
中国語と日本語の漢字にまつわる、許せない話

本日は怒りをぶつける回です。
ただ、これまでにまだあまり指摘されていないうえ、テキスト上で伝えることがものすごく難しいタイプの混みいった怒りなので、うまく伝わるかどうか危惧しています。どうかみなさんついて来てください。
+++++
中国語(ここでは簡体中国語とします)と日本語で使われる漢字には、よく似ているけど微妙に字の形が違うものが多数存在しています。
たとえば、日本語の「歩」(ある(く))と中国語の「步」(bù)です。

赤丸で示した通り、右側に小さな点があるかないか、という違いがあります。こういう、よく見ないと気づかない違いがある例はけっこう多いです。
他にもたとえば「角」という字は、日本語の「かど」と中国語の「jiǎo」で、真ん中のタテ棒が下側に突き抜けるかどうかという違いがあります。

これら以外にも「単」と「单」(上の点が3つor2つ)や、「決」と「决」(さんずいorにすい)など、例として挙げられるものはいくつもあります。
こういう違いを覚えなければいけないので、日本の中国語学習者は大変だし、逆もまた然りなんですね。
+++++
……ということは、これまでにもさんざんいろんな人が紹介していますし、目新しい視点ではありません。
現に、「中国語と日本語で似ている漢字」などと検索すれば、こうした例を紹介しているページがたくさん見つかります。
僕が怒っているのは、この「中国語と日本語で似ている漢字がある」ということを前提にした、さらに細かい部分です。
+++++
というのも、これらの漢字をコンピュータ上で入力したときに、これらの細かい差異が反映されず、ガン無視されてしまう場合があるのですね。
どういうことか、具体的に見ていきましょう。
たとえばX(Twitter)の投稿画面で、先ほど挙げた例の「歩」(ある(く))と「步」(bù)の違いはちゃんと反映されて、区別がつくようになっています。

少し小さいですが、ちゃんと右側の点の有無という差が表現されていますよね。
ところが、同じく上で挙げた「角」という字に関しては、どうやってもこの区別が表現できないんです。具体的には、中国語で「jiǎo」を入力した瞬間、勝手に日本語の漢字に置き換えられてしまうんですね。
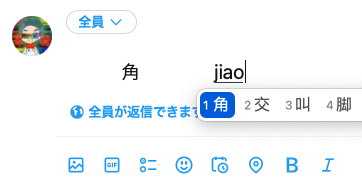
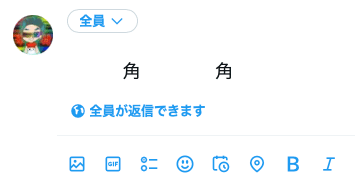
どうして日本語と中国語で字形に差があるはずなのに、場合によって表現できたり、できなかったりするんでしょうか。
こうなってしまう理由は、文字コードにあります。現在、僕たちがコンピュータ上で扱う文字には文字コードという識別番号のようなものが割り振られています。いまもっとも広く使われいてるのは、Unicodeという規格のものです。
このUnicode、漢字まわりに関する取り決めがかなりガバガバで、先ほど挙げたような日中で形が異なる文字にきちんと別々のコードが割り振られている場合もあれば、同じ文字としてひとまとめにされてしまっている場合もあるようなのです。
ひとまとめにされている文字に関しては、それぞれに別のフォントセットを設定してやらない限り、その違いが表現できません。
たとえば先ほど示した「角」の画像は、左右の文字にそれぞれ違うフォントを適用しているので、その違いを表現することができました。

しかし、X(Twitter)への投稿などの場面では、自由にフォントを変更することができないため、これらの違いをどうやっても反映することができません。
これによってどういう不便があるかと言うと、まずコンピュータ上でこれらの文字の違いを説明するのがとんでもなく難しくなります。
この記事ひとつとってもそうです。noteもフォントを自由に変えられない環境のため、本文に直接これらの文字の違いを入力して表現できません。そのためここまで読んでもらった通り、説明が回りくどくなるし、いちいち画像を駆使しなければならなくなります。これを書きながらも、死ぬほどイライラしています。
また、これは言語学習にもおいても障害をもたらします。たとえば「直」という字は中国語(簡体字)と日本語でかなり形が違うのですが、あろうことかこれらの文字のコードは同じに設定されています。
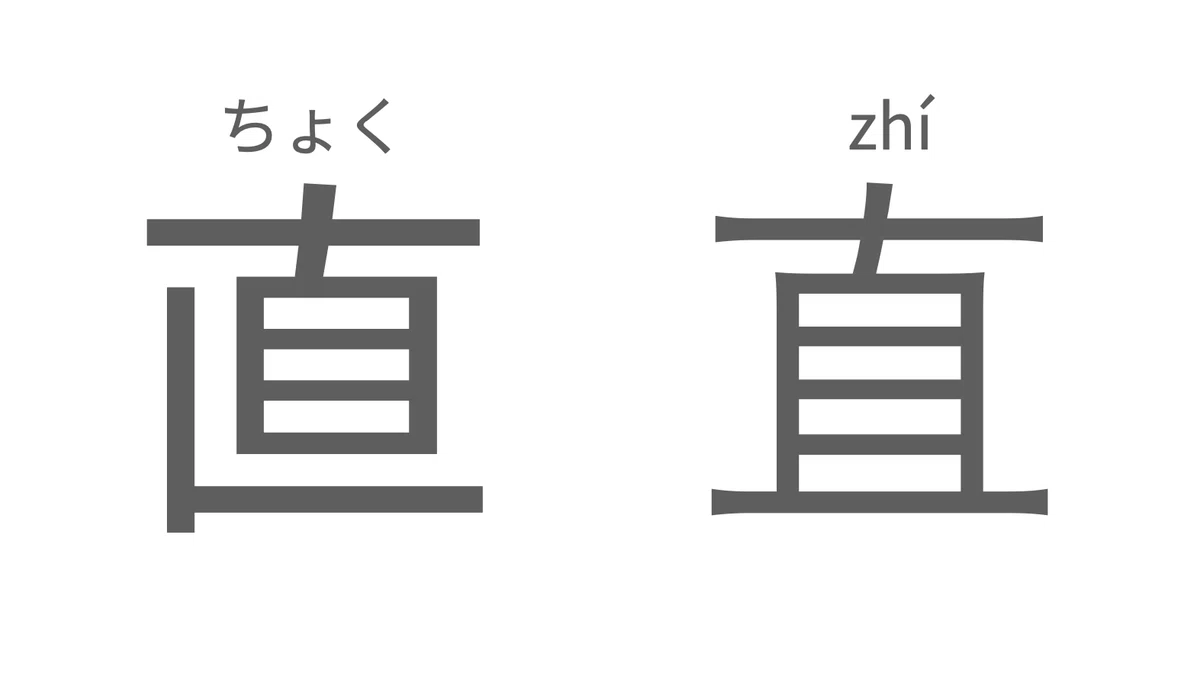
これによって何が起きるかというと、たとえば僕が日本語の環境から中国人にメッセージを送ると、相手方には勝手に文字が置き換えられて伝わってしまうのです。


これを見た中国人は、「日本人が使っているんだから、この字は日本語と中国語で同じように書けばいいのだな」と誤解してしまう可能性があります。
そもそもなんでこんなにも違うものが、同じ文字としてUnicodeに収録されてしまっているのでしょうか。こんなメチャクチャなことがまかり通っているのに、憤りを禁じ得ません。
+++++
僕は前々から日本語と中国語のフォントや字体の乱れの問題にイライラすることが多く、こうして解説したり、問題意識を投げかけるnoteもいくつか書いているのですが、この憤りに共感してもらえたことがほとんどありません。個人的にはめちゃくちゃ大きな問題だと思っているのですが。孤独です。
今回、この記事は無料で公開していますので、ぜひシェアをお願いします。この問題にもっと広く関心を持ってもらいたいです。
もっとみんなで怒りましょう。そして世の中を変えていきましょう。よろしくお願いします。
ここから先は

いただいたサポートは貴重な日本円収入として、日本経済に還元する所存です。