
【大学入学共通テスト「情報I」(2025/1/19実施)第4問】の図をRで再現してみる

問1
問題で使用されている「観光庁が公開している旅行・観光消費動向調査の2019年の結果」のExcelファイルの中で, 地方ごとのデータはT04のシート, 都道府県ごとのデータはS04のシートを使っていることが分かった。
共通テストで使われたグラフや散布図であれば, 表計算ソフトですぐに作成できそうであるが, 模試などではRを使った(と思われる)相関行列などが出題されてきたことから, あえてR Studioで全て作成することとした。

まずデータの読み込みから整えるまで
install.packages('readxl') # Excelファイルの読み込み
install.packages("tidyverse") # ggplot
library(readxl)
library(tidyverse)
data <- read_excel("表1地方ごとの旅行者数と旅行目的別の内訳(抜粋).xlsx", skip=1,range = "B1:F11")
# 地方の順序を保持するためにfactorを設定
data$地方 <- factor(data$地方, levels = unique(data$地方))
# カテゴリの順序を保持するためにfactorを設定
data_melted <- data %>%
pivot_longer(cols = c("出張等", "帰省等", "観光等"),
names_to = "カテゴリ",
values_to = "人数") %>%
mutate(カテゴリ = factor(カテゴリ, levels = c("出張等", "帰省等", "観光等")))そして(a)の棒グラフ
#######################################################################
# ヒストグラムを作成
ggplot(data_melted, aes(x = 地方, y = 人数, fill = カテゴリ)) +
geom_bar(stat = "identity", position = "dodge") +
labs(title = "(a)棒グラフ",
x = "地方",
y = "人数") +
theme_minimal()
(b)の帯グラフは割合を計算してから(一発でできそうですが, ご意見ください)
#######################################################################
# 割合を計算する
data_melted <- data_melted %>%
group_by(地方) %>%
mutate(割合 = 人数 / sum(人数) * 100)
# 横棒の積み上げ割合グラフを作成
ggplot(data_melted, aes(x = 地方, y = 割合, fill = カテゴリ)) +
geom_bar(stat = "identity", position = "stack") +
coord_flip() +
labs(title = "(b)帯グラフ",
x = "地方",
y = "割合 (%)") +
theme_minimal()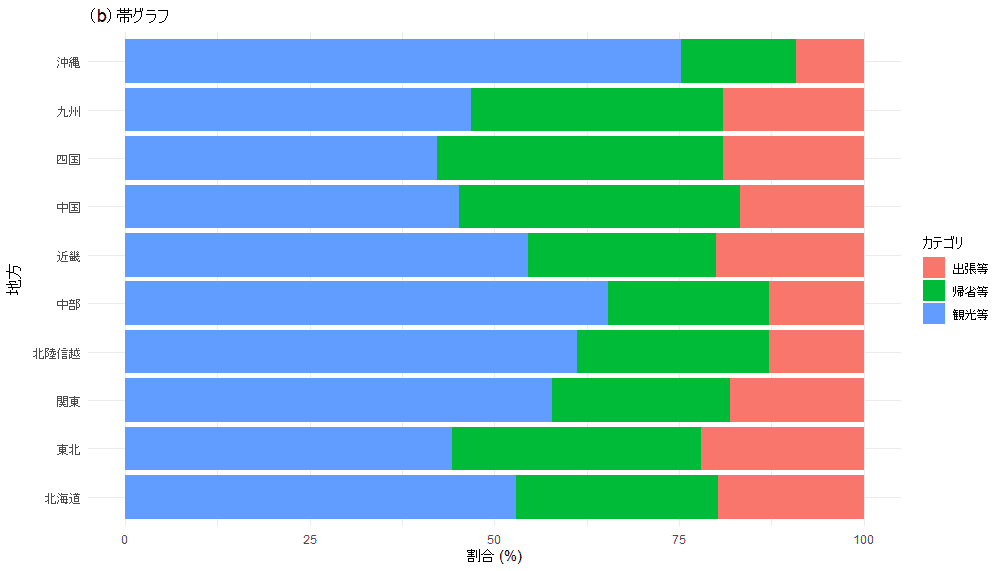
問2
続いて, 31ページでは47都道府県ごとの旅行者数と旅行目的別の内訳が集計されている表2から, 散布図と相関係数を求めています。次のように, Rで作ってみました。

#######################################################################
# 47都道府県ごとの相関行列を作成
data47 <- read_excel("表2都道府県ごとの旅行者数と旅行目的別の内訳(抜粋).xlsx", skip=1,range = "C1:E48") # 2行目以降の調査年yearと総人口numberを読み込み
install.packages("GGally")
library(GGally)
library(psych)
ggpairs(data47)

問3
「数」対「数」は人口を交絡因子として相関係数が高くなることは容易に予想される。そこで各都道府県の人口で割った値を指標とし散布図を作り直しました。

#######################################################################
# 人口で割った値で相関行列を作成する
data47_A <- read_excel("表2都道府県ごとの旅行者数と旅行目的別の内訳(抜粋).xlsx", skip=1,range = "B1:E48")
data47_B <- read_excel("表3都道府県ごとの人口(抜粋).xlsx", skip=1,range = "B1:C48")
# データのマージ
merged_data <- merge(data47_A, data47_B, by = "都道府県")
# 各値を人口で割る
merged_data$出張等_per_capita <- merged_data$出張等 / merged_data$人口
merged_data$帰省等_per_capita <- merged_data$帰省等 / merged_data$人口
merged_data$観光等_per_capita <- merged_data$観光等 / merged_data$人口
# 必要な列を抽出
data_for_correlation <- merged_data[, c("出張等_per_capita", "帰省等_per_capita", "観光等_per_capita")]
# 相関行列
ggpairs(data_for_correlation)

生徒からすれば表計算ソフトで必要なデータだけ取り出せばここまで面倒な作業はないし, Rを学習しなくても済んでしまいます。そして, 試験問題のように注目する観点を絞って考察するにはオーバーな作業でした。
追記
上記Rのスクリプトは全てCopilotによって作成されたものです。