
2019-05-30 de:code 2019 Day2 #decode19

2019/05/30 に開催された de:code 2019 Day2 のイベントレポートです。
■Day1 の様子
■実践 NoOps ~NoOps で本当に働き方は変わるのか?~
岡 大勝 さん (NoOps Japan 主催 株式会社 ZOZO テクノロジーズ)

●自己紹介
・銀行の情シス -> DEC -> HP -> Rational -> ゼンアーキテクツ
-> ZOZOテクノロジーズ
・アーキテクチャの変革を手伝ってくれないか?
-> NoOpsやって良いですか?
-> OK!
●NoOps
・2年前のde:codeから始まった
・NoOps = No Uncomfortable Ops
運用はやめられないもの、どんどん改善していくもの
システム運用の "嬉しくない" をなくす
・ユーザーの体験を妨げない
夜間使えない、アクセスが集中して使えない
何百万人同時にきても
・トイルの最小化
手作業 / 繰り返される / 自動化できる / 戦術的
長期的な価値を持たない / サービスの成長に対して O(n)
-> サービスがスケールしても手作業は変わらず済むべき
・運用保守コストの最適化
システムにはお金を払っていることを忘れない
●攻めのNoOps / 守りのNoOps
・守りのNoOps
less ops
SRE本
・攻めのNoOps
システムの構造的にOps不要に
現在の技術なら実現できるのではないか?
・ユーザーから見ると
30秒以内に整合性が保てているのであれば
障害ではない
・洗濯しない
買って、使って、捨てる
現実ではムダ使い
システムなら実現できる
・Azure東日本が全ダウンしたとして
30秒以内に 西日本で立ち上がる
これを実現できるのではないか
●NoOpsは働き方改革なのでは?
長時間労働の是正
柔軟な働き方
労働生産性向上
-> NoOpsが効くのでは
NoOpsでIT部門の働き方は変わるはず
佐藤 力 さん (富士フイルムソフトウエア株式会社)
渡壁 佑也 さん (富士フイルムソフトウエア株式会社)
●IMAGE WORKS
・写真、デザインの管理・共有クラウドサービス
・企業向けのDropBoxのようなイメージ
・伊勢・島サミットの公式写真公開の裏で使われていた
●Before
・深夜にしかリリースできない
終電で出社、定時まで作業など
・サーバが増えればリリース作業も増える
・誰かがuploadしていたら、他の人がdownloadできないなど
●What
・App Service, Azure Functionを利用
・Azure DevOpsで自動化
・ユーザからはPaaSを通してアクセスするように構成を変更
●Happly
・サービス停止無しでいつでもリリース
・ボタン一つで本番環境に
・想定外のエラーが出てもサービスは継続
●Bad
・10%くらいの確率で自動リリース失敗
・正常なステータスで終るので、確認が必要
uploadが大丈夫でも、downloadが大丈夫とは限らない
・細かく分けるほど理解することが増える
●After
・いっぱい手を動かしていた
-> 頭を使う時間に変わった
●成果が見えにくい
・コスト
事業系 / 保守系 / 改善系
・取り組み初期
事業系: ±0 / 保守系: - / 改善系: +
-> 経営から見たら変わらない
・NoOpsが目指す姿
事業系: + / 保守系: - / 改善系: +
・多分うまくいかない
事業系: + / 保守系: - / 改善系: -
-> 運用コストは人を減らすしかない
●SREチームをどう編成するか
・一般企業ではSRE本のようには行かない
最新の戦術を持ってきても
メンバーの能力が伴わなければ
・まだ試行錯誤中
運用、開発からコンバート
新規教育
清水 博 さん (アサヒプロマネジメント株式会社)
小森 寛之 さん (伊藤忠テクノソリューションズ株式会社)
●アサヒビール
・飲料を扱っているので、ITからは遠い
オンプレ主義
Windows、Oracleが多い
・社内向けのしくみ
5~600人の小売向けの営業が利用
データを活用、社外のデータも活用、AI使ってほしい
・アーキテクチャ
AKS -> BigQuery -> Azure上にデータを貯めている
all PaaSでもオンプレでやっていることが実現できるのでは?
●現場の声 1
お客さんの作業が自動化されているのに
自分たちの作業が変わらないのはなぜ?
・RPAに任せよう
機械的な作業はお任せ
外部から連携されるデータのクレンジングもRPAで
・まだRPAを動かすPCをローカルに持っている
-> フルマネージドへ
●現場の声 2
リソースの監視、増強を手動で実施している
・スケーラブルアーキテクチャ
新規、再構築のタイミングではできる
動いているレガシーでは難しい
ここを変えることで大きな効果が出る
・コストメリットをアピールして、改善の時間を創出
●現場の声 3
管理データの洗い替え作業をまだ毎月流している
・日次化、基盤の高速化
ユーザからの無茶な依頼にも柔軟に対応できるように
・データ基盤は種類を増やすほどにトイルが増える
-> NoOpsのサイクルが必要
●NoOpsな活動の結果
・当たり前になってしまっていて、カイゼンの意識がなかった
-> NoOpsな活動で、意識が変わってきた!
岡 大勝 さん (NoOps Japan 主催 株式会社 ZOZO テクノロジーズ)
無茶振りは、価値に気づかせてもらえるきっかけ
●まとめ
・Design for NoOps で
大幅に作業は減らすことができる
が、ゼロにはできない
分散させる
-> 弾力性、回復性が増える
-> 複雑になる
・手段を限定しない
攻めと守りの併用が必要
守りだけでは疲弊してしまう
技術を限定すると効果も限定的になる
・ビジネスを含めたゴールイメージを携えて取り組む
・NoOpsを起点とする働き方改革

photo by @hiro128_777 さん
・NoOpsのNoは
古い習慣をやめる
固定観念を捨てる
これにはいくらカネがかかる
・設計で無駄を「なくす」ことを考える
システム、ビジネス、組織
・NoOpsの旅を楽しむ
大変だけど楽しむマインドセットが大切
NoOpsは
テクノロジー駆動でビジネスと人が幸せになるための活動
ワクワクを共有しましょう!
■「ここでしか聞けないマイクロサービス on AKS 導入のなま苦労話 by オイシックス・ラ・大地」
寺田 佳央 さん (マイクロソフト コーポレーション)
長尾 優毅 さん (オイシックス・ラ・大地株式会社)

●オイシックス・ラ・大地
・安心安全な野菜を提供
・3つのサービス
Oisix
RadishBoya
大地を守る会
・PURPLE CARROT
子会社化
アメリカでも展開
・とくし丸
トラックで移動するスーパー
●なぜオイラさんはマイクロサービス化に?
・19年間の開発の積み重ね
・数年前からモノリスに限界を感じていた
スピードに限界
テストしきれずにバグを生んでしまう
横にスケールするのも大変
・もとの構成
LB
nginx
jetty - JSP
oracle
●5daysのk8sハッカソンはどうでした?
・k8s化を決めていたがスキルを持った社員がいなかった
・システムの一部を切り出してみた
・会社で抱えている課題をハッカソンで
だいたい3日くらいでさわれるように
●マイクロサービス(MSA)にして良かったことは?
・開発
小さくなるから 1 or 2日で開発できる
-> ビジネスへの貢献
中途エンジニアが入りやすい
開発者のモチベーションにもつながる
・運用
スケールアウトが楽になった
何も言わなくてもスケールできるアプリをつくるように
ログローテの考慮がアプリから切り離せた
・巨大なモノリスだと
バグのポイントは見つけられても
影響範囲が分からない
-> スキルがあっても活躍できない期間ができてしまう
・k8sを使うときはスケールアウトを意識
スケールアップはk8sに合わない
CPUパワーが必要ならVMをスケールアップすれば良い
なんでもAKSでやろうとしないでください!
●1年経ってどうなりましたか?
・本番稼働: 9 (開発中: 20)
・バッチ処理の実行時間が 1/2 にできた!
●苦労したことは?
・開発
モノリスとの並行稼動
マイクロサービスで切り出し
動くようになってからAzureにデータを移す
学習コスト
AKS、API Managementなど学ぶことは多い
インフラを意識した開発
コンテナ以外にも
CDN -> API Man. -> Ingress
何が正解か分からない
・運用
3rdパーティのログ管理ツールで半日くらい止まった
分散させた方が良さそう
サーキットブレーカー、分散トレーシングなど
考えることは多い
サービスのクラスタ配置
全部のせたら全部落ちてしまう
どこくらいのバランスが良いのだろう?
AKSのバージョンアップの不具合を引いた
構成変更の不具合
つくった後で構成を変えると苦労する
・正解はない
どこかで成功したからと言って
自社で同じ構成ではうまくいかない
組織ややりたいことによる
自分たちで試しましょう!
・1クラスタあたり 100 node が限界ですが
絶対 100 node なんて作ってはいけません!
2~30 node 程度のミニサービスを作りましょう!
システムは絶対壊れるもの
terraformなどで作り捨てる
●直近での課題
・オンプレミスOracleとの連携
オンプレOracleとAKSのレイテンシが厳しい
キャッシュやキューで対応しているが、難しい
-> オンプレ版AKSがほしい
Azure Stackで近いことはできます
お高いですが
・既存のDBから引き剥がすのは難しい
ノウハウを共有しましょう!
●MSA化の理想と現実
・Polyglot Language
サービス毎に最適な技術スタックが選べる!
現実は、開発/運用体制からJava縛り
-> 将来は多言語に
・max-pod=30 がデフォルト
azコマンドで増やせるが
IPアドレスが枯渇して
スケールできなくなってしまうことも
・新鮮な情報を公開するべきだけど
日本語ではまだまだhello worldレベル
英語の本家資料を読みに行きましょう!
●課題を乗り越えてきたモチベーションは?
・既存のモノリスをメンテし続けることに比べたらできるハズ!
・ある程度トラブルは覚悟していた
・開発者へのメリット
テストの自動化範囲が広がる
・運用者へのメリット
担当を各開発と分業
●今後の展開
・MSA化を推進
・AKS西日本リージョンへ分散
・マルチクラウド化
●組織的には?
・エンジニアが足りない から始まった
採用には苦戦中
・エンジニアを大切にすることが大切
●良い人材を採用するためには?
・楽しいと感じてもらえる環境
・コミュニティ、イベントでoutput
●MSA/k8s化のハードルが高いと感じる人は?
・prodでk8sを使っている人は、日本ではほとんどいない
-> 一緒に学んでいく
●新しい人が入ったらどうキャッチアップしますか?
・開発環境、テンプレート準備
・チーム開発でフォロー
・モブプロを採用
モブワークは便利
開発に限らず、インフラなどでも
・社内ハックフェスト、勉強会
●インフラなどでやったことは?
・ブランチ戦略なし ->github flowを採用
・CI/CDの整備
・品質管理チームを立ち上げた
●これからはじめられる方へ
・MSA / k8s が唯一の解ではない
・いきなりはじめないで、やったことある人/会社に相談
・既存サービスの切り出しやすいところから
・k8sインフラ運用は専任が必要
-> マネージドサービスを活用
千里の道も一歩から
一歩を踏み出す勇気が必要
怖いというか、不安でしたが
安心・安全を食卓に届けるために
できると信じて
■Azure Serverless を活用したリアルタイム Web のすべて
芝村 達郎 (しばやん) さん (フリーランス / MVP for Microsoft Azure)
井上 章 (チャック) さん (マイクロソフト コーポレーション)

●Azure Serverless
・App Service / Function App / Kuberntes Services
・去年のBuildから2つ減った
メッセージを絞ったが
Service Publicは残るはず
●Serverlessなサービスは多い
・ACIは重要。いろんなサービスの下で使われそう
●そもそもserverlessとは
・サーバーがないわけではない
・意識せずに使えるサービス
使った分だけ課金
1インスタンスないと定義できないサービスも多い
24h -> 使った時間だけ、の効果は高い
・開発に集中できる
●PaaSとServerlessはあいまい
・Azureの場合、気にする必要はない
VMを意識せずに使えるのがAzureの特徴
課金体系などは違うが、意識しないでよいのは共通
アプリ開発者フレンドリーは今も昔も
●WebAppのトレンドも変わりつつある
・SPAへ
・ブラウザの機能差がなくなってきた
レンダリングエンジンが減ってきた
・Static Site Generatorの受容
●データバインディングが重要に
・部分を動的に書き変える
・ビュートモデルの分離
・フレームワークで便利に
●リアルタイムWeb
・サーバと常時接続されていても良いわけではない
・他のユーザの行動、裏の変更がリロードなしに反映
・何をトリガーにしてクライアントへプッシュする?
ここが決められないと、サンプルがチャットに
●バッチ処理では体験が損なわれている
・ユーザにはストレス
操作が反映されるのが1min後でもストレス
・管理系でも同じ
CosmosDBでラムダアーキテクチャなど
・UXを改善する方法としてリアル雨タイムWebを利用
UXが悪いとユーザは離れてしまう
気持ちよく使えるように
●実現するには?
・イベントドリブン
ポーリングはユーザが少ない or 1分間隔くらいなら問題ない
スケールを考えると使えない
・クライアントへのPush型津神
実質 WebSocket / gRPC の2択
・スケーラビリティを顧慮した設計
Azure Serverlessを使うと比較的簡単
●EventGrid
・ソース -> EventGrid -> ターゲット
フィルタリング、ハブなど
・Storage Blobイベント対応
・多くのイベントソースに対応
Mapsのジオフェンスなど
・信頼性の高い構成
●CosmosDB(ChangeFeed)
・順序の担保されたキューとして使える
・ドキュメントの通以下、扁壺、削除でイベント発行
・Azure Functions の CosmosDB Trigger
-> 関心に注力できる
●Logic Apps
・コネクターが多い
・ユーバーに近い部分でのイベント
メール受信、OneDriveに新規作成など
・処理した結果をCosmosDBに保存も簡単
-> ChangeFeedで更に自由な後続へ
●Functions
・Azure Serverlessの根幹
Consumption / Premium Plan
イベントベースでのオートスケーリング
・多くのイベントソースに対応
Storage Queue, Service Bus, Event Hub, IoT Hub
Binding / Triggerで、アプリに集中
●KEDA
・kubernetes-based event-driven autoscaling
Azure Functionsに近いスケーリング
・川崎さんがデモしてくれてました
動画が公開されたら見てみてね!
--- リアルタイムWebの実装 ---
●イベントを用意
・ユーザの入力、操作
通常のPOSTリクエスト
・データの追加更新削除
Strage Blobの変更をEvent Gridで受ける
CosmosDBのChange Feed
・IoTデバイスからの入力
値の変化をEvent HubやIoT Hubを経由して
●クライアントへのPush通信
・WebSocketの負荷分散は大変
今だとRedis一度
HAを考えると非常に頭が痛い
現実問題、落ちる
・SignalR Serviceを使うとインフラを考える必要なし
まだオートスケーリングはない
●Azure SignalR Service
・フルマネージドなSignalRバックエンド
・ASP.NET Core SignalR, Functionsから利用できる
・Functions + Static web hostingで
●SignalR Serviceを使った構成例
・まだSignalR Serviceだけスケールしない
・部分的にリアルタイムwebを組み込むことも

●スケーラビリティ
・Azureにほぼ任せる
Azure Monitor, Application Insight
でのモニタリングは必須
・イベント処理はステートレスに
・ステートフルな処理はDurableFunctionsで
極力ステートレスにしましょう!
●NoodleLens Architecture
・という、ここまでの説明が全部入ったサンプルがあります!

●まとめ
・Azure Serverlessでイベントドリブンの活用
・リアルタイムweb == 常時接続ではない
・スケーラビリティを考慮した設計
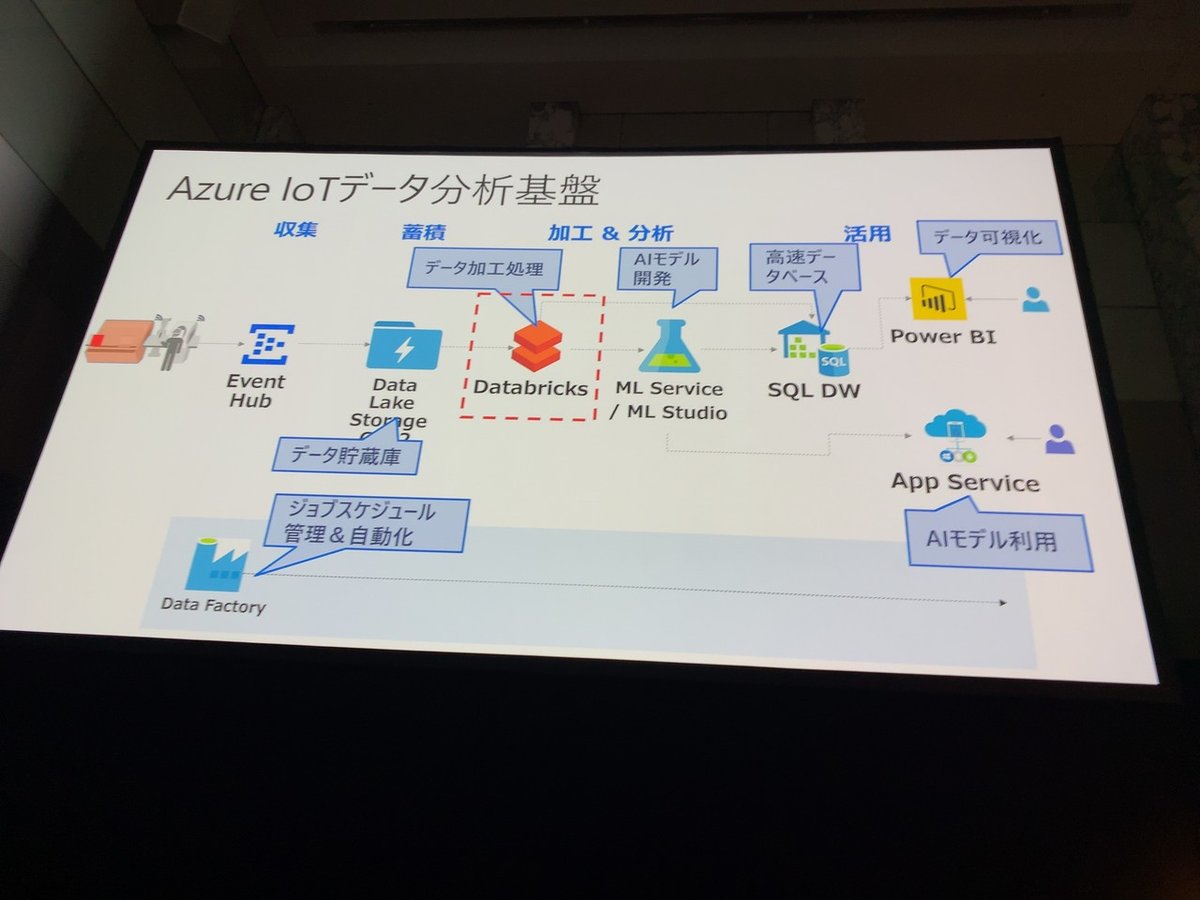
■機械学習のためのデータ加工 ~ 特徴量の見つけ方と作り方
望月 美由紀 さん (日本マイクロソフト株式会社)

●機械学習のプロセス
1. データ準備
ここがポイント!
2. モデル作成
アルゴリズム選択
パラメータチューニング
-> Azure ML Service など誰でも作れる時代
3. モデル評価
精度確認
検証評価
3. 業務適用
スコアリング
実運用化
●データ準備
・特徴量作成
特徴量検討
データ収集・加工
※ここの話です
・クリーニング
欠損値保管
標準化
対数変換
離散化 など
●特徴量は5W2Hの観点で洗い出す

●予測モデルを活用するシーンをイメージ
・取れるタイミングなどの整理
・ビジネス目的1: 販促イベント計画やスタッフ配置最適化
来月1ヶ月分を、今月中旬に予測
中旬だと月末に出るデータは使えない
-> 特徴量から外す
・ビジネス目的2: 生鮮品・惣菜の廃棄ロス削減
1週間先を、前週末に
-> こっちなら用意できたり
●母集団の検討
・学習期間
季節性も考慮して2シーズン分くらいほしい
・除外
何らかの事情でこの期間はデータがない
改装期間中だから、イレギュラーになる
など、言われてみれば当たり前だけど、実務では忘れがち
●ユーザー評価がない例
・やりたいこと
顧客の目的、希望、嗜好に沿った飲食店をレコメンド
・Matchbox Recommender
評価、ユーザ属性、アイテム属性 -> 評価を予測
・データ課題
アンケートデータを使えなかった
・利用回数を評価にしてみた
マイナーな飲食店ばかり
レコメンド結果が著しい方より
・原因
基礎集計で利用回数を確認
ほとんどの人が1回、maxで54回
・リピート利用を評価データとして採用
0: 利用なし
1: 1回利用
2: 2回以上利用
-> 利用していない = データなし -> 0を作成
・学び
事前に、基礎集計で分布や特徴を理解
秒無目的に合わせて、データをカテゴリ化、離散化
評価データは0〜5が望ましい
試行錯誤の繰り返し
●教師データがない例
・やりたいこと
工場ラインの設備装置の故障・劣化予測
メンテナンス計画を最適化
・データ課題
まだ一度も故障していない
-> 予測モデルは作れない
・クラスタリングで異常値を検出する方針へ
仮説: サイクルごとのセンサーデータは同じ
・特徴量イメージ
センサー項目10項目
1サイクル = 60秒
-> 600項目
・スケールの異なるデータは標準化
・クラスタでグルーピングして可視化
学習モデルは作れなくても気づきが得られることも
・学び
教師データがない場合、クラスタリングで異常値を発見
時系列データをサイクル単位に束ねる
●音声やテキストデータの例
・やりたいこと
音声やテキストデータを活用したい
・どうやる?
まずはテキストデータに
cognitive serviceなど
形態素解析
キーワード抽出
出現有無、出現率など
辞書分類
ブランド評価辞書
信頼、安定感、一流、
革新的、かっこいい、個性的
研究結果は公開せれていることが多い
・Azure Text Analytics
センチメント分析に日本語も対応
・人事採用分析のビジネス課題例
内定辞退者が多い
辞退者の特徴、辞退リスク率を把握、フォロー

・学び
キーワードの頻度から傾向が見えたり
決定木で応募者をプロファイリング

●まとめ
・機械学習ツールが高機能化しているから特徴量で差がつく
・特徴量の作成に鉄板ルールはない
・ビジネス課題を解決するためにどう機械学習を活用するか?
■Azure Kinect DK 徹底解説 ~ 進化したテクノロジーとその実装 ~
千葉 慎二 さん (日本マイクロソフト株式会社)

●Azure Kinect DK
・赤外線で物体との距離を計測
・2Dイメージの取得
・3Dの空間を把握
※まだ日本発売の話は出ていません
●人の全身の動きを捉える
・何をしようとしているのか推測
・その人の求めるなにかを実現
・人とコンピュータの対話
●開発環境
・Sensor SDK
・BodyTracking SDK
・Speech SDK
●Sensor SDK
・カラーカメラへのアクセス、モード制御
4Kでいけます
・深度カメラへのアクセス、モード制御
NFoV
視野角を絞って、遠くまで
WFoV
広い視野角で、近く
パッシブIRモード
近赤外線で
※カラー付きの撮影が必要かどうかでモードを判断
・IMU
加速度、角速度の取得
・カメラストリーム
内部的に同期
あえてずらすことも
外部デバイス同期制御
・カメラフレームメタデータ、キャリブレーションなども
・システム要件
Windows10 / Ubuntu 18.04
USB接続機器
※単体では動作しません
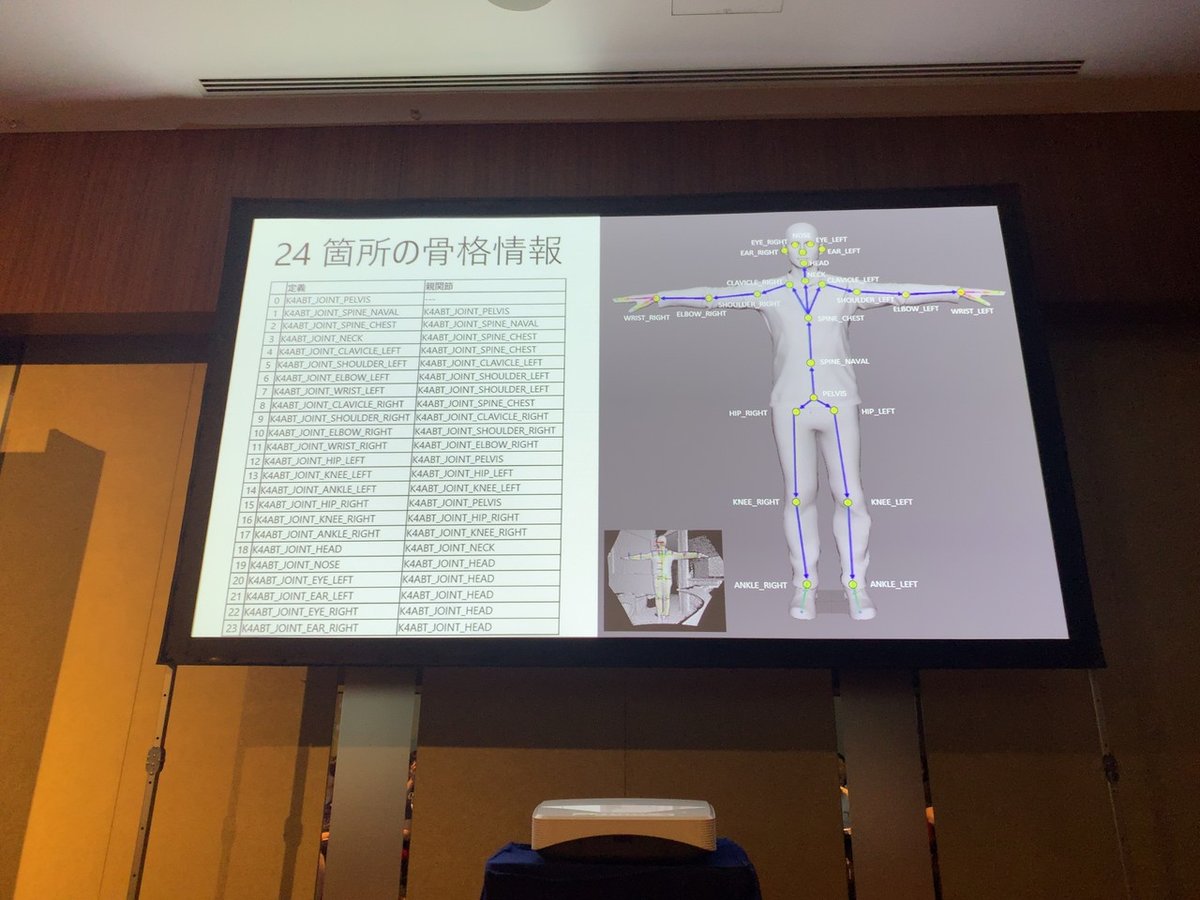
●Body Tracking SDK
・セグメンテーション
それぞれの身体を特定
・リアルタイムに身体動作を追跡
24箇所の骨格情報
※見えていない部位も予測できる
・システム要件
Windows 10
NVIDIA GPU
●Speech SDK, Cognitive Service: Azure連携
・スピーチ -> テキスト
・スピーチ翻訳
・テキスト -> スピーチ
スピーカーは付いていないので、PCで発話
・コンピュータビジョン
・フェイス など
※裏でサービスを動かしておく必要がなくなった
--- ソフトウェアの実装 ---
●処理フロー
・Kinect DKの初期化
・カメラ構成して始動
・ループ
・フレームキャプチャ
・フレームアクセス
・イメージやキャプチャの開放
●インターフェイス相関
device -> capture -> image
↑
-> calibration -> transformation
●キャプチャとイメージ
・映像
カラー
深度: 魚眼的になる
IR : 深度がグレースケールになったイメージ
・ロジック
caputure -> image -> image開放 -> capture開放
・フォーマット
フレームレートを抑えることで電力、熱を抑えられる
防犯カメラなど
赤外線の反射で奥行きを判断している
MJPG: 一枚一枚はJPG 95%
・座標空間と座標変換
キャリブレーション関数
解像度分だけ変換が必要
変換関数
イメージ全体を変換
GPUで処理できる
●IMU
・データ構造と座標系
温度(摂氏)
加速度データ
加速度タイムスタンプ
角速度データ
角速度タイムスタンプ
・フレームの記録と再生
マトリョーシカフォーマット
・インターフェイス相関
device -> capture -> image
↑
-> calibration -> transformation
↓
playback <- record
・深度カメラとプロジェクションの注意
光が強すぎると深度情報が飛ぶ
部屋の隅だと反射が影響して、深度情報が飛ぶ
複数動悸させると干渉が起きることも
デイジーチェインで解消
各デバイスでキャリブレーションが必要
●Body Tracking
・ボディトラッキングは深度センサーから取得している
・センサーからの情報をキューイングしてある
●Tips
・初期化し忘れ
自作できるからnullが入ってくる
・ハンドルの開放順序と、適切なエラーハンドリング
順序を間違えるとクラッシュ
・ハンドルの開放し忘れ
じわじわメモリリーク
・タイムアウト
実データがきれて取れてしまうことも
・変換パラメータ
座標空間の解像度、フォーマットを合わせる
・解像度や映像フォーマットの制限
規格外を指定すると動作しない
●chmで日本語ドキュメント用意しました
■感想
・エンプラでのNoOps実践ノウハウ
・モノリスからMSA/k8sへの移行ノウハウ
・Azureサービスを組み合わせたリアルタイムwebの例
・機械学習前のデータ準備ノウハウ
今日は実経験のお話から、たくさんの「そうですよね〜」と「なるほど!」をいただけました!
登壇者の皆さん、運営の皆さん ありがとうございました!
この記事が参加している募集
いつも応援していただいている皆さん支えられています。