
2021-02-03 Data Engineering Study #6「改めて学ぶ、BigQuery徹底入門」 #DataEngineeringStudy

2021/02/03 に開催されたData Engineering Study #6「改めて学ぶ、BigQuery徹底入門」 のイベントレポートです。
●イベント概要
第1回勉強会ではDWHとBIツールをテーマに、DWHとしてはBigQueryとRedshiftを題材として取り上げ、比較などを行ってまいりました。また、第5回ではSnowflakeを題材に取り上げ、深堀りしていきました。
今回はData Engineering Study参加者の中でも利用者が多い「BigQuery」を題材に取り上げ、Google Cloud Platformのエンジニアの方をお呼びして深堀りをしていきます。
勉強会の前半では、主に初心者〜中級者をターゲットに、BigQueryが生まれた背景やBigQueryが何故「速い・安い・うまい」のかを概論として講演いただきます。
後半ではBigQueryの論文を引用しながら、Disk IOを最適化するための仕組みやシャッフル最適化の仕組みなどを解説頂き、中級者以上の方にもお楽しみ頂ける内容を予定しております。
■あらためて入門するBigQuery: データ分析プラットフォーム
寳野 雄太さん [グーグル・クラウド・ジャパン]


●データ分析、活用を支えるデータ基盤
・データ基盤と言っても範囲が広い
データソース
SoR
SoE
IoTなど
保管・分析
活用
管理
加工・仲介
・データエンジニアがいることで
データの利用者が効率的な分析ができるようになる

●データ分析のステークホルダー
・データアナリスト
SQLでビジネスユーザーの要望に答える
アドホッククエリが早く返ってきてほしい
BIツールで素早く探索したい
・ビジネスユーザー
ビジネスの進捗をトラックしたい
・グロースハック/デジタルマーケ
リアルタイムの指標で施策を実施したい
ネイティブアプリ、webのデータをCRMと連携したい
データサイエンティスト、アナリストからデータ共有してほしい
・データサイエンティスト
Jupyter Notebookからいい感じにいじれるデータソース
Sparkも使いたい
・データエンジニア
ステークホルダーの要望が多い
インフラより、データパイプラインのビジネスロジックに注力したい
●BigQueryとは
・2006
Googleの中で使われてきたデータ分析のシステム
MapReduceにSQLインタフェースをつけたらビジネスユーザーが爆発的に増加
・2010
サーバレスでスケーラブルなデータウェアハウスとして売り出した
・2021
データ分析プラットフォーム
提供から10年経過して、あらゆる面でこなれている
日本語サポート、事例・ブログ・コミュニティ
セキュリティ面も対応してきた
●基本のクエリ実行
・エクスプローラ
データセットが見えている
・はじめからweb uiで提供
テーブルにはメタデータも統合されている
補完の効くクエリエディタ
・2.2GBの全文検索、group by、countで4.4sec

●課金体系とワークロード管理
・クエリによってスキャンされたテーブルのサイズで課金
・課金制限、定額料金、事前に料金がわかる
150万溶かした話のブログでも紹介してくれている
・オンデマンド料金
Googleが持っているリソースから、良い感じに払い出してくれる
・Reservations 定額料金+flex
スロット(コンピュートリソース)を買い占める
BigQueryMLも含めて定額
・組み合わせて利用できる
●スプレッドシートによる最新データ共有
・結局スプレッドシートは最強
でもメモリに乗せて実行するには限界がある
・GoogleスプレッドシートとBigQueryを連携できる
数PB、数億行のデータも、裏でBigQueryが動いた結果を利用できる
●ネイティブアプリ、Web解析連携
・Analytics360, Firebaseからワンクリックで利用可能に
CRMやログも利用できるようになった
FireMessageingの対象をBigQueryから引けるように

●データサイエンスプラットフォーム連携
・Jupyter NotebookのBigQuery extension
・レイクとウェアハウスどう使い分ける?
生データを残して、ウェアハウスに入れるって二重持ち
hadoop使いたい
・BigQueryのデータをHadoop/Sparkに高速に読み出せるように
ロードせずにフェデレーションとしてBigQueryを使う
●BigQuery ML / AutoML
・SQLからモデル構築できるように
●データ共有、クエリ共有
・二重持ちせずに、共有
IAMで設定するだけ
・自分のプロジェクトにデータを入れておいて、参照権限を付ける
クエリの保存、共有もできる

●QA
・データレイク、データウェアハウス、データマートの中身のイメージを掴みたいです!
それぞれどういう形式でどういった状態のデータが保管されているのが一般的なのでしょうか?
データウェアハウス、データマート
テーブルの形になっている
概念的なもの
DBに入っていれば何でも呼ばれ得る
データウェアハウス
集計ができる形になっている
データマート
ビジネスユーザーのロジックに寄り添う
ビジネスユーザーが使いやすいように、間違えにくいようにつくっておく
データレイク
ベンダートークだと、object storage
生のデータがそのまま残っていればデータレイクと呼べると思う
派閥があるので、盛り上がりそう
・Big Query MLの値段感、他のDWHに対するBig Queryならではの強みなどお伺いしたいです。
Big Query MLの値段
スキャンするデータのサイズで決まる
$250/TB
GPU使ったりする場合に比べると安く仕上がることも
自分でやるとしたら
分散処理、分散環境からスタート
立てた後、TBあたりいくら掛かるか考えると安く仕上がる
お客さんが選ぶ理由が変わってきた
昔から使っている人
クエリプランがめっちゃいい
実行予定が詰まっていても、後ろを止めない
データレイクとウェアハウスを行き来できる
リアルタイム分析
データ分析のユースケースが増えてきたから理由が変わっているのかも
・Tableauなど現在多くの分析ツールもありますが、違いはどういったところでしょうか
(クラウド処理かローカル処理の違い?)
TableauはグラフィカルなBIツール
相互補完
裏側でBigQuery
Lookerとかも
SQL書いたりする人はBigQueryを直接触る
・BigQueryを学ぶ際に役立ったものがあれば、教えて下さい
GoogleCloudではじめる実践データエンジニアリング入門
2/20 出版予定
■データの価値を引き出す BigQueryのアーキテクチャ
西村 哲徳さん [グーグル・クラウド・ジャパン]


●データ分析プラットフォームに必要な要件
・非機能的な要件になる
・可用性
色んな人に使ってもらったら高い可用性が必要
・性能・拡張性
データの量・種類が増えれば
色んな人が使い慣れたツールでBigQueryにアクセスできること
●BigQueryのSQL標準化の歴史
・2000年代はじめ
SQLはスケールしないのでGFSやMapReduceで開発していた
分析ジョブを実行するのに時間がかかった
・DremelでSQL採用
web規模のデータセットをかんたんなSQLで分析
方言が強かった
結合もサポートせず
半構造化も扱えるようになった
・SQLの標準化&オープン化
Google社内で標準化の動き
ANSI SQLに準拠
結合、分析関数、複雑なSQLなどをサポート
そこまで大変な変換は必要なくなって始めやすくなった
いろいろなしくみのSQLへの回帰が促された

●性能・拡張性・可用性・サーバレスを支えるアーキテクチャ
・現在
ストレージだけでなくメモリも分散
ペタビット規模のネットワークで連携
●2006年 ストレージ分離
・Dremel
シェアードナッシングアーキテクチャ
ワーカーとディスクをセットでスケールしていく
・つらみ
CPUだけ増やしたい、ストレージだけ増やしたいができない
ノードを増やすと均等に分散し直し
ワークロードが増えると、、、
利用率の低下
●2009年 Borg
・k8sの前身
数万のマシン、数十万のコア
増大するワークロードに対応
・Dremel専用で
独立したサーバで構成される複製ストレージ構成へ変更
ペタバイト、数兆行のデータセットが扱えるように
ストレージが密結合に
・DFSのような分散ストレージが良いのではないか?
ネットワークのファブリックがペタビット規模に劇的に進化
GFSを使う必須条件が満たせるようになった
スケーラビリティ、堅牢性が向上
今はColossus
・BigQueryではメモリーも分離
ストレージを分離するのは最近のトレンド
結合や集計のシャッフル処理
週毎のデータを振り分けて
メモリで集計
メモリを大量に使って、ボトルネックになってしまうことも
ワークロードが増えていくと二次関数的に時間がかかっていく
ローカルメモリから分離していこうな流れに
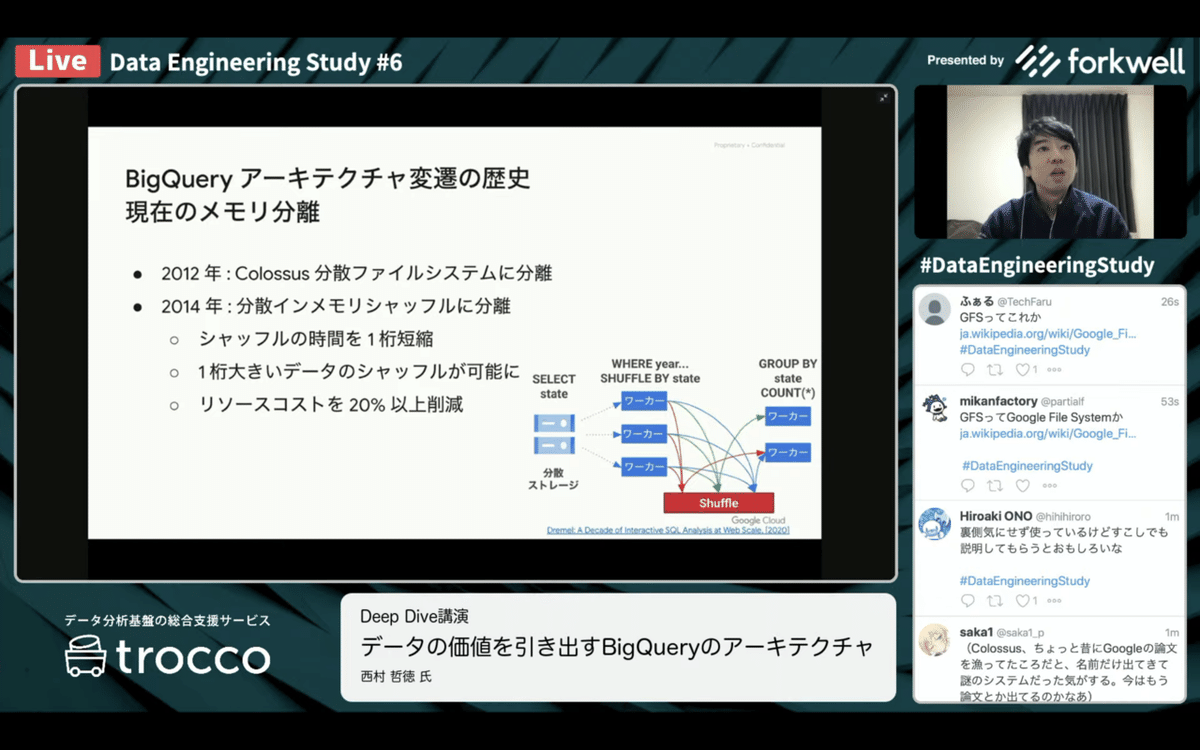
●2012年 Colossus
・分散ファイルシステム
●2014年 分散インメモリシャッフル
・ワーカーとは別の場所に格納される
より大きな結合ができるように
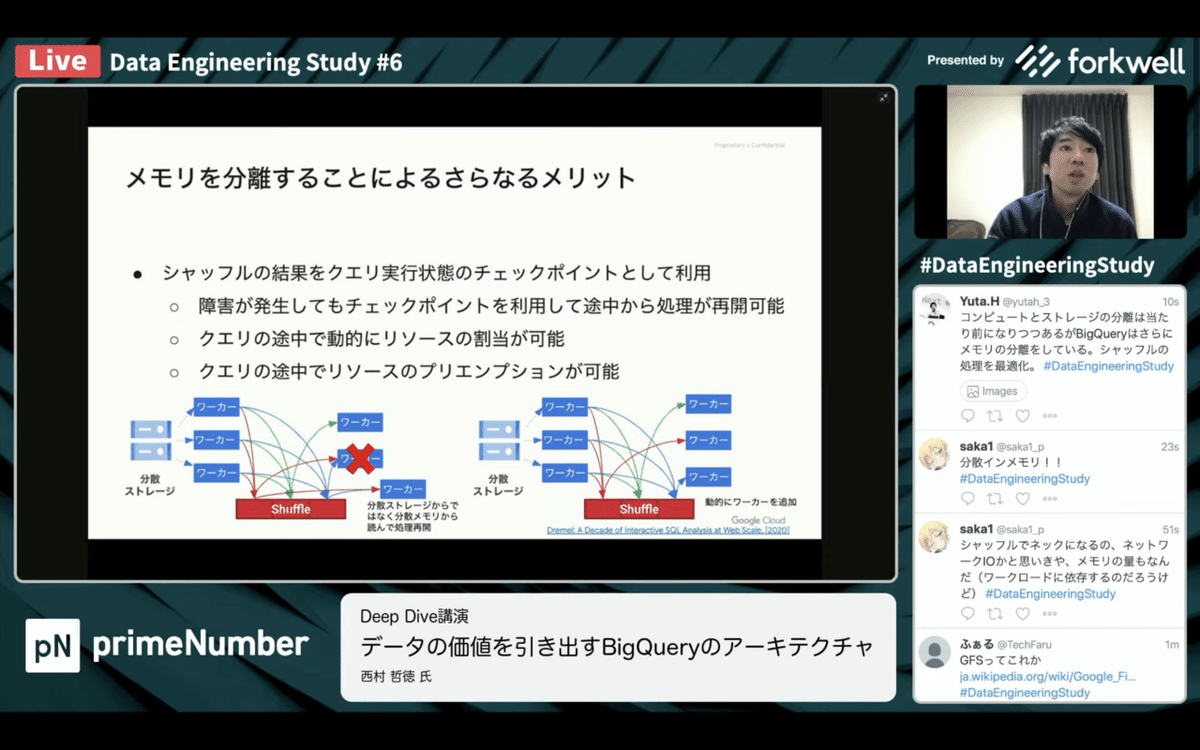
・メモリを分離することでさらなるメリット
チェックポイントを利用して途中から処理が再開可能
動的にリソース割当が可能
リソースの空き状況に合わせて、一気に処理を終わらせたり
クエリの途中でプリエンプションが可能
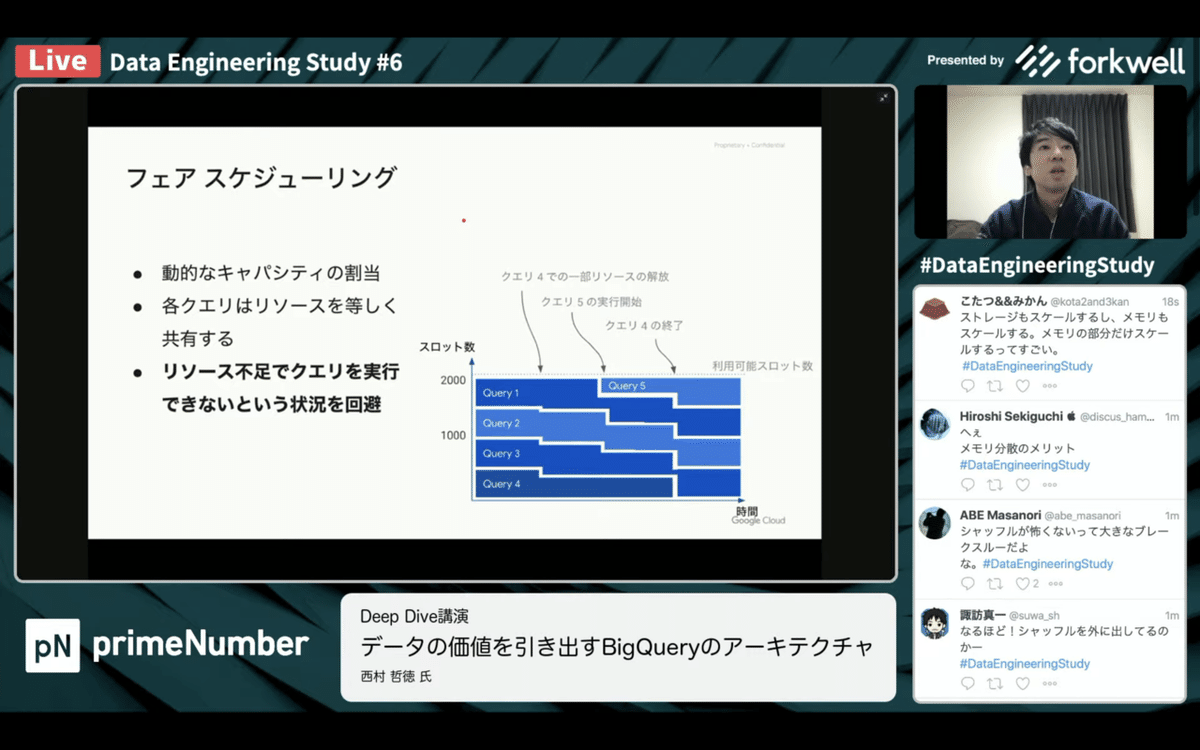
・フェアスケジューリング
リソース不足でクエリを実行できないという状況を回避
・Capacitor カラムナフォーマット
カラムナはDWHではデファクト
Capacitorの特徴
階層型の深いところでも祖先をたどる必要がない
skip index
ボトルネックを見つけて解消することを10年繰り返してきた
これらが裏の見えないところで動いている
●QA
・BigQueryのプレビューでデータが表示される裏側の仕組みは?
web uiでテーブル選択時にプレビューできる
詳細は把握していない
キャッシュしているものの一部を出していると思う
・中長期的にはどのような方向に進化していくと思われますか?
お客様目線で進化していく
これまでもユーザーの声で上がってきていたもの
・streaming insertってさっきのアーキテクチャとは別のしくみ?
直近のデータをバッファリングして
insert、読み出し時もバッファを利用していると思う
・コンピュート、ストレージ、メモリが分離されているものは他にない?
メモリまで分離しているのはBigQueryだけでは?
・BigQuery に格納されているデータの冗長化はどのような仕組み?
BigQueryの中では、zoneをまたいで冗長化されている
リードソロモン符号つかってたかと
・BQMLはさっきのアーキテクチャとどう関わっているの?
BigQueryのエンジンとAIプラットフォームのものを
アルゴリズムによって使い分けている
■パネルディスカッション
寳野 雄太さん
西村 哲徳さん
ゆずたそさん
渡部 徹太郎さん
山田 雄さん
塩崎 健弘さん

●実際に運用が始まるとどのぐらいの費用がかかるものなのか?
費用を抑えるコツは?
・費用がかかるのはデータがでかい時
データサイズのチェック
・費用のモニタリングもできる
・billingコンソールに予測額も出るようになった
ユーザーがスキャンできる量を制限掛けることもできるので部署ごとに制御も
・リアルタイムでクエリを分析してslack通知するしくみをつくった
ブログにほぼそのままロジック載せてます
スロットたくさん使ってるのもチェックしている
・他のDWHでは、やばいリソースだと悲鳴を上げてくれる
BigQueryだとしれっとやってくれる
・負荷のかかるバッチがあるので
バッチに合わせてflexを買って、リリース
・100スロット2000ドルから使えるようになってる
BigQueryは上下しやすいので、予算で調整できるのは便利
・規模によるけど、予算に着地させる必要があるので、扱いやすそう
●BigQueryを学ぶ際に役に立ったものは?
・日本語の資料は当てにならなかったので、隅から隅までローラー作戦
・BigQuery Definitive Guide
・google cloud japanのブログはプラクティカルで役に立つ
・cloud on airのスライドから入って、ドキュメントで深めていく
・民主化していく場合
ビジネスの人向けなら、キャプチャ取って、こんな感じで使えますよ
SQL掛ける人向けなら、クエリを共有してしまえば良い
・敷居が低い、GSuite持ってる会社なら、URL渡すだけで共有は終わり
・Google Nextの動画が参考になる
・BQ Fun, GCPUGも良い
●クラウドストレージにデータレイクを作る方法が一般的
生データをそのままDWHに取り込んでデータレイクの代替とする事もできる
どのように使い分けるべき?
・GCSにデータレイクはつくっていない
ほぼ全てBigQueryに入れている
カラムが予測不可能なレイアウトの場合は、どうテーブルに入れる?
jsonで入れて、json extractで読み出す
・動画、画像になるとストレージに追いて、URLをBigQueryに入れている
・だいたいのものは、BigQueryに入れてしまっている
入れているデータの中で、レイク的なものウェアハウス的なもので別れてくる
●どこにどんなデータがあるのかなどの管理
利用者に上手く共有するコツとか無いですか?また、その管理方法。
(データセットやテーブルなどが増えれば、何がどこに入ってるとか分かりにくくなるので。。。)
・カタログ的な話かな?
・みんな困っているのでは?
データ基盤で考えると、データカタログだけでは足りない
どこのデータソースからって情報が抜けてしまう
・データ分析基盤全体を見ている人だと、リネージが気になったりする
自分のデータだけ見る場合は困らない
・「この1,2,3ってどういう意味なんですかね?」のようなやり取りはある
このデータがわからなかったら、このslack channelで聞いてね、的な草の根活動
・解こうとする問題が広い
データ利用者で、分析するデータが決まっているのであれば、メタデータで十分
ガバナンス的な人だと、ACL的なものとか重厚長大になってしまいがち
infomaticaとかって昔からあるけど、現場に落ちてこない
lookerみたいなBIツール側で定義づけしてます、もありかもしれない
・個人情報の在り処
個人情報なしって申請してきたのに入っていたりでヒヤリハッと
BLTとかを組み合わせて、パイプラインで検出できるようにしたい
・3000テーブル10万件だとなんじゃこりゃ
モノによってはちゃんとレビューすれば良い問題かもしれないし
要件定義で整理できるものかもしれない
■感想
Data Platform Dayなどで伺っていた、早い、安い、使いやすいのコンテキストがはっきりした印象でした。
・データの活用が普及してきて、データ分析基盤のユースケースが広がった
・各ユースケースを楽に実現できるBigQueryの強さ
・10年掛けてこなれているuiとアーキテクチャ
・分散インメモリシャッフルの自由度の高さ
・それを支えるインフラの強さ
この強みは他で真似できそうにありませんね!データを活用していくのであれば、肩に乗らない理由はもうない気がします。
登壇者の皆さん、運営の皆さん、ありがとうございました!
いいなと思ったら応援しよう!
