
2019-05-15 Rancher Meetup Deep Dive #01 #rancherjp

2019/05/15 に開催された Rancher Meetup Deep Dive #01 のイベントレポートです。
●イベント概要
過去のRancher Meetupでは、初心者の方々に向けたGenericなコンテンツを中心にお届けしてきました。Rancherのユーザーも増え「もう少しレベルの高いセッションを聞きたい、ディスカッションをしたい」という声も聞かれるようになりました。そこで今回「Rancher Meetup Deep Dive」を企画してRancherの本番ユーザーと、本番利用を想定している方のための勉強会を開催する運びとなりました。

■オープニング
@shindoy さん

●Rancherコミュニティ
・GWは全国行脚
200人参加
・togetterでまとまってます
・connpass
1500人越えました!
・slack
676人!
■Rancherをはじめとした、Private Cloud運用で気をつけていること
西脇 雄基 さん @ukinau [LINE]

●LINEのPrivate Cloud Platform
・rancher / knative / baremetal
・openstack

●難しさ
・複数のレイヤにまたがる
・複雑なプロセス、ノード
・多数の依存OSS
●心がけ
・ドキュメントやバグレポートを鵜呑みにしない
・内部ステートを理解しよう
・問題が根本原因から発生しているとは限らない
・複数のソフトウェアが関連している
・説明できるまで調査をやめてはならない
●ドキュメントだけでなくコードを読む
・issueのリンクではなく、コードを引用して議論
・rancherも仕組みを調査
Let's unbox Rancher 2.0
●内部のステートを掴む
・DHCPなら
どれだけリクエストが来ているか
NACKはどれだけ来ている?
-> limitationに来ているならスケールアウトなど
・Rancherなら
<rancher-host>/metrics
LINEでは拡張して、内部のステートを出している
-> grafanaで可視化
websocket sessionを見ると状況がわかる
実行間隔や時間も可視化
・複雑性のあるソフトウェアを使うときは
内部のステートを掴むようにしている
rancherはよくできている
k8sを誰でも構築できるようになった
が、全て楽になったわけではない
●例: cluster agent と serverのwebsocket sessionが切れた
・agentのログを見る
名前解決に失敗している
kube-dnsを指している
・他のノードからkube-dnsが問題なのかを試す
問題なかった
特定のノードでNG
・overlayの通信が来ているか?
container networkはk8sは関与しない
・flannel
linux kernelに指示を出している
ip, bridgeコマンドで確認
-> できている
iptablesが適切でない
-> flannelのコードを読む
起動時にmetadataをk8sに登録
-> 通信できないnodeだけannotationがない
・rancher serverのバグを見つけた
あるべき姿のannotationを取得
別のfunctionでannotationを取ってくる
楽観ロックで更新
-> この2functionの間の更新が消失
・きっちり説明したissue & patch提供で貢献
●調査した流れ
・rancher server
・rancher agent
・kube-dns
・kubernetes
・flannel
・rancher server
●ネットで調べると
「kube-dnsをdamemon setで動かせ」がたくさん出てくる
通信しなくなるからfixしたように見える。
あとで再現する
-> 説明できるまで調査しよう!
■開発プロセスとRancher
藤原 涼馬 さん @RyomaFujiwara [Rancher JP & Tea pod418]

V次モデルに従って説明
●要求分析・要件定義
・基本的に役立つ部分はないハズ
・ドキュメント仕事なので
管理共有するための仕組みが重要
・他人との認識合わせ
-> 共有してこそ価値がある
・アンチパターン
共有されてない
個人が持っている
・対策
共有しやすい仕組みを作ること
webベースにしよう!
意識しなくても共有される
検索できるように
適材適所で使い分ける
・基本は github/gitlab pages
・表計算、プレゼン系だけonlineのexcelで
●基本設計
・k8sなら、システムの構成をリソースで記述すると見通しが良い
・public cloudなら、ここにプロダクトのアイコンが入る
・用語整備の手間が省ける
わからなくても、リンクを渡せば済む
職場のジャーゴンでガラパゴス化を避けられる
・rancherカタログ化して管理
管理単位をカタログアプリケーション単位で分離
組織の構成に合わせて
・yamlファイルの構成に意味合いが決まっている
・アプリケーション全体をrancherで管理
アプリに紐づくk8sリソースをGUIで管理
カタログ = システムの構成管理
●詳細設計
・rancherの出番はない
・泣きながらdockerfileとk8sリソースの詳細を詰める
・用語が外部で整理されているから認識齟齬は起きにくい
●(yamlの)コーディング
・GUIがテンプレートエンジン的に使える
・GUIでつくると、細かい設定も当ててくれる
upgrade strategyとか
教育目的にも
●UT・IT
・rancher pipeline
まだ癖があって、テストが難しい印象
・UT
Dockerfileの中で
・IT
前提のリソースをデプロイしてから動かす
・CIやりましょう
人は忘却する生き物
ちょっと別の作業をしたら、何が原因か思い出せない
テストがあれば、気付きになる
欠陥混入から時間が経つほどコストが指数関数的に上がる
●システム・受け入れテスト
・修正結果を環境に反映する手間をどれだけ減らせるか
・デプロイは人の判断がなくて良い部分。どれだけ楽にできるか
GitLab Pipeline で CI
Rancher Pipeline で CD
●運用
・prometeusでモニタリングとアラーティング
・ログを見るなら他と組み合わせて
●ポイント
・Rancherでカバーできない部分をどうするか?
既存組織の技術資産などで柔軟に判断

■オンプレK8s&Rancherで作る機械学習基盤
岡野 兼也 さん @Juju_62q [サイバーエージェント]

●自己紹介
・リソースプールとしてrancher、k8sを使っていった
・OpenSaaS STUDIO
・発表内容は 株式会社キスモ でやったこと
●機械学習の成果がユーザに届くまで
・Data Collect
・Compute
・Delivery
システムに組み込んでユーザに届ける
●データサイエンティストがやりたいところ
・どんなデータを集めるか
・どんな手法で、目的の制度を出すか
・データエンジニアは幅広く触るが
データサイエンティストは専門職
圧倒的な知識があればやっていける
●それ以外は誰がやるの?
・MLOps
機械学習を効率的に利用できるようにする
まだ、会社の数だけ実態がある
-> データサイエンスで生まれる価値をシームレスにユーザに届ける
・Data Collect
fluentd, bigquery
・Compute
kubernetes
sagemaker / kubeflow
・Delivery
rekcurd
sagemaker / kubeflow
-> 今日はcomputeの部分の話
●なぜ機械学習をオンプレで?
・マネージドサービスなど、クラウドのメリットはたくさん
・機械学習するときだけ高価なインスタンス
・推論モデルのバージョン管理も簡単
など、相性も良い
↓
・機械学習リソースがずっと必要になることも
・類似の学習の経験があるなら早く高い精度のモデルを作れる
・スポットではなく、ずっとリソース必要
●キスモでの機械学習の状況
・kaggleは業務の一環として扱った
・学習中はリソースが張り付きっぱなしだった
-> クラウドのメリットなくない?
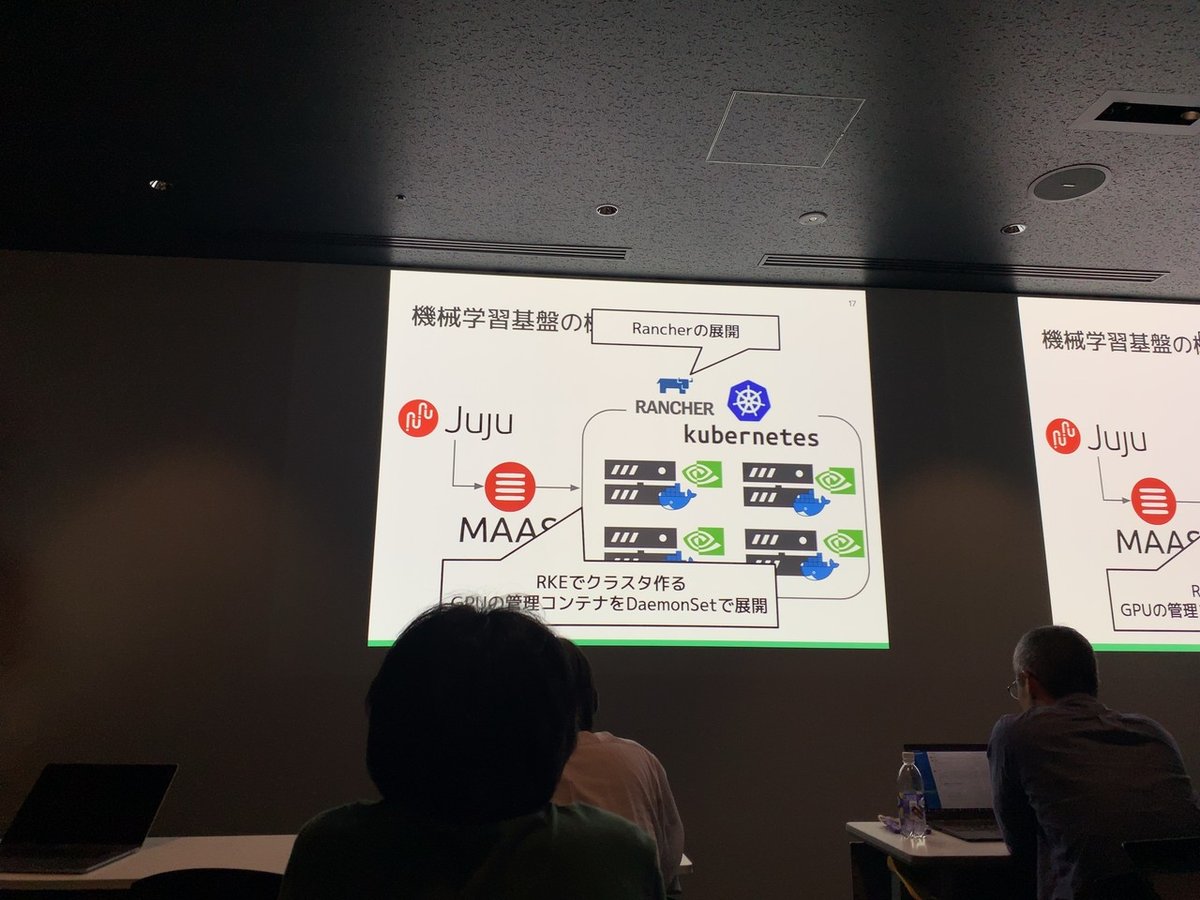
●機械学習基盤を導入して
・嬉しいこと
空きリソースのやりくりを意識することが減った
コンテナ化で変化に強くなった
学習単位が1マシンに縛られなくなった
・嬉しくないこと
データサイエンティストがk8sやらないと
データの扱いめんどくさい
-> データサイエンスだけ との落差
-> GUIで! = rancher
●なぜRancher?
・コマンドだと、やったことがどう効いたのかがわかりにくい
-> GUIで敷居は下がった
・でもやりづらいことも
-> kubectlをラップして見やすくした
GPUの利用指定など
■Rancher&Kubernetesで構築した映像解析クラスタ
林 幹久 さん [フューチャースタンダード]

●自己紹介
・数理技研でエンジニア
・アイルランドへ
・フューチャースタンダードへ
●SCORERの全体像
・どんな解析結果が出たかをユーザ提供
・カメラ
-> SCORER Edge
-> S3
-> インプット、解析、アウトプット

●AIは交換可能な部品
・アルゴリズムはcontainer
動画の取得、再生、AI本体などでcontainerが分離
・バッチジョブ形式でコンテナが連携する仕組みが必要
●構成
・rancher 1.6
柔軟性、CPU/GPUの切り替えが難しかった
・移行期間 4ヶ月で 2.xへ
・複雑
CPU/GPUが混在
開発、本番環境が混在
●これから
・GUIでGPUをポチポチ増やす
・クラウドではGPUは高い。本命はオンプレ
・マルチクラウド/オンプレ混在構成へ

■Rancher 2.2.2 アップデート情報
@Cheng さん

●Rancher 2.2.2
・4/17 リリース
・CVE-2019-11202対応
管理者が初期作成した、デフォルトのadminユーザを削除
rancher server再起動で、復活
回避方法1
bugfixバージョンを入れましょう
回避方法2
ユーザ削除ではなく、無効化する
・画面からクラスター証明書が更新できるようになった
rancherで初期生成したクラスター証明書は期限1年だった
画面で更新できるようになった
デフォルトで期限10年に変わる
clusterメニューのrotate certificatesで一括生成
〜2.1は、APIで対応
・k8s 1.14.1 サポート (実験版)
・安全性のため、一旦プロジェクトレベルのモニタリングをOFF
クラスターレベルは継続して利用できる
・API, UIのパフォーマンス工場
・issue対応はたくさん
●Rancher 2.2.3
・5/14 リリース
・クラスタモニタリングONの特定条件下で
ConfigMapsが繰り返しデプロイ -> APIが反応しなくなる
●Rancher 2.3
・9月リリース予定
・windows GA Support
workerとして、一緒にクラスタ管理できる
・cluster templates
同じ設定のクラスタを量産できる
■感想
・Rancherの内部構造へのDeepDive
・Rancherを利用するプロセスへのDeepDive
・Rancherを利用するドメインへのDeepDive
・RancherJPへのDeepDive
オンプレ、マルチクラウドでのk8s運用にはRancherが強いのを再認識できました。構造を理解して、組織のプロセスにマッチするように活用していきたいですね。
深いお話に「なるほど!」をたくさんいただけました!登壇者の皆さん、運営の皆さん ありがとうございました!!
いいなと思ったら応援しよう!
