
【論文レビュー】縦断研究における成長曲線モデルと潜在クラス成長分析についてすごく大まかにまとめてみた:西村(2022)

これまでのnoteでは、縦断研究の方法論として交差遅延モデルばかりを扱ってきましたが、成長曲線モデル(growth curve model)と潜在クラス成長分析(latent class grotwth analysis)を扱っている論文があったので概要をまとめてみます。あくまで「概要」レベルであることをご理解くださいませ。
西村倫子. (2022). 発達研究における縦断データの解析手法- 成長曲線モデルと潜在クラス成長分析. Japanese Journal of Developmental Psychology, 33(4).
成長曲線モデル
成長曲線モデルでのアプローチには大別して、①回帰分析をベースとした混合効果モデルと、②構造方程式モデルをベースとした潜在曲線アプローチという二つがあると著者はしています。
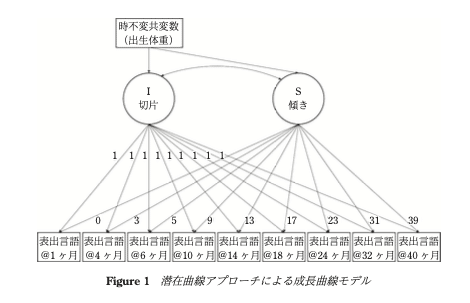
潜在曲線アプローチのアウトプットの例として、著者が行った幼少期の母子を対象としたコホート研究でのモデルを提示しています。たしかにSEMのアウトプットだなぁと思えるもので、何となくイメージできます。
潜在クラス成長分析
この分析手法は、因子分析に似ているところがあると著者はしています。潜在クラス成長分析の項目反応確率は、因子分析における因子負荷量の概念と類似しているとの言及があるところが具体的でイメージしやすいです。
他方で、もちろん相違もあります。因子分析は回答傾向が近い潜在変数を抽出して構成概念として一括りにすることを目的としているのに対して、潜在クラス成長分析では応答パターンが類似した個人をまとめてクラスという潜在変数を見つけることを目的としています。つまり、対象が質問項目なのか個人なのか、という違いがあるのです。
最適なクラスを分析するためのアウトプットは以下のようなものです。

モデルの適合度については、複数の検定結果をもとに総合的に判断するようです。ここでは、ベイズ情報量基準および赤池情報量基準が6クラスまで減少していること(=6クラスがベストで5クラスが二番手)、AWEが最小であること、エントロピーが0.8以上であること、という三点から5クラスの適合度が最も高いと結論づけられています。(尚、LMR尤度比検定は2クラスが最適、ブートストラップ尤度比検定はいずれもOK、という結果です)
最適であるとされた5クラスに基づいた子供の発達軌跡について、High normalからMarkedly delayedまでの5クラスでアウトプットされたモデルが以下です。

Markedly delayedとはなかなかな表現でビビりますが、発達研究ではこのような形容詞を使うのですね。幼少期の子供を五つのクラスに分類すると、五つの領域においてどのような発達の軌跡を描くのかを縦断で明らかにできるようです。