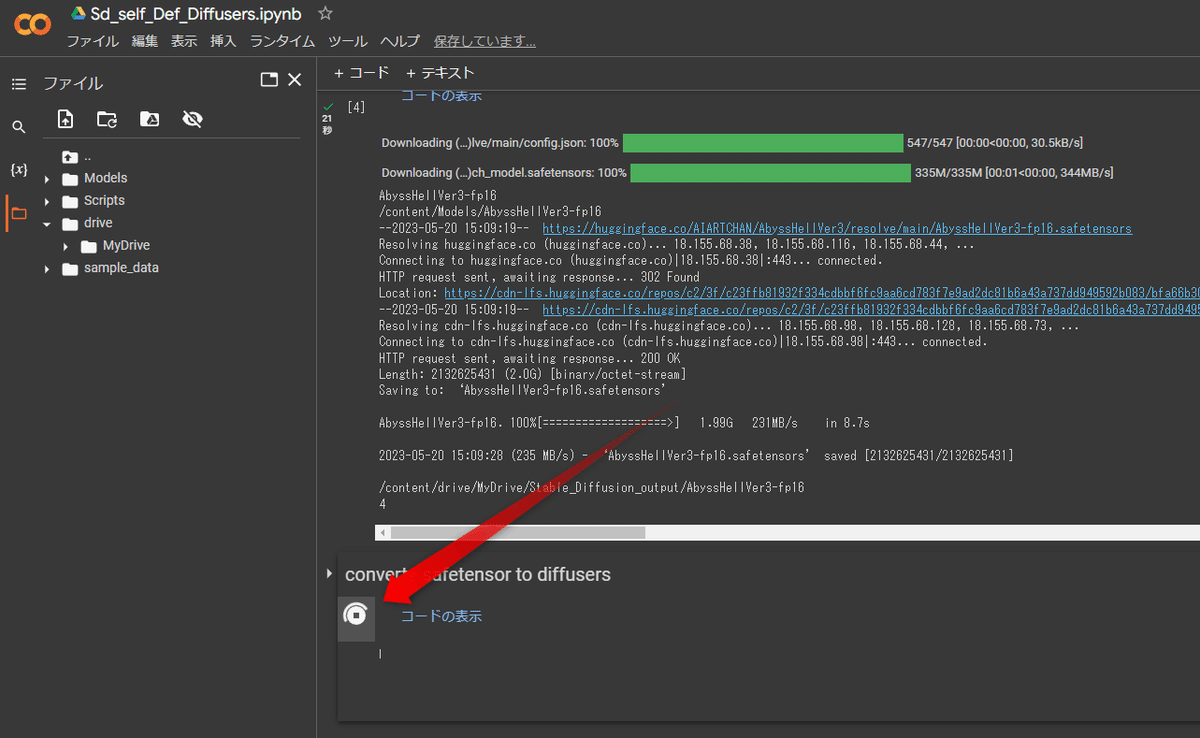
それでは続いて convert safetensor to diffusers という部分を実行しましょう。ここはしばらく時間がかかるので、気長に待ちましょう。エラーが出たらそのモデルが使えない or VAE が合わないことが多いので 1 つ前のステップからやり直しましょう。
画像生成
フォルダの確認
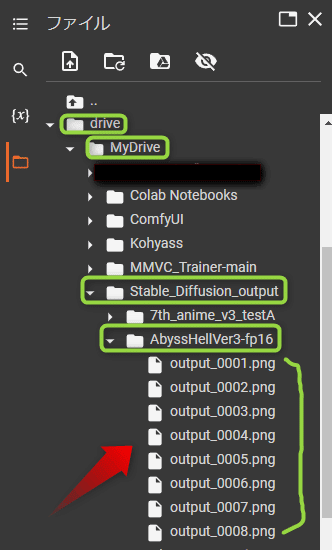
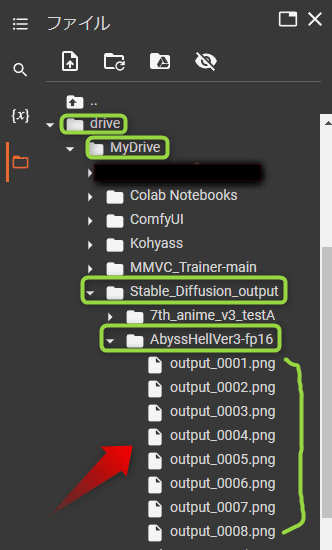
そしたら先ほど左側で開いたフォルダの「drive」,「MyDrive」,「Stabele_Diffusiom_Output」と押していくとこのように選択したモデルのフォルダが作られています。この中に生成された画像が保存されています。モデルごとに作成されるフォルダは分かれているので、ごちゃごちゃになることはありません。
生成
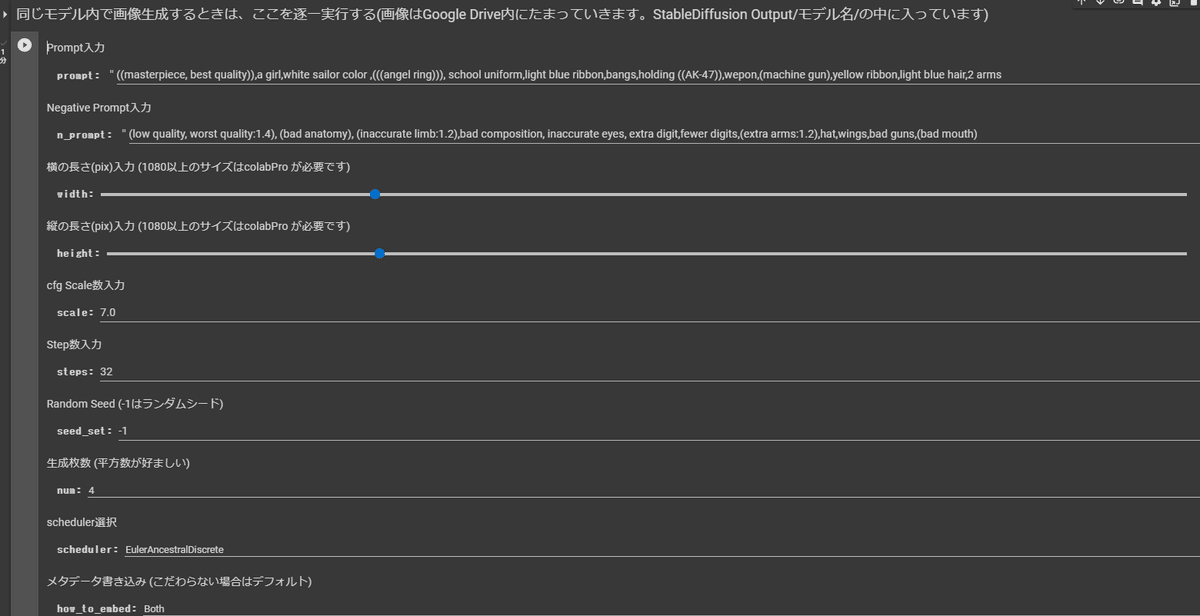
それではいよいよ画像生成です。ここでは様々な Option があり、順に説明します。
prompt : プロンプトです基本的に英語で入力してください
n_prompt : ネガティブプロンプトです。
width : 画像の横の長さ、512,768,1024が選択できます。
height : 画像の縦の長さ、512,768,1024が選択できます。
scale : スケール数
steps : ステップ数
seed : シードです。0~4294967295の整数を入力するか -1 を入力するとランダム値になります。
num : 一度に生成する画像の枚数、1,4,9,16から選べます
scheduler : サンプラー
how_to_embed : メタデータの埋め込み方法 Default はpng ファイルに埋め込み、Steganography は電子透かし、Both は両方できます。
これらを好きな値に設定して、再生ボタンを押しましょう。

画像番号
今回は4枚このように画像が生成されます。画像の名前はここに表示されいます。番号になっていますがこのように Z 字を書くような順番で番号が大きくなっていきます。

繰り返し画像を生成したい場合は、Prompt や seed,scale などの設定を変えて再生ボタンを押すと何回でも生成することができます。
画像は左のフォルダマークをクリックすると、このように先ほど作成されたモデル名の中に保存されていることがわかります。ここから画像のファイルを右クリックしてダウンロードすることもできます。
モデルを変更したい場合
モデルを変更したい場合はもう一度「モデル url を入力 & Drive に画像保存用フォルダを作成」(この記事で言うとモデルと VAE を入力 の部分)の部分から別のモデルを選択して、再生ボタンを押すと、モデルが更新され、そのモデルに対応するフォルダが「drive」,「MyDrive」,「Stabele_Diffusiom_Output」のフォルダ内に自動で生成されます。そして画像生成のところに行き、設定をし、再生ボタンを押すことができます。
埋め込みについて
ステガノグラフィ と メタデータ
昨今の image2iage トレース疑惑を考えて、画像に Prompt, negative Prompt,Seed を画像に埋め込んでいます。これを確認する方法も載せておきました。
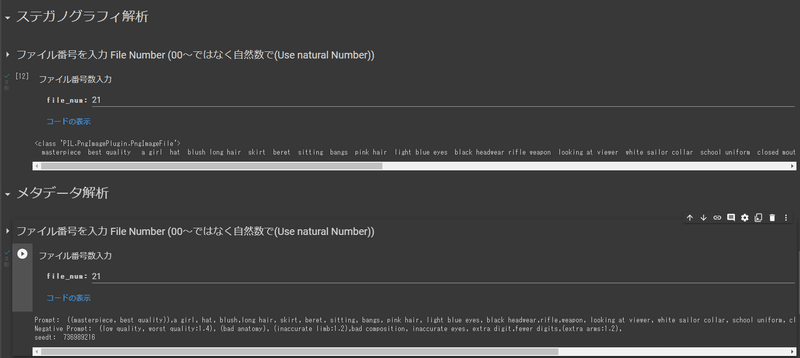
このように作成した画像ファイルの番号のみを入力するとその Prompt, negative Prompt,Seed を確認できます。
画像生成する際の how_to_embed でメタデータの埋め込み方法 Default はpng ファイルに埋め込み、Steganography は電子透かし、Both は両方できます。がDefaultを選択した状態でステガノグラフィ解析をやっても意味不明な文字列しか出ないので注意です。
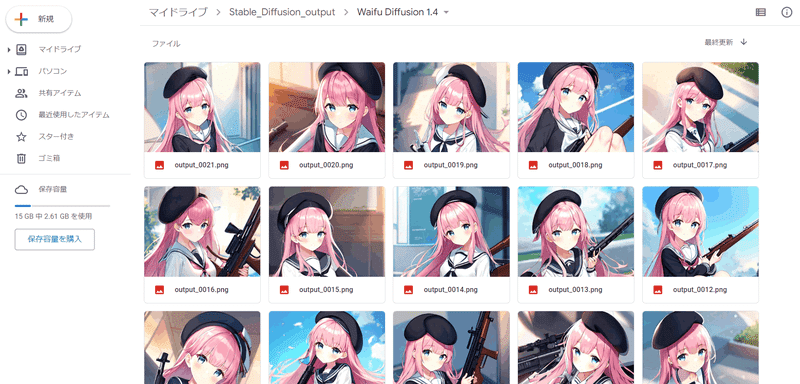
Google Drive で画像を確認
Google Drive で生成された画像をまとめてダウンロードしたり確認したりできます。画像を削除したい場合はここで「モデル名」を消すと全削除できます。
リクエストやバグ修正
今回は Colab で動かす Stable Diffusion Ver2 の使い方について詳しくまとめました。機能のリクエスト、バグ報告、モデルの追加は @hanyingcl までご連絡ください。お待ちしております。
最後に
最後まで読んでいただきありがとうございました。今後は Lora なども追加していこうと思います。最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(teftef , 4000 文字)
↓↓もしよろしければこの記事と開発の支援お願いいたします!