
2020-07-29 夏のAWSコンテナ祭り with Amazon ECS #ECSMatsuri

2020/07/29 に開催された 夏のAWSコンテナ祭り with Amazon ECS のイベントレポートです。
●イベント概要
みなさん、コンテナサービスをお使いですか?
多くの人がコンテナを使うようになった今だからこそ、「ここでつまってしまった」「ここがわからない」など課題や疑問が顕在化してきていることでしょう。当セミナーでは、AWSコンテナサービス、特にAmazon ECSをお使いのお客様の活用事例と、AWSソリューション アーキテクトによるECS活用のための徹底解説を展開します。
■Capacity Provider をもっと身近に
松田 和樹さん [アマゾン ウェブ サービス ジャパン]

●ECS Capacity Providers
・Capacity
タスクを配置する先のリソース
EC2やFargate
・Provide
コンテナの実行費必要な量を調達
・配置先を決定するための新しい方法
タスクの配置先の柔軟なコントロール
60%はオンデマンド、残りはスポットインスタンスなど

●これまでのECSクラスターのスケーリング 1
・ECS Cluster
ECS Tasks
EC2 AutoScaling Group
※serviceは端折ってます
→ 新しいコンテナが実行されるとVMのCPU、メモリを消費
→ CloudWatch metrics
CPU, Memory, Network In/Out
デフォルトだとメモリは取れないのでカスタムメトリクスで
→ CloudWatch Alarm
→ EC2 AutoScaling
EC2のインスタンスを増やす
・EC2のリソースを見てリアクティブにスケール
コンテナの整合性は自身でコントロールが必要
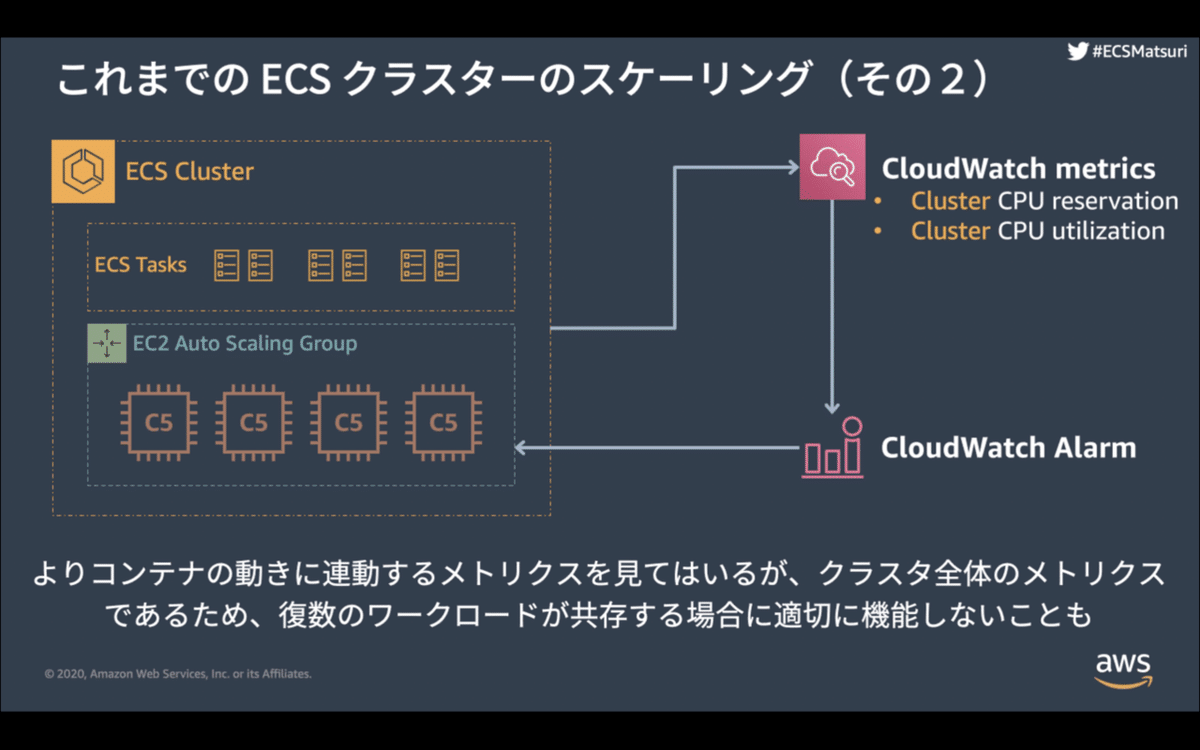
●これまでのECSクラスターのスケーリング 2
・ECS Cluster
ECS Tasks
EC2 AutoScaling Group
→ CloudWatch metrics
Cluster CPU reservation, CPU utilization
クラスタ全体のmetricsが取れる
→ CloudWatch Alarm
→ EC2 AutoScaling
EC2のインスタンスを増やす
・新規に追加する台数や予約率で調整
コンテナのメトリクスを見ているが、クラスタ全体
複数ワークロードが共存すると難しい
●Capacity Providers登場前の課題
・コンテナのスケール前にEC2をスケールさせる必要がある
・コンテナをスケールできる余剰を残しておく必要がある
空いていないと増加が見えない
コスト最適化で不利
最小値を0にすることができない
→ AWS Fargateで考える必要をなくせる
GPUインスタンスが必要な場合などは自力
・複数のAutoScaling Groupの制御が複雑
片方縮退している間に
もう一方のAutoScalingが走ってしまったり
ルールを考えるのが大変
・スケーリングの設定がECSから独立
人によっては複雑に感じる
細かく設定できるので良い面も
・コンテナをバリバリ使っていきたいのに
コンテナとEC2のスケーリング両方考えないといけない

●Capacity ProvidersによるECSクラスターのスケーリング
・ECS Cluster
ECS Tasks
Capacity Provider
EC2 AutoScaling Group
図は便宜上包含させているが、紐付ける形
→ コンテナを起動したい
→ CloudWatch metrics
Capacity Provider Reservation
追加になる
Task実行がスケジュールされると変化
→ CloudWatch Alarm
→ AutoScaling
・コンテナワークロードの状態を反映したメトリクスでスケーリング
・Capacity Providerが自動的に設定
CloudWatch metrics
Capacity Provider Reservation
CloudWatch Alarm
AutoScaling

●複数のCapacity Providerを使うこともできる
・ECS Cluster
ECS Tasks: 10
Capacity Provider A: weight 3
EC2 AutoScaling Group
オンデマンド 60%
Capacity Provider B: weight 2
EC2 AutoScaling Group
スポットインスタンス 40%
・Taskのリバランスをやってくれる
●ECS Capacity Providersで登場するリソースや機能
・Capacity Provider
・Capacity Provider Strategy
・Capacity Provider Reservation
・Managed Scaling
●Capacity Provider
・ECSとコンテナ実行基盤の間をつなぐ
AutoScalingGroup, Fargate
Capacity Provider経由で管理
・1つCapacity Providerとして定義
AutoScalingGroup, Fargateというグループ
複数と紐付けることはできない

●Capacity Provider Strategy
・どのCapacity Providerにタスクを配置するか
・Task実行やService作成時に指定
・baseとweightで、複数のCapacity Providerにまたがって配置
このTaskはCapacityProviderBで実行したい
こっちのTaskはCapacityProviderA:B = 2:1とか
・Default Capacity Provider Strategy
Capacity Provider Strategyを指定しないとこれ
試験環境ならこれでスポットインスタンスなど
・weight
タスクの総数に対する指定
最終的にこのバランスに落ち着く
・base
先にこの最小数が配置される
・Capacity Provider Strategy with Fargate
基本は同じ
Fargate Spotは別のCapacityProviderを使う
AutoScaling GroupのCapacityProviderと混在はできない
●Capacity Provider Reservation
・リソースの割合を表すメトリクス
・キャパシティの予約率

●Managed Scaling
・CloudWatch Alarmとスケーリングポリシーを設定してくれる
・Capacity Provider経由でしか設定できない
手動では削除も、変更もできないようになっている
●Capacity Providerの実体
・CloudWatchに専用のメトリクスをつくる
・Strategyに基づいてタスク実行状況をメトリクスに反映
EC2でもECS Clusterでもない
EC2が存在していないと、値がブランク
0→1のスケーリングはできなかった
・ManagedScaling
Alarmとスケーリングポリシーを設定してくれる
手動操作できない
●まとめ
・タスク配置時にStrategyが考慮してメトリクス制御
・基本のしくみはCloudWatch, EC2 AutoScalingのもの
・CapacityProvider側で、ManagedScalingの設定をするだけ
■コンテナセキュリティ on Amazon ECS を改めて考える
金森 政雄さん [アマゾン ウェブ サービス ジャパン]

ECSのセキュリティを、NIST SP800-190を参考に整理
●なぜコンテナセキュリティを考えるのか
・AWSのセキュリティの考え方

責任共有モデル
データセンターやハードウェアやコンピュート層
そこにアクセスする権限の管理など
・ガードレールの必要性
オンプレミスの場合
統制がかかることでブレーキになっていることも
セキュリティサービスやAPIでの自動化
アジリティを下げずにセキュリティを担保
高速道路のたとえ
一般道と仕切られていることで安心してスピードを出せる
・AWSモダンアプリケーション開発のベストプラクティス
セキュリティとコンプライアンス
イノベーションの速度を犠牲にすることなく
セキュリティ脅威に対応
標準を自動化し、継続的に評価

●セキュリティ対策のサイクル
・リスクアセスメント
どんなリスクがあるのかわからないと始まらない
・方針決定
・対策実施
・評価
●NIST SP800-190
・National Institute of Standards and Technology
・SP800シリーズ
Special Publications
政府機関向け
民間企業でも有益
・NIST SP800-190
2017年9月
コンテナテクノロジーに関するセキュリティの問題と対応
●NIST SP800-190の構成
・1,2章
コンテナアプリケーションの技術的特徴の解説
・3,4章
コンテナテクノロジの5つのコンポーネント
リスクの解説、対策
・6,7章
攻撃シナリオの例
ライフサイクルに沿った考慮事項
・8章
結論

・executive summary
コンテナのイミュータブルで宣言的な性質で
手作業を最小限に
自動化されたアプリ中心のセキュリティを実現できる

●コンテナのコアコンポーネントとMajor Risks
・コンテナのコアコンポーネント
Image
Registory
Orchestrator
Container
HostOS
・ライフサイクルが、各コンポーネントと関わってくる

●Image Risks
・イメージの脆弱性
イメージ = 性的なアーカイブファイル
後で脆弱性が見つかる
動いているコンテナにパッチを当てることはできない
イメージの更新が必要
リスク
脆弱性を持つイメージから脆弱性を持つコンテナが生成される
対策
パイプラインベースのビルドアプローチ
イミュータブル性を活かす仕組み
・埋め込まれたマルウェア
イメージには悪意のあるファイルが含まれることがある
意図的、不注意どちらも
リスク
マルウェアも他の機能と同等のケイパビリティを持つ
攻撃ができてしまう
対策
継続的にイメージをモニタリング

・ECSでの対策方法
CoreOS ClairでECRのイメージをスキャン
image pushでスキャン
手動、APIで実施
カバレッジは確認が必要
コンピテンシーパートナーのソリューション
セキュリティ、モニタリング、コンテナ管理など

●Registory Risks
・レジストリ内の古いイメージ
レジストリには古いものが含まれていく
リスク
誤って脆弱性のあるバージョンがデプロイされてしまうことも
対策
安全ではないイメージやレジストリの削除
イミュータブルな名前を使ってイメージにアクセス
latestは最新を指すわけではないので注意

・ECSでの対策方法
ECRライフサイクルポリシー
リポジトリ内のイメージのライフサイクル管理を指定
タグ指定で、1つ以上残すなど

イミュータブルなイメージタグ
イメージタグの上書きを禁止できる
コミットハッシュなどの一意な値を使う事が多い
イメージの置き換えに耐性がつく
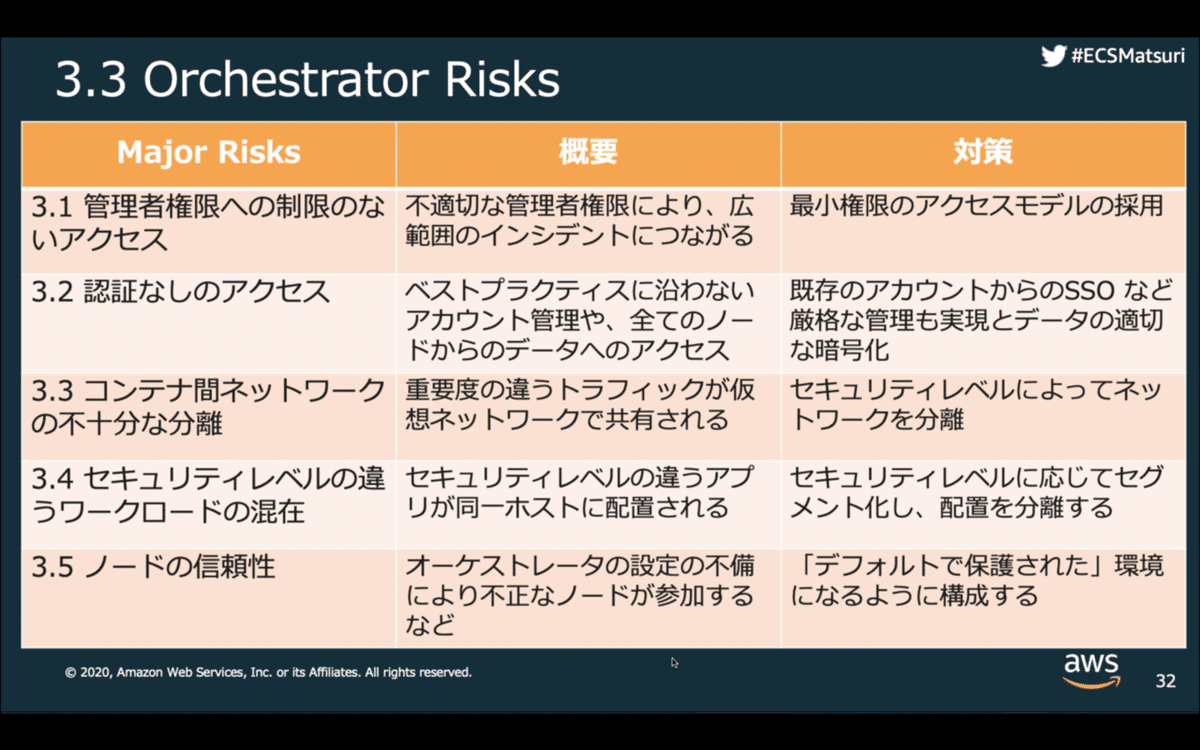
●Orchestrator Risks
・管理者権限への制限のないアクセス
環境全体をコントロールしたいはず
セキュリティレベルの違うアプリが混在されていることが多い
通常、別チームで管理
リスク
最小権限の法則に沿っていない
悪意、不注意で他のコンテナに影響を与えてしまう
対策
最小権限のアクセスモデル
テストチームは本番にアクセス不可など
・認証なしのアクセス
オーケストレータ独自の認証機構が、組織の認証機構と別
管理されなかったり、プラクティスが弱くなる
リスク
オーケストレーターが持っている高い権限で攻撃
対策
管理アカウントの多要素認証
組織の認証機構とシングルサインオン

・ECSでの対策方法
IAMでのセキュリティベストプラクティス

●Container Risks
・ランタイムの脆弱性
コンテナスケープを許すと危険
リスク
ランタイム自体を変更
対策
ランタイムの脆弱性を追って、対応

・ECSでの対策
Fargate
Fargateを使っていれば大丈夫!だけではない
ランタイムはパッチされるがテストが必要
ECSタスクのリタイア
基盤HWに回復不可能な障害や
プラットフォームバージョンに脆弱性がある場合
step
アドレスに通知がくる
当日になるとタスク停止
Fargate タスクリサイクル
ECSサービスのタスクでパッチが適用できない場合
個々のタスクを停止してシミュレートするテストが必要

●Host OS Risks
・ホストOSコンポーネントの脆弱性
コンテナ向けOSも、他のソフトウェア同様に脆弱性を持つことがある
リスク
すべてのコンテナやアプリに影響
対策
脆弱性チェック、アップデート
イミュータブルなホストOSの運用

・ECSでの対策
イミュータブルにホストOSを扱う
SSHを避ける
パッチ済みAMIから起動
コンテナの置き換え
ECSサービスとコンテナインスタンスのドレイン
置き換えstepの例
パッチ済みAMI作成
EC2インスタンスをECSクラスタに登録
古いコンテナインスタンスをDRAINING設定
コンテナが置き換わったら、terminate
●まとめ
・コンテナの特性にあった対応が必要
イミュータブル、宣言的など
・組織の運用文化やプロセスをコンテナに合わせる
セキュリティ対応の自動化
開発の責任範囲と権限拡張→DevOps
・コンテナのベストプラクティスに近い
アジリティだけでなくセキュリティにも貢献する
■その昔ECSでベストプラクティスだったものがアンチパターンになったもの、またはその逆
Toriさん [アマゾン ウェブ サービス ジャパン]

せっかくなので新しいプレゼンを試してみます
手抜きじゃありませんw

●ECSの特徴
・多くのインテグレーションを追加インストールなしで使える
・Fagateで足回りの考慮なしで動かせる
●ネットワーキング
・ECS serviceがALBを使えるようになった
・動的なポートマッピングができるようになった
・それまで
classicロードバランサーしか使えなかった
ポートマッピングが固定だった
・問題
LB
→ EC2:8080
container:80
→ もう1コンテナ立てたい
8080は80はマウント済み
→ もう一台EC2を立てる必要があった
・動的ポートマッピング
ALB
→ EC2:32050
container:80
:32051
container:80
コスト最適化はまだだった
デプロイを容易にしていた
・新しいバージョンをデプロイしたい
ローリングアップデートしかなかった
もう一つEC2を立てておいてローリングアップデート

・min, max HealthPercentが設定できるようになった
・awsvpcネットワーキングモード
none コンテナをネットワークにつながない
host EC2そのまま併用
bridge VPCとは別のcidrブロックに参加
・問題
Host/Bridgeモード
EC2
ENI
Container web
どこからでもOK
Container api
VPCだけからアクセス
security groupはENIにしかつかない
最小公倍数になっていた
・awsvpc
概念を説明するためにちょっと崩した図
EC2
ENI
Container
ENI
Container
ENI
実際にはEC2にENIがついている
CPU, Memは余っているのに
ENIのattach上限にひっかかる
・awsvpc Trunkingネットワーキングモード
none, host, bridge, awsvpc, awsvpc trunking
fargateはawsvpc
EC2ではすべて
・タスクごとにENCを使える
EC2インスタンスの上限を超えてENIを追加できる
trunkingしているだけだから
●モニタリング
・CloudWatch Container Insights
Map view
Taskにドリルダウンして詳細が見れたり
・以前は task metadata endpoints
sidecarとして外に送り出す処理をつくっていた
・問題
ECS/Fargate
Container Runtime
ECS agent(Fargate agent)
task metadata endpoint
container app
container sidecar
CloudWatch custom metricに書き込む
Datadogなども
●ロギング
・FireLens
プロダクト名でもあり、プロジェクト名でもある
プロダクト
アプリコンテナのログを
サイドカーのfluentd/fluentbitに流し込んてくれる
プロジェクト名
DockerHub / fluentbit for aws
・プロダクトのFireLens
Fargate
log driver
awslogs: cloudwatch logsだけだった
最近 splunkに対応
aws firelens
・何をしてくれているのか
ECSタスク
Container: app
stdout, stderr
firelens
つなぎこみ
設定injection
タスク定義やS3で設定
pluginの同梱
Container: fluentd/fluentbit
→外部へ
自前のimage管理が不要になった

●セキュリティ
・ECSタスクレベルでIAMロールを使えるように
・問題
EC2
task1
s3 get object
task2
dynamoDB table write
以前は、EC2単位だったのでSGと同じ、最小公倍数だった
・それぞれにIAMロールをつけられるようになった
秘密情報がちゃんと秘密に
parameter storeのARN指定
実行時に値を持ってきてinjectしてくれる
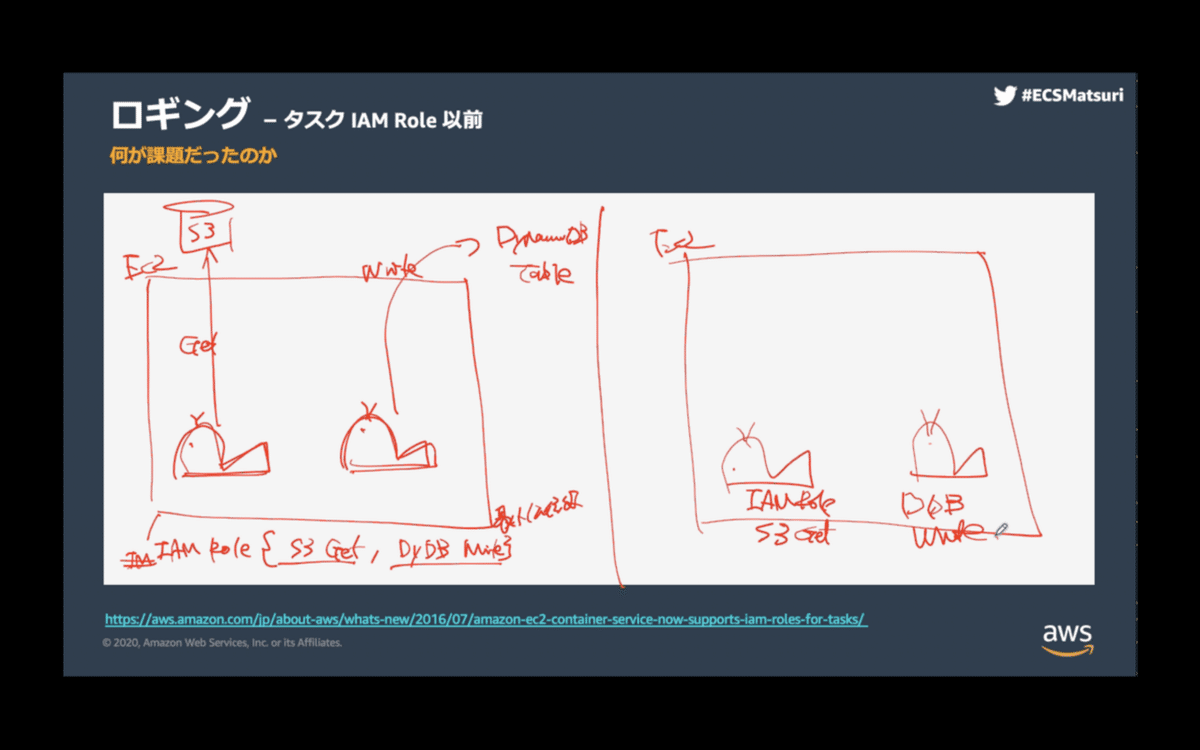
・以前の秘密情報
envにベタ書き
entrypointのbash
→secrets managerからget
→s3からget
●オペレーション・実行管理
・step functions、話題になりましたね
●ストレージ
・やめろと言われているがNFSのユースケースはある
・問題
EC2にEFSをマウント
ホストのディレクトリをコンテナにマウント
→ EFSがマウントされている仮想マシンじゃないとダメ
・EFSがコンテナを追いかけるようになった
●スケーリング
・cluster auto scaling ありましたね
AWSのプロダクトは90-95%がお客様のリクエストをもとにつくっている
パブリックロードマップでポジティブリアクションが多いものが実現された
■感想
Capacity Providers便利そうですね!auto scalingの話が出たら使ってみようと思います。
EventBridgeでLambda実行をスケジュールできるんですね!触ってなかったので使ってみようと思います。
CloudWatch Container InsightsのMap viewからのドリルダウン便利そうですね!betaの時に調べただけだったので、触ってみようと思います。
不便なところからユーザーの声で徐々に便利になってきた経緯がよく分かりました。欲しい機能はロードマップでリアクションしていかなくては!
現場の目的での使い方しか把握していなかったので、多くの使ってみたいサービス・機能に出会うことができました。登壇者の皆さん、運営の皆さん、ありがとうございました!
いいなと思ったら応援しよう!
