
1 億ユーザー 1 億商品棚の実現に向けた、パーソナライズされた商品レコメンド機能の裏側(Part2 実装編)

こんにちは、カウシェの AI チームの tatsuya(白川達也)です。
2022 年 11 月に入社してから検証・実装していた商品レコメンド機能がついにリリースされました(現状 iOS 版でのみ先行配信されています)。カウシェでは初めての機械学習を使った機能だったこともあり、リリースまでこぎつけるには超えないといけないハードルがいくつもあってそれなりに大変だったのですが、そのあたりの背景や経緯を踏まえ、実装の裏側を公開してみたいと思います。
本記事は「Part 2 実装」編です。カウシェで始めての機械学習系の機能である商品レコメンド機能の実装の裏側をお伝えします。
背景や経緯を詳しくお知りになりたい方は「Part 1 背景・経緯編」をご覧ください。
商品レコメンドで目指す体験
「Part 1 背景・経緯編」で触れた通り、これまでのカウシェではユーザーと商品の出会いの創出に一定の限界があり、機械学習を用いた商品レコメンド機能では、パーソナライゼーションを実現することを目指します。
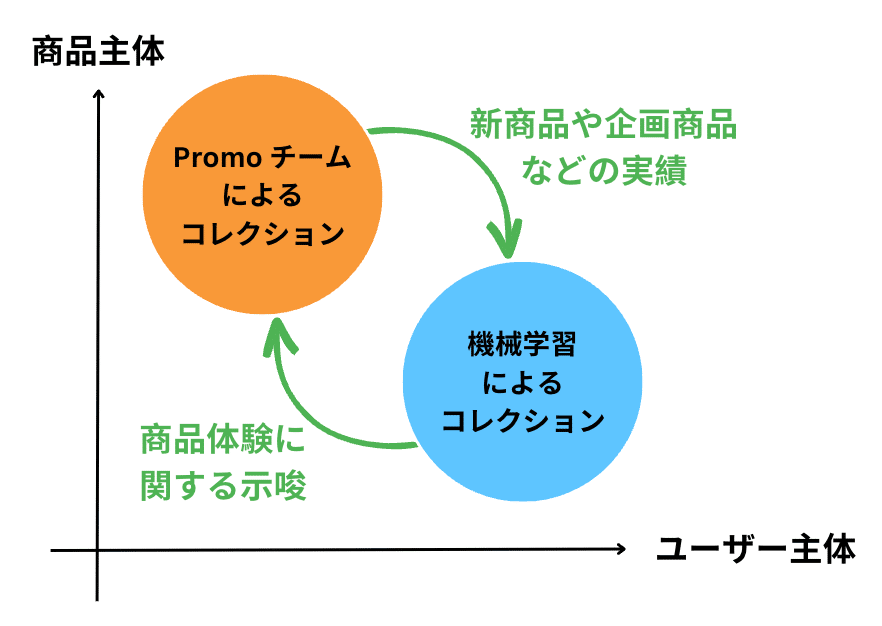
こちらも「Part 1 背景・経緯編」で述べたとおりですが、下記のような方針で設計しました。

アーキテクチャ
Vertex AI Pipelines 上でレコメンド作成パイプラインを実行し、作成結果をCloud Spanner に書き込む構成にしました。パイプラインは Cloud Scheduler を通じて定期実行されます。近い将来、リアルタイムにパーソナライズされるレコメンド機能も実現したいので、書き込み先のデータベースとしてはリアルタイム処理での事例が多かった Cloud BigTable を採用しようかとも考えたのですが、現行ではパフォーマンス的に問題はなさそうだったのでカウシェで導入済みの Cloud Spanner を利用することにしました。

カウシェではバックエンド API は Go で書かれることが多いです。一方、機械学習は Python を用いて実装されることが多く、今回も Backend の API をどちらの言語で実装するか検討しましたが、組織として今後メンテナンスしていくことを考えると、Go で実装すべきと結論づけました。
Recommend DB(Cloud Spanner)を機械学習側とバックエンド側の Interface にすることで、責任境界を明確化できたのではと思っています。後述しますが、QA に関しても Recommend DB の前後で分担しています。
レコメンド作成パイプライン
レコメンド作成パイプラインは下記のような構成になっています。

レコメンド作成パイプラインは下記のステップよりなります。
商品ベクトルの構築
商品の重複除去処理
商品閲覧にもとづくユーザーベクトルの構築
ユーザーベクトルをクエリーとした関連商品ベクトル検索
Conversion Score の付与
Cloud Spanner へのレコメンド結果の書き込み
それぞれ説明します。
1. 商品ベクトルの構築
現時点で、カウシェの全商品について十分量の閲覧・購入履歴が蓄積されているわけではなかったので、Collaborative Filtering のような方法で商品ベクトルをつくることはしませんでした。かわりに商品のテキスト情報(タイトル、カテゴリなど)をもとに、Text Embedding モデルを使って商品のベクトル化を行っています。Text Embedding モデルとしては、学習済みの BERT 系のモデルを使用しましたが、商品のテキストは独特なので、いずれカウシェ専用の Text Embedding モデルなどを作りたいです。商品はテキスト情報をもとにベクトル化されるので、新商品が追加されたときでもテキスト情報さえ埋まっていればすぐにベクトル化することができるのは利点です。
なお、全商品に対して商品ベクトルの構築を毎回行うと膨大に計算時間がかかるため、事前に商品ベクトルを一度計算しておいて計算日時とともに保存しておき、それ以降に更新があった商品のみを対象として差分計算することで効率化を行いました。
2. 商品の重複除去処理
現状のカウシェには色違い・サイズ違いなどの商品バリアントが多数存在しています。これの集約処理をせずにレコメンドをすると、同じような商品ばかりがレコメンド結果に並ぶことがあり、見た目的にもあまり良くないです。
そのため、バリアントを特定して、重複排除するロジックを入れました。本来的にはバリアントが商品マスター上で管理されているのが望ましいのですが、現時点では完全なバリアント情報が手に入らなかったので、1 でつくった商品ベクトルや価格・事業者情報などをもとにバリアントらしきものを名寄せし、重複除去するロジックを作りました。現状、バリアントのうちのどの商品を残すべきかを決定する明確な判断基準を持っていないため、計算のたびにランダムにバリアントからひとつの商品を代表商品として抽出するようにしました。
3. 商品閲覧にもとづくユーザーベクトルの構築
ユーザーごとに商品閲覧情報が十分量蓄積されたら、商品とユーザーにたいして Two-tower Model などによりユーザーベクトルを作りたいところですが、コールドスタートが気になるのと、いきなり Deep Neural Networks ベースの方法をとるよりももうちょっと手応えを感じやすい手法を採用したかったのもあり、ユーザーが閲覧・購入した商品の商品ベクトルをもとにユーザーの商品ベクトルを構成することにしました。
具体的にはユーザーが閲覧した商品を時系列順に列挙し、現時点からの経過日数をもとに discount しながら商品ベクトルの加重平均を取りユーザーのベクトルとしました。
当初、購入したばかりの商品をレコメンドするのは良くないだろうと考え(肉を買った翌日にまた肉をおすすめされたくないですよね)、購入した商品に類似した商品を閲覧商品から除外してユーザーのベクトルを作ったりもしていました。しかし、データを見る限り同じ商品を定期的に購入しているユーザーも一定数いるようで、簡単なロジックでうまく除外・非除外の調整の折り合いをつけることが難しかったので、あえてその処理は入れないようにしました。かわりに経過日数に基づく discount をすることでなるべく最近のユーザーの行動に適応させるようにしています。
ユーザーベクトルの作り方に関してはまだまだ改善の余地が大きいと考えています。レコメンドに対するユーザーの反応の分析を進めつつ、今後改良していきたいです。
4. ユーザーベクトルをクエリーとした関連商品ベクトル検索
3 で作ったユーザーベクトルをもとに商品のベクトル検索を行います。この際、2 の重複除去結果を加味しています。これにより、ユーザーの閲覧した商品と関連性の高い商品が抽出されます。現状、ユーザーごとに数百件抽出しています。商品点数もまだメモリに載せきれる程度なので、使い慣れた faiss を使ってベクトル検索をしています。ベクトル化とベクトル検索をカウシェの機械学習のコアコンポーネントにしたいと思っているので、いずれ Vertex AI Matching Engine などのより本格的なベクトル検索用のサービスへ移行したいと考えています。
5. コンバージョンスコアの付与
商品ベクトルはあくまで商品のテキスト特徴だけを用いて作っていたので、4 の結果をそのままレコメンド結果として出してしまうと商品の価格感やユーザーの関心軸などが加味されないレコメンドになってしまいます。ユーザーによって「お得さ」を好んだり「目新しさ」を好んだりといった好みの違いがあるはずなので、Conversion Score というユーザーがある商品を買いそうかを表す尺度を定義し、それに基づいたリランキングをすることにしました。

Conversion Score は以下のように作っています。まず、ユーザーごとに商品を購入したタイミングを抽出します。この時、実際に購入していた商品を商品 X とします。そして、ユーザーがその商品を購入する直前に得られる情報を用いて、商品 X を買いそうかを予測します。もちろん、商品 X の購入の直前には商品 X の閲覧が発生していたりするので、そのようなリークにつながるような情報は注意深く除去します。
この予測を素直に実現するなら、シーケンスの生成モデルなどを学習すれば良いのでしょうが、重たくなりそうだったので、Contrastive Learning のようなことをしました。X のほかに何らかの手段でサンプリングされた商品 X' をとってきて、X と X' のいずれが実際にユーザーが購入した商品なのかを識別するタスクを構成し、その識別モデルを学習しました。モデルの学習には LightGBM を用い、特徴量としては、ユーザーの過去の閲覧・購入履歴情報のほか、ユーザーや商品に関する情報などを使っています。価格が安い(≠ お得な)商品の方が買われやすい傾向もあるため、あえて商品の価格は特徴量に入れないなどの調整も行っています。また、偽の商品 X' のサンプリングは、商品全体からの一様サンプリングと購入頻度に基づくサンプリングを適当に混ぜて行っています。
この学習されたモデルを使うことで、ユーザーにたいして商品 X が購入されることの自然さを予測確率として得ることができます。この予測確率を Conversion Score としています。
6. Cloud Spanner へのレコメンド結果の書き込み
5 で計算された Conversion Score と 4 で計算された際のベクトル類似度(Cosine 類似度)を適当な割合でバランスした値をレコメンドの商品スコアとして商品を ranking し、Cloud Spanner へ書き込んでいます。
Conversion Score のみを用いなかったのは、それをしてしまうと関連度が低いが買いそうな商品が上位に来ることがあり、ユーザーの閲覧行動との見た目上の関連性が下がると考えたからです。今回のレコメンドはあくまで「閲覧履歴にもとづくおすすめ」になるように作ったので、ある程度閲覧行動と一貫性のあるレコメンドを出しておきたいと考えました。
今後、レコメンドに対するユーザーの反応を分析してよりよい設定を模索してみたいと思います。
パイプラインのスケジュール実行
パイプラインは Cloud Scheduler を通じて内製の Pipeline Runner でスケジュール実行させています。Pipeline Runner は弊社の yuki.ito さんの手によるものです。カウシェのバックエンドはほぼすべて Go 言語で書かれているため、Pipeline Runner も Go 言語で書かれているのですが、Kubeflow Pipelines と Vertex AI Pipelines の仕様の差異を埋めるために必要な調整がいくつか必要で、やや手間取りました。こちらの詳細は下記のブログの 「Practice 5. Compile して得た .json のキャッシュ設定を無効にしておく」の部分などをご覧ください。
バックエンド API による商品提示
バックエンドの API は Spanner に書き込まれたレコメンド結果を単純に読み込んで返却するというようにはせず、呼び出されるたびにレコメンドの商品スコアに多少のノイズを加え、その値が大きい順に返却する仕様にしました。これは、呼び出しのたびに商品の並び順を多少変動させ、商品の露出を固定化しないようにするためです。
商品の掲載位置によってユーザーの反応が変わるポジションバイアスは結構強力なので、ユーザーがレコメンドにアクセスするたびに表示順を変化させることで、ユーザーの目に触れる商品を多様化し、かつ、事後により公平な検証ができるようにしようと考えました。
これはレコメンドの見栄えを撹乱する効果もあります。ノイズを加えずにレコメンドを表示していた時、バリアント除去などで集約しきれなかった商品などがどうしても並んでしまうことがありましたが、ノイズを加えて撹乱することで、同系統の商品が並ぶことが少なくなりました。
開発時の CI
開発時は可能な限り自動テストの恩恵にあずかりたいので、商品レコメンド用に CI を組みました。機械学習でのテストはいつも難しいです。必要な箇所に対しては単体テストをきっちり書きましたが、今回のように Vertex AI Pipelines を用いる際、どのように e2e テストを書くべきかは悩み、結局まともな e2e テストを導入することは諦めました。Vertex AI Pipelines で簡単に導入できる e2e テストの構築方法をご存じの方がいたら教えていただきたいです。
結局、CI では下記の3種のテストをすることにしました。
lint(pysen をつかいました)
単体テスト
パイプラインがコンパイルできるかのテスト
e2e テストが導入できなかったので、適宜手動でパイプラインを submit して様子をみるという原始的な方法でパイプラインが実行できるかを確認しました。
品質保証(QA)
リリースのためには QA が必要ですが、機械学習の QA はいつも難しいです。とくに最初のレコメンドの実装であるため、レコメンドの良し悪しを評価するための評価データも蓄積されておらず、評価データを用いた機械的で定量的な品質判定などもできません。
そこで、以下のように QA を分解することにしました。
想定されたレコメンド結果がレコメンド DB に書き込まれていること(レコメンド DB に書き込まれるまで)
レコメンド DB を参照しレコメンド結果が正しく返却されていること(レコメンド DB に書き込まれたあと)
前者は機械学習ロジック観点の QA になり、私が責任をもって実施することにし、後者は通常のソフトウェアの QA として実施することにしました。
前者の QA の際には、Streamlit で作ったレコメンド結果を可視化するアプリを使い、違和感のあるレコメンドがされていないかを目で見て確認しました。このアプリはロジックをつくるときから頻繁に参照しており、大活躍でした。Promotion チームの方にレコメンド結果のフィードバックをもらう際にも活用しました。
商品レコメンドづくりを振り返って
商品レコメンド機能はカウシェで最初の機械学習系の機能だったため、一歩踏み出すと一つ基盤や開発環境に関する課題が発生する感じで、ひたすら基盤や開発環境の整備をしていた印象があります。今回の開発を通じて、下記が整備されました。次回からはもっと速く実装ができるはずです。
データを用いた機能の開発プラクティス
ランキングなどのデータを用いた簡単な機能はこれまでも開発されていましたが、本格的な機能の開発は初でした。カウシェではこれまで、 prod/dev の ふたつの環境のみを用いて開発していたのですが、dev に変なデータを入れてしまうと開発環境が壊れてしまいます。そのため、dev の手前にもう一つ lab という環境を作り、データを用いた開発をする場合は prod/dev/lab の 3 環境を使うようにしました(よくある prod/stg/dev に分けるのと一緒になるようにねじ込みました)。
データウェアハウスの整備
データを参照するような機能を作る以上、参照されるデータもプログラムと同等の水準で管理されるべきだと考えていますが、これまでカウシェではそのようなニーズが顕在化していなかったのもあり、データの管理はややルーズでした。そのため、今回の開発に合わせ、データウェアハウスの整備も実施し、dbt の導入を進めています。
正直、データウェアハウスの整備方針を決めるのが一番大変で、1、2 月はそればかりやっていました(そしていまも一部策定中です)。一人目機械学習エンジニアはデータエンジニアリングもやることになりがちです。あたらしいサービスもどんどん出てきて個人的には興味のある領域なので、追っていて楽しいのですが、ファンではなくプロフェッショナルとして仕事を全うしようとすると手が足りません。
Python による開発環境
カウシェには Python でプロダクト開発を行うエンジニアがいなかったため、Python 用の開発環境が整っていませんでした。そのため、今回の開発のために、Python 用の開発環境を設計・構築しました。こちらについては下記の記事にまとめているのでご興味があればご覧ください。自分で言うのもなんですが、Poetry のグループ機能を使ったモノレポ管理はかなりお手軽で非常に良かったです。
環境は作ったものの、コードレビューしてくれる相手がいないという別の問題も発生しました。最低限のコード品質は死守しようとやってみましたが、一人ではやはり限界はあるなと感じました。
Vertex AI Pipelines を用いた開発
前職時代に検証はしていてだいたいの使い方はわかっていたのですが、いざVertex AI Pipelines を使って実装しようとすると、ドキュメントでは推奨していないプラクティスを実践しないといけなかったり、そもそもドキュメント化されていないことをやりたくなったりしてちょいちょいつまづきました。
躓いた部分は都度プラクティスの整備をしていきました。そのうちのいくつかは下記のブログにまとめています。
Vertex AI Pipelines は総体的には自由度が高く非常によいサービスだなと感じています。AI に限らず、任意のコンテナを実行したり、コンテナを入出力で DAG にして実行させたりできる便利なサービスなので、AI 以外の用途も探っていきたいと思っています。
Vertex AI Pipelines,便利で汎用的なパイプライン実行基盤として使えるはずなのに、名前にAIってついているせいでAIっぽくないパイプライン実行基盤として心理的に使いにくいの、もったいなさがある。
— Tatsuya Shirakawa (@s_tat1204) June 21, 2022
Custome Jobも汎用のコンテナ実行基盤として使えるのにAIという文字がちらつく。
将来に向けた課題
ベースラインの実装はできたとはいえ、まだまだ課題だらけです。下記についてはタイミングを見て取り組んでいきたいです。
より多様性のある尖ったレコメンドの実現。自分のアカウントへのレコメンドを見ても、まだまだ改善の余地があると感じています。多様性を確保するための手際の良い方法を知りたいのですが、まだ自分のなかでは解答がありません。
スケーラビリティの確保。たとえばユーザー数、商品数が数十倍になると現行の計算基盤では破綻してしまいます。常に 10 倍規模くらいは耐えられるようにしておきたいで、同じようなロジックを使うなら、もう少ししたら分散処理基盤などの導入を検討しないといけないのかもしれません。
初回利用ユーザーに対してもパーソナライズを行える仕組み。オンボ時にパーソナライズを完了させるプロセスなどを組み込み、最初からパーソナライズされた体験を届けられるようにしたいです。最短手数でユーザーの興味関心を知ることができるにはユーザーに何をしてもらえばよいのかというのは非常に興味のある課題です。是非検討してみたいです。
(準)リアルタイムなパーソナライゼーション。ユーザーが今見た商品、今買った商品に応じて体験を変えられればと思っています。カウシェには時間制限のある商品や期間限定のセールなどもありますし、ユーザーの瞬間的な興味・関心に寄り添うためにはリアルタイムなパーソナライゼーションは必須だと考えています。
ベクトル検索ベースのアーキテクチャに載せ替える。現状でもベクトル検索は内部で使っているのですが、その後のランキング処理が複雑であり、それが原因で重たいバッチ処理を日時でスケジューリング実行することになっています。そのため、なんらかの手段でランキングを排除し、ベクトル検索だけをすれば済むようなアーキテクチャに移行していければと考えています。ベクトル検索のインデックスとしてレコメンドを提供できれば、いよいよ検索とレコメンドが溶けていく世界が見えてきます。手離れもずっと良くなっていくはずです。
さいごに
以上、「Part 2 実装編」でした。背景や経緯についてより詳しく知りたい方は「Part 1 背景・経緯編」もご覧ください。
カウシェにご興味を持った方がいらっしゃいましたら Twitter @s_tat1204 もしくは YOUTRUSTのカジュアル面談 などでお気軽にお声がけください。軽い気持ちでご応募頂いて話を聞いてみる、というのも大歓迎です!ぜひよろしくお願いします。