
AIイラストが理解る!StableDiffusion超入門【2025年最新版】

こんにちは、2022年10月からAIイラストの技術解説記事を140本以上web連載しています、「スタジオ真榊」の賢木イオです。この記事は、画像生成をめぐる2025年の最新環境と入門法が最短距離で学べるメインコンテンツ。おおむね半年ごとに内容をアップデートしており、今回も最後まで無料で読める全体公開noteとしています。
これから画像生成を始める方や、手描きイラストにAI技術を取り入れてみたい方、AIは好きになれないけど最新環境を把握しておきたい方が最初に読む記事として、自分のPC内で画像生成できる「StableDiffusion(ステーブル・ディフュージョン)」の使い方を中心に、基礎知識を網羅的かつやさしく解説しています。
イラストを思い通りに生成するために覚えるべきことをはじめ、PC選びやつまずきやすいポイント、トラブルを避けるために最低限必要な知識なども紹介していますので、最初にこの記事から読んでいただくとスムーズに理解できるはずです。
解説役は今回も、更木(ざらき)ミナちゃんです。よろしくお願いします!

画像生成はどこまで進歩した?
AIイラストが日本のSNSで盛んに投稿されるようになったのは2022年10月ごろ。当初は「ラーメンが食べられない」などと面白がられていたAIイラストですが、あれから2年以上の時が経過し、当時とは性能が一変しています。
まずは「現在のAIの実力はだいたいこれくらい」という空気感が伝わるように、現在の画像生成AIにできることを盛らずにまとめます。
①画像の正確性は日々向上中
6本指の画像は相変わらずたまに出ますが、2年前に比べると各段に正確な画像を生成できるようになっています。黎明期は麺を手づかみで食べることが多かったラーメンも、だいたいお箸で食べられるようになりました。

よく見るとお箸やテーブル、肘のラインなどが不自然ですね。こうしたミスがないかチェックしたり、修正したりしていない生成物を「ポン出し」と呼びますが、こうしたミスを簡単にAIで直すこともできるようになりました。
②ラフの線画化(AIペン入れ)は簡単・高機能に
ラフにできるだけ忠実にペン入れしてもらったり、逆に「AI度」を上げてきれいに線画化してもらったりすることがどんどんできるようになっています。AI作画補助サービス「copainter」が簡単かつ高機能で有名。StableDiffusionを使った線画化は難易度がやや高いですが、より自分寄りの画風にカスタマイズすることが可能です。
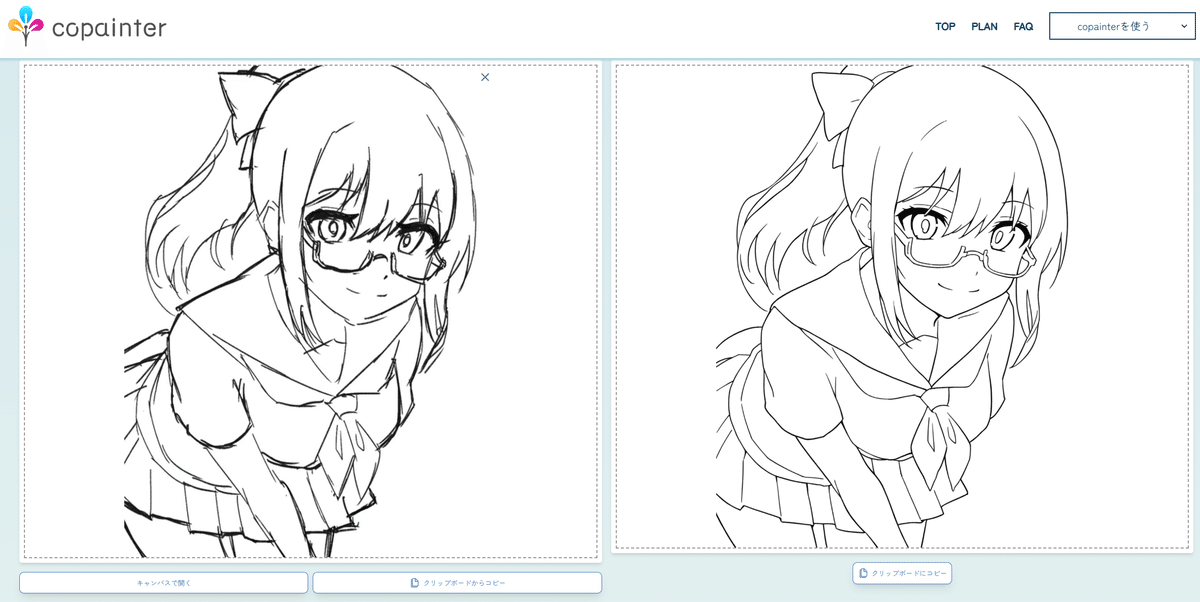
線の入り抜き、線の太さを調整でき、透過背景で出力することもできる。
③1枚絵から画風を覚えてもらえる
1枚のイラストから自分の画風をAIに学習してもらうことができます。
左のイラストから画風を追加学習して、瞳のかたちや髪のハイライト、塗りのフラットさなどをAIが再現したのが右の4枚。人気のAIモデルを使うとどれも似たような顔になり、陳腐化してしまう「マスピ顔(masterpiece顔)」現象が、これで比較的簡単に避けられるようになりました。

塗りのフラットさなどがよく似せられている。(CoppyLoRA webUI v2使用)
④線画のカラー化
線画をAIに着色してもらうのはかなり安定してできるようになりました。これは左の線画をランダムにアニメ塗りで着色してもらったものですが、もちろん瞳や髪、肌の色をプロンプトで指示することもできます。塗りも自分のタッチに寄せることが可能。

⑤落書きで構図を指定
線画化や着色の過程をすっ飛ばして、ラフから一発でAI絵にしてもらうこともできます。AIにラフを仕上げてもらうと言うよりは、「落書きでAIに構図指示をしている」ような感覚です。

AIに「何をどこに描くべきか」だけを指示できる
⑥「存在しない続き」の生成(アウトペイント)
キャンバス外に「続き」を描いてもらう、いわゆる「アウトペイント」がより高精細に。これは顔のアップをもとに「黒いTシャツを着たショートヘアの女の子のバストアップ」を指示した例。

⑦描き直し(インペイント)がかなり自在に
画像の一部を塗りつぶして、そこだけ自然に描き直してもらう「インペイント」の精度も格段にあがりました。ポーズを変えたり、背景だけ変えたり、表情だけ変えたり、6本指を5本指に修正したりといった作業が簡単に行えるようになりました。

完璧に生成する必要がなくなったので「ミスに気づけるかどうか」のほうが大切
画像生成AIの仕組みをざっくり解説
さて、こうした画像生成は一体どんな仕組みで可能になっているのか、難しいことは一切抜きの「イメージ」で解説していきます。最低限覚えるべきなのは、次の三つのキーワード。
・「データセット」…画像生成AIが学習するために使う画像とテキストの組み合わせ(教師データ)の集まりのこと。
・「学習済みモデル」…データセットを基に、既に学習を終えたAIのこと。画像生成では"checkpoint"や単に"モデル"と呼ばれることが多いです。
・「プロンプト」…AIに生成させたい内容を指示するためのテキスト入力のこと。「1girl,smile,looking at viewer…」といった、タグをカンマで区切って並べる呪文のような指示が一般的。
この記事で紹介する「StableDiffusion(以下"SD")」も、学習済みモデルの一つです。text-to-image(=文章から画像)と言って、無数の画像とテキストのペアでできている「データセット」から学習することで、「プロンプト指示」に応じた新しい画像を出力することができます。AIは画像を無から生成するのではなく、人間が入力したテキストを画像に「変換」できるシステムだと考えると近いかもしれません。

どうしてこんなことができるのかというと、学習済みモデルは「ノイズを加えてぼんやりした画像から、ノイズを除去してきれいにするための訓練」を積んでいるからです。
例えば「これはリンゴ(apple)だよ」と言われてぼんやりした赤い画像を見せられたら、ノイズを除去してきれいなリンゴの画像を出力できるような訓練をイメージしてください。こうした訓練を無数のリンゴの絵や写真でひたすら繰り返していくうち、AIは全く無意味なノイズ(砂嵐画像)からでも、「これはリンゴだよ」と言われると、「赤くて丸い果物」を推測できるようになるわけです。

画像生成はコラージュなのか?
よくある誤解として、「AIはイラストを切り貼りしてコラージュしている」というものがありますが、教師データであるイラストそのものはAIの中には記憶されていません。もし何億枚、何十億枚という教師データを全て記憶していたなら、数GB程度で済むはずがありませんよね。さっきの例なら、AIは学習したミナちゃんの画像を勝手に切り貼りするのではなく、テキストとのペアから学んだ「特徴・傾向」に従って、データセットに存在しないさまざまなミナちゃんの絵を生成できるのです。
ただ、「1girl(女の子)」という概念を学ぶときに、片手を上げた初音ミクの画像1枚でしか学んでいないモデルがあったとしたらどうでしょうか。

「女の子を描いて」と指示すると、そのモデルは常に片手を上げた青いツインテールの女の子を描いてしまいますよね。様々な髪型、体型、表情、服装、ポーズ、キャラクター名、カラーリング…の無数の「1girl」と的確なテキストをペアで学んでいないと、注文を正しく変換できるAIにはなりません。
AIは「学習内容を基に、指示に応じた"もっともらしい回答"を素早く算出する仕組み」です。つまり、AIは膨大な学習の末に、テキストの意味を理解しているかのように振る舞えているだけなのです。教師データが偏るともっともらしさが損なわれて馬脚を表しますし、「教師データそのものを出してはならない」という感覚もないため、学習や生成の仕方によっては教師データそっくりなものが意図せず生成されることがあります。
女の子のイラストを生成するつもりが、誰かが描いたイラストにそっくりな画像が出てきたら困りますね。よほど意図して学習内容と指示内容を偏らせないとそんなことは起きませんが、「ユーザーが生成したものをよく見て、公開してよいものか判断することが非常に重要」ということは最初に強調しておきたいと思います。
実際の生成の様子
実際の生成はどんなふうに進むのか見てみましょう。画像生成は「ステップ」と呼ばれる段階を踏んで行われます。無意味なノイズから「存在しない元画像」を推測する過程を1ステップ、2ステップと繰り返すことで、より鮮明・高画質なイラストができあがっていくわけです。
「青空の下、トマトを持った女の子と犬が草原にいる絵を出して!」と頼んでみましょう。

AIくんは最初、まったく無意味なノイズ画像を渡されて「これはトマトを持った女の子と青空の画像だよ、ノイズを取り除いてごらん」と言われます。健気なAIくんはこれまで教師データから学んだ傾向に従って、なんとなくそれらしい感じにノイズを取り除き、ピクセルの並びができていきます。
その画像が再度AIに渡されて、ノイズを同じように取り除くと、だんだん空や人間、犬らしきものが鮮明になっていきます。何度もこの工程(ステップ)が繰り返される中で、犬と女の子、トマトの配置が決まっていきます。
ノイズが除去され終わると、それ以上ステップを進めてもあまり変化がみられなくなります。

特に低ステップ段階では、女の子や犬のすがたがどんどん変貌していることが分かると思います。リュックの茶色が後ろ髪に変貌したり、白い犬としてできてきたものが白いシャツになったりしていますね。
このように、画像生成AIは「トマトを持つ女の子」や「犬」、「草原」といったイラストを教師データの中から検索して、それを基に「切り貼り」しているわけではなく、ノイズ除去が繰り返されるたびに連想ゲームのように指示通りの画像に近づけているのです。
ただし、AIは「読み込ませた画像のコラージュ」に近い行為をすることもできます。それは「text2image」ではなく「image2image」と呼ばれる別の仕組み。それについては後で詳しく見ていきましょう。
どこで、どうやって生成するのか
さて、AIイラストを楽しむ方法は、大きく分けて次の2つがあります。
①自分のパソコンにツールをインストールして使う(StableDiffusion系)
②ウェブ経由でAI画像生成サービスを使う(NovelAI、midjourneyなど)
この記事で主に紹介するのは、①の「ローカル生成」です。自宅PCで好みのイラストを無料・無限に生成できる代わりに、GPU性能をはじめとしたある程度のマシンスペックが要求されるため、万単位~十万単位の初期投資が必要になります。(※高性能GPUをクラウド経由でレンタルすることは可能)
なお、ローカル生成には既存キャラクターやNSFWコンテンツ(Not Safe for Work、職場で見られない=成人向けコンテンツ)の画像生成にも制限がありません。
一方、②の「ウェブサービス系」はサブスク式の利用料金が掛かることが多いですが、自分の端末上で生成が行われないため、ネット環境さえあればスマホからでも気軽に楽しめるのがメリットです。サービスによっては、既存キャラやNSFW画像を生成できない仕組みになっているところもあり、ローカル生成に比べてある程度の制限があります。
NovelAIとかNiji journeyって?
本題の①について説明する前に、ざっと「②」の画像生成サービスにどんなものがあるかについても触れておきましょう。まず覚えておきたいのはDALL-E3、NovelAI、Midjourney(Niji journey)、Grokの4つです。
<DALL-E3>
まず、23年9月にOpenAI社が発表した画像生成AI「DALL-E3」。ChatGPTに日本語で指示することで枚数制限なく生成が可能で、実写調もイラスト調もこなせます。Microsoftの「Image creator」経由なら誰でも無料で生成できるため、画像生成入門にはもってこいと言えます。
<NovelAI>
アニメ調イラストで強いのは「NovelAI」。版権キャラクターやNSFW(成人向け)画像の生成に制限がなく、生成精度も高い人気サービスです。特に、画像の一部を塗りつぶして手直しする「インペイント」機能が優れており、SDで生成したイラストをNovelAIに修正してもらうやり方が非常に便利です。
既に最新の「v4」の機能限定版が先行公開されており、2025年初頭にfullバージョンがリリースされる予定です。特徴が混じりがちな複数キャラクターの描き分けが正確にできることが最大の目玉となっています。
<Midjourney / Niji journey>
画像生成の先駆者的存在「Midjourney(Niji Journey)」も根強い人気を誇っています。Midjourneyは実写調や絵画風、Niji Journeyは日本のアニメイラスト風の生成が得意で、最低月10ドル(年払いだと月8ドル)から利用可能。契約すると両方で生成が可能になります。「1枚絵」としての説得力が高く、アーティスティックでエモいイラストを出せるのが特徴。画風をカスタムできる「パーソナライズ」機能など、拡張機能も充実しています。
<Grok>
Grokは、X(旧ツイッター)で使える対話型AIチャットボット。DALL-E3を使えるChatGPTと同様に、Grokにも画像生成をさせることができます。画像生成にはStableDiffusionの元開発者が作った「FLUX.1」という最新モデルが使われていて、シンプルな日本語指示で高品質な画像生成が可能。当初はXの有料ユーザーのみが利用できましたが、2024年12月から誰でも無料で利用できるようになっています。

StableDiffusionこれらの画像生成サービスは、どれか一つだけを使ってももちろん良いですが、それぞれの強みを理解して組み合わせることで、より自分の意図したイラストを生成できるようになります。サービスによって商用利用の可・不可などが異なるため、よく規約を読んで利用しましょう。

SD生成に必要な「WebUI」とは
さて、話をSDに戻しましょう。この記事では①のローカル生成について紹介するわけですが、StableDiffusionという学習済みモデルをローカル環境(自分のパソコン)で使うための代表的ツールが「StableDiffusionWebUI」です。AUTOMATIC1111氏が配布しているため、「A1111版SDwebUI」とか「A1111」などと略されることが多いです。

2025年現在、ローカル生成に使われるwebUIは多様化が進んでおり、A1111のほかに「Forge」「reForge」「easyForge」「ComfyUI」、「Fooocus」「InvokeAI」「SD.Next」など、さまざまなWebUIが群雄割拠しています。
ほぼA1111版と同じ見た目と使い勝手なのに生成速度が早い「Forge」や、そのフォーク(枝分かれ)版の「reForge」が比較的広く使われており、スタジオ真榊FANBOXでもこれらをメインに技術解説をしています。また、A1111版より複雑なワークフローを設定でき、動画生成も得意な「ComfyUI」も、上級者向けUIとして広く浸透しているようです。

生成するのが特徴(公式Githubより引用)
「StableDiffusion」やその派生モデルと各種webUIの関係は、ゲームソフトとハードの関係によく似ています。無数の種類があるモデルの中から好きなものを選び、ハードに差して遊ぶのです。どのハードでもたいていのソフトを遊ぶことができ、ソフトが同じなら基本的に同じ画像が生成できますが、ハードによって速度や入力画面や使い勝手が違う程度に理解していればOKです。途中でアップデートがされなくなり、放棄されるwebUIがあるところも、ゲームハードの興亡と似ていますね。
画像生成AIをまず触ってみたい人は・・・
AIイラストを全く触ったことがなく、グラフィックボードなどを買おうか迷っている方は、StableDiffusionに挑戦する前にまず「DALL-E3」や「Grok」で画像生成をしてみることをおすすめします。自分で生成するというよりは、Chatbotに日本語で指示し、うまくいくことを祈る程度のことしかできませんが、なんとなく画像生成(text to image)の雰囲気が理解できるでしょう。

「予備知識もグラボも不要で、簡単に高精細なイラストが作れるなら、もう全部DALL-Eでいいんじゃない?」となりそうですが、そうでもありません。
DALL-Eは簡単な日本語指示で高精細な画像を生成できますが、逆に言えば「基本的にAIお任せ」なので、この記事の冒頭で挙げたような応用はほとんどできません。画風もどこか「英語の教科書風」というか、日本のアニメスタイルとはまたちょっと違った感じのテイストで出てくることが多いです。

同じモデルでも、プロンプトで画風はガラリと変わる
有償サービスの中では、エモいアニメイラストを思い通りに生成したい方にはNiji journeyを、推しの色んな姿を眺めて楽しみたい方にはNovelAI(通称・NAI)をおすすめします。Nijiは構図力が他を圧倒しており、「Nijiで構図案をたくさん出して、SDで自分画風に仕上げる」といった使い方もできます。
NAIは国内ではいったん廃れた時期もあったのですが、バージョン3(NAIdiffusionV3)の性能がすさまじく、2024年は一気に復権。インペイント機能だけでも課金する価値があり、最新の「V4」の公開によって、2025年も画像生成シーンの主役的存在になっていくと思われます。
ローカル生成はいっさいせず、NovelAIで推しの絵をひたすら生成しているユーザーも多いです。DALL-E3などと違って日本語での生成はできませんが、対応したプロンプトの候補を表示する機能もありますので、英語が苦手な方も大丈夫。「プロンプト超辞典」を参考にしながら生成してみるとよいでしょう。
StableDiffusionに必要なマシンスペック
さて、SDWebUIやForgeで画像生成するためには、NVIDIA製「GeForce RTX20」シリーズ以降のグラフィックボードが搭載されたPCが必要です。
・グラフィックボード 映像をパソコン画面に出力するためのパーツ、通称グラボ。画像処理に特化して計算を行う半導体チップ「GPU」を搭載している。GPUはCPUやマザーボードに標準で搭載されていることが多いので、グラボがなくてもゲームや動画再生はできるが、負荷の強い画像処理を行うには必須。マザーボードの規格やPCケースによって、デカすぎてささらないこともあるので買う前にお店の人に聞こう。
・VRAM GPUに搭載されるビデオメモリ(の容量)。画面に表示する内容を一時的に保存するためのパーツで、大きいほど映像遅延がなくなる。グラボによってVRAM容量は異なり、画像生成においては何GBかがとても重要。ローカル生成をするなら、できれば12GBほしい。
VRAMの容量は最低8GB、できれば12GB以上のものがないと、GPUに負担のかかる高画質な画像生成や複数同時生成が難しくなるとされています。基本的なイラスト生成だけを楽しむならVRAM8GBでも問題ありませんが、後述する「LoRA」などの追加学習を自前で行う場合は、最低12GB以上のグラボが欲しくなってきます。
画像生成ユーザーの間で「入門用のグラフィックボード」と言えば、スタジオ真榊でも使い倒したコスパ最強「RTX3060(VRAM12GB)」が思い浮かびます。RTX3060にはVRAM8GBモデルもあるのですが、もし購入するのであれば前述の理由で12GBモデル一択。高価なグラフィックボードほど1枚の画像生成に掛かる時間が短縮され、高解像度なイラストの複数同時生成も可能になりますが、GPUの性能が低いと、生成途中にVRAMが圧迫され、しばしば「CUDA out of memoryエラー」(GPUのメモリ不足)が発生してしまうからです。
こちらは2023年1月にRTX3060を購入したときと、23年12月にPCごと新しくしてRTX4080を導入したときの全体公開記事です。
既に古い記事ではありますが、それぞれCPUやメモリ、ストレージについても詳しく触れていますので、これからPCやグラボを購入して画像生成を始めたい方には参考になると思います。23年1月当時、RTX3060(VRAM12GB)は5万円以上しましたが、この記事を書いている24年12月現在は4万円前後で推移しており、依然としておすすめなグラボとなっています。
ただ、グラフィックボードの市場価格や流通モデルは刻々と変化しており、21年2月発売のRTX3060は今後市場から姿を消していく見込みです。一方、23年6月に3060の後継モデルとして発売されたRTX4060は、VRAMが8GBしかないので選択肢に入りにくい…。少し前なら「初心者なら3060一択!」と自信を持って言えたのですが、現在はやや判断が難しいところです。
画像生成AIとグラボについては、「ちもろぐ」さんのこちらの記事に大変詳しくまとまっており、あらゆるモデルの実力が網羅されているので、購入を検討されている方はぜひ参考にされてください。
グラボ以外のCPUやHDDは?
では、CPUやディスク容量についてはどうでしょうか。WebUIにおける画像生成は基本的にはGPU依存なので、よほど古いCPUを積んでいなければ大丈夫と言われています。ある程度生成速度には差が出るようですが、GPUほど明確な差は出ません。むしろ、画像生成や追加学習中にいろいろな作業をする場合は、メモリをできるだけ増設しておくことをおすすめします。
一方、HDD容量については、あればあっただけ良い!2TB欲しい!という感じです。学習モデルは一つあたり4~8GBほどありますし、ControlnetやLoRAなど拡張機能に必要なファイルもかなりストレージを圧迫します。さらに、外出中にも高解像度の画像をバカスカ無限生成していくとなると、最低でも100GBは開けておきたいところです。

中古のRTX4080が10万円、その他33万円で総額43万円だった
おすすめなのは、HDDでなくSSDを増設して画像生成関連専用のドライブにしてしまうこと。スタジオ真榊では23年7月にこちらの中華SSDを12,980円で購入し、新しくしたRTX4080搭載PCでも使っています。ファイル転送や読み込みは早いし容量はたっぷり余裕があるし、マザーボードに直接差すだけで簡単だし、大変買って良かったです。PCの買い換え時にもそのまま付け外しするだけでしたので、お値段以上に活躍してくれました。
【コラム】独断と偏見の「松竹梅コース」
「PC知識があまりなく、グラボを買うのも初めて」という方にローカル生成向けおすすめ構成を答えるなら、私なら次のように回答します(24年12月現在)。もちろん、人によって意見はさまざまでしょうから、あくまでご参考まで。
【松:VRAM16GB!GeForce RTX 4080 SUPER】
搭載PC価格例:389,800円(税込)
「PC分からんけど40万までなら出せる」人向け。RTX 4080 SUPERは実勢価格16万円~の最新・高性能モデル。もしこれでVRAM不足と思ったら、家庭用最高峰クラスのRTX4090(VRAM24GB)に踏み込むことになるが、RTX4090は在庫払底のためもはや軽々には手に入らない超高嶺の花となっている。(※いまはRTX 5090発売へ向けた助走のタイミング)

【竹:RTX3060(12GB)か4060Ti(16GB)…?】
「コスパ最高で間違いないやつがいい!」と言われたら、RTX3060(12GB)搭載の10~15万円程度のBTOパソコンをすすめておけばまず異論は出ないはず…だったのだが、さすがに発売から3年半が経ち、3060を搭載したBTOは購入できなくなった。3060単品ならまだ市場に流通しているため、それをPC SevenなどのPCショップに持ち込んでPCを組んでもらう方法もあるが、初心者にはちょっと敷居が高いかもしれない。
代替案としては、同じVRAM12GBのRTX4070シリーズが思い浮かぶが、4万円の3060と比べて最低でも2倍の価格。RTX4060Ti 16GBモデルの搭載PCを見ると、かつての3060搭載PCと同じくらいの価格帯のものがあるようなので、15~20万円クラスで探すならこのあたりで手を打ってはどうかなと思うところ。(個人の意見です)
【梅:NovelAI Opusプラン/月25ドル】10万円以上は出せないなら
AIイラスト向けデスクトップPCが欲しいが10万円も出せない場合は、いったん諦めてNovelAIで画像生成を始めたほうがいいと思います。NovelAIにはドル建てで10ドル、15ドル、25ドルの3プランがあり、主にそれぞれもらえる通貨「Anlas」の数が異なりますが、払うなら無限生成ができる25ドルの「Opus」プランがおすすめ。現在グラボなしのPCを使っている場合は、4万円でRTX3060単品を買って搭載してみるのが良いはず。ちゃんとPC内にささるかどうかは事前に確認を。

WebUI、結局どれがいい?
StableDiffusionを触るにあたって、どのWebUIでどんなモデルを使ったらよいかは、「プレステとSwitchどちらを買うべきか」と同じような問いです。つまり好みと用途によるわけですが、最初はやはり本家のA1111かForge系を選ぶ人が多いようです。
インストール・アップデート方法はいろいろな方法があります。「StabilityMatrix」というアプリケーションを使うと、A1111、Forge、ComfyUIなどの主要UIを一括でインストールでき、使用するモデルも共有できてとても便利。初めてSDに触れる方は、こちらの記事を参考に環境導入するのがお勧めです。
本家のA1111と分家のForgeは基本的に使い方はほぼ同じですが、Forgeの方が生成速度に軍配が上がります。ただ、現在のForgeはアップデートの方針をめぐっていろいろと好みが分かれるところで、枝分かれした「reForge」に乗り換える人も出てきています。詳しい経緯についてはこちらの記事で紹介していますが、スタジオ真榊では「StabilityMatrixを使ってreForgeで始める」のを初心者にオススメしています。
画像生成の基礎知識
さて、PC環境が整い、無事SDWebUIをインストールできたら、さっそく画像を生成していくことになります。こちらがSDWebUIの操作画面です。(写真はreForgeですが、A1111やforgeもほぼ同じ見た目です)

日本語化した上、拡張機能も多数導入していますので、インストールしたての画面とは異なることをご了承ください。ちなみに、画面のテーマカラーは「設定▶ユーザーインターフェース▶Gradio theme」で変更できます。目が疲れるので、おじさんになると白よりもダークテーマが楽です…。
初めてだと何がなんだかわからないと思いますので、こちらに画像の説明文を作りました。拡大してご覧ください。画像内の大きな数字①~⑥は、下記の項目ごとの数字に対応しています。

①学習モデル(Checkpoint)
SDwebUIはAIではなくただのインターフェース(ゲーム機本体のようなもの)ですので、それ単体では画像生成を行うことができません。大量の画像とテキストのペアから学習した「学習済みモデル」(通称Checkpoint)を読み込ませる必要があります。それがゲームソフトに当たるStableDiffusionなわけですが、実は多くのユーザーはStability AI社が配布しているStableDiffusionモデルそのものは使っておらず、そこから派生したさまざまな特徴を持つモデルを使って生成しています。
こちらは自作したモデルを共有できるプラットフォーム「Civitai」のスクリーンショットです。

実写のようなフォトリアルな画像に特化したものや、アニメ調のイラストが得意なモデル、緻密で美しい風景の再現が得意なモデルなど、主に学習させた教師データによりさまざまな特徴・種類があります。全く同じプロンプト指示でも、どんなモデル(Checkpoint)を使うかによって、生成されるイラストは大きく変わるわけですね。
こちらは、手元にあるモデルに同じプロンプトで生成させたミナちゃんのイラスト。系統樹が近いモデルは近いポーズが出るのが分かると思います。

モデルにもよりますが、指の数をミスする頻度はこれくらいのイメージ
学習モデルをゼロから作るのは個人では困難ですが、既存のモデル同士を好きな配合で融合させて好みのものを作り出すこともできるため(マージと言います)、無数のモデルがCivitaiなどに無償で投稿され、共有されています。学習モデルによって異なるライセンス表記があり、「マージモデルの公開禁止」「生成画像の商用利用禁止」などのルールが定められているので、必ずチェックした上で使用する癖をつけましょう。
ちなみに、基盤モデルであるStableDiffusionそのものにもさまざまなバリエーションがあります。初期型で広く普及した「SD1.5系」、あまり普及しなかった後継「SD2.X系」、アニメモデルの勃興で現状最も人気な「SDXL系」、高性能な新顔「SD3.X系」などがあります。

「Animagine」や「Pony」「illustrious」といったモデルの名前を聞いたことがある人もいるかもしれません。これらはすべて、SDXLをベースに作られたアニメ系人気モデルの名前です。それらをベースに、モデル同士を混ぜたり、追加学習させたりして、個人がさらにさまざまなオリジナルモデルを日々作っているわけですね。

②VAE
「Variational Autoencoder」の略。何をしているかを説明するにはまず、拡散モデルの画像生成AIには「テキストエンコーダ」「U-NET」「VAE」の三つのモジュールがあり、潜在空間上でノイズ除去が・・・などなどというややこしい説明が必要なのですが、この記事では割愛します。
「人間がプロンプトを指示」▶「テキストエンコーダが翻訳」▶「U-NETが不思議空間でAIにしか見えないお絵描きをする」▶「VAEが人間にも分かる『絵』に翻訳してくれる」という画像生成プロセスのうち、最後の翻訳部分を担当する役割だと理解すれば十分です。
VAEによって何が変わるかというと、主に学習モデルが生成した画像の色合いが変化します。こちらの画像は、全く同じ生成設定でVAEだけを変更したものです。

「違う。よく見ろ」
現在主流のSDXL系では、SDXL専用のVAEを使う必要がありますが、モデルに「同梱」されている場合が多いです。VAEの設定を「Automatic」や「none」にして普通に生成できたら、VAEが同梱されているモデルです。
学習モデルやLoRAなどに比べるとあまりたくさんのVAEが流通しているわけではありませんし、モデルに同梱されたVAEを使えば基本的に問題ないので、「ちょっと色が褪せて見えるな?」と思ったら別のVAEを使ってみる、程度の認識でOKです。

③プロンプトとネガティブプロンプト
プロンプトとネガティブプロンプトは、text to image(文章から画像生成)における最も重要な要素。AIはプロンプト欄に書かれた呪文を基に画像を生成します。「1girl,smile,sky,school uniform,peace sign,looking at viewer」などと、タグをカンマ「,」で区切って、盛り込みたい要素を箇条書きで並べていくのが基本。「被写体は何人でどんな構図か、どんな見た目の誰がどこで何をしているか、どんな画風か」を指定するのがコツです。
スペルを間違えても理解してくれることがありますが、「white hair ribbon」と指示したらキャラの髪が白くなってしまった("white hair"+ribbonと誤解された)、ということもたまにあるので、上手な意思疎通をするにはコツが要ります。

「何を生成するか」を指示するプロンプトに対し、「何を生成しないか」を入力する欄であるネガティブプロンプトも同じくらい重要です。求めていない被写体を「白黒にはしないで」「男は描くな」などと指示するだけでなく、「低品質な画像はダメ」と指示すると高品質になるので、この2つがうまく釣り合うことで意図通りのイラストが生成できるようになります。
詳しいプロンプトの書き方については、こちらの記事にまとめてあります。「超入門」の次にこちらを読むと、画像生成がスムーズにできるようになっていくと思います。

ローカル生成におけるプロンプト・ネガティブプロンプトについては「プロンプト超辞典」に詳しくまとめていますので、慣れてきたらこちらをご参照ください。
現在はモデルや生成環境の多様化が進み、ControlnetやLoRAなども登場したため、プロンプトは当初ほど大きな存在ではなくなってきています。日本語や英語の自然な文章で生成できるモデルも増えつつあり、たくさんの「呪文」を頭に入れなくても画像生成は十分楽しめます。
それでもやはり、プロンプト知識があるのとないのでは生成できるイラストのレベルが段違いになるもの。「このプロンプトを入れるとうちのモデルはこう反応するんだな」という経験が積み重なるほどに、画像生成はスムーズになっていくはずです。
④ステップとスケール

ステップ(サンプリングステップ数)は AI がノイズを取り除く作業の反復回数のこと。「トマトを持つ少女と犬」のイラストで実験したとおり、ステップ1だと、まだ意味のないノイズからさほど離れることができず、ぼんやりした概念のようなものが生成されます。ステップ数が多いほど絵のクオリティが上がる反面、生成に時間がかかり、ある程度以上はあまり差が生まれなくなります。
適正なステップ数は使用する学習モデルにもよりますが、「テスト生成は12以上、本番生成なら20以上推奨」が目安。私は30弱にすることが多いです。
スケール(CFGスケール)は直感的にわかりにくいですが、「プロンプトの忠実度」に近い概念です。低スケールだと柔らかい絵画風になり、高スケールにするほどディティールが細かく描写され、AIがより厳密にプロンプト(ユーザーの指示)を再現しようとする傾向にあります。学習モデルごとにおすすめのスケール値が案内されていることが多いので、それを参考にして好みに調整してみましょう。
こちらは同じ設定のイラストで、スケールだけを1~28まで変化させたもの。モデルによってスケール値による影響はさまざまですが、低すぎても高すぎてもおかしくなる感じが伝わると思います。


「white hair ribbon」というタグに敏感に反応し、「white hair」になりはじめている
ちなみに、こういう比較実験画像は「XYZプロット」というスクリプト機能で簡単に作ることができます。初めてのモデルで生成するとき、最適な設定を探るのに非常に役立ちますので、早めに習得しておきましょう。
⑤サンプリングアルゴリズム
AIがノイズ処理する際のアルゴリズムのことを「サンプラー(サンプリングアルゴリズム)」と言います。Euler a, Euler, LMS, Heun, DPM2, DPM2…とさまざまな種類があり、同じ学習モデル・SEEDでもサンプラーを変えると雰囲気がだいぶ変わります。これも、学習モデル配布時におすすめのサンプラーが案内されていることが多く、AnimagineXL系では「Euler a」を使うと良い結果になるようです。
普段のモデルでXYZ Plotを使い、サンプラーの比較実験を行ってみます。

同じプロンプト・設定でも、サンプラーによって全然違う画作りになることが分かると思います。右上のように崩壊してしまうサンプラーもありますが、それはそのサンプラーの性能が悪いわけではなく、モデルと相性が悪かったり、適切な設定値ではなかったりしたことが原因と思われます。
この他に「スケジュールタイプ(schedule type)」というものもあり、ノイズ除去がステップごとにどのように進行するかが変わります。
⑥SEED値
学習済みモデルは「完全なノイズ画像からノイズ除去を進めることでプロンプト通りの画像を作り出す」わけですが、最初に与える「完全なノイズ画像」にはさまざまなパターンがあり、それによって最終結果が変わります。そのパターンを決めるのが「SEED値」です。画像生成AIにおいては、生成画像ごとに割り当てられている「固有の背番号」のようなものと考えてみてください。
全く同じプロンプト指示をしても、このSEED値が異なると違うノイズパターンが与えられるため、違うイラストが生成されます。一方、同じSEED値を指示すると、全く同じ画像が生成できますし、プロンプトが多少変わっても、似たような構図にすることができます。
SEED値を「11111」に指定して4枚同時生成したとき、4枚とも同じ画像が出ると困るので、webUIはちゃんと1つずつずらしてくれます。ありがたい。

ランダムにSEED値を決めてほしい場合は「-1」と入力します。生成するたびに同じイラストが作られてしまうと困るので、特に事情がなければ基本的に「-1」にしておけばOK。欄の横のサイコロ「🎲」ボタンを押すと自動で入力されます。

おおむね好みのイラストができたけれども、ちょっと変えたいとか、クォリティをアップしたいときに、このseed値が役に立つことになります。隣の「♻️」ボタンを押すと、たったいま生成したSEED値が欄に自動入力されますが、その横の「その他」にチェックを入れると、同じSEED値で「ちょっとだけ変える」バリエーション生成が行えます。
こちらがSEED値「11111」のバリエーション生成。制服の襟や袖のラインなど、ほんのわずかにそれぞれ生成結果が異なっているのが分かるでしょうか。例えば、指が6本になってしまったとか、ちょっとだけ表情が物足りないといったときに、非常に役に立つ機能です。

詳しい使い方や実際のワークフローでの応用の仕方はこちらの記事で解説しています。
WebUIのインストール後にやるべきこと
A1111やForge、reForgeをインストールしたら、まずは日本語化や保存先の設定など、使いやすい環境にカスタムするところから始めましょう。インストール前後にやっておくべきことは基本的にこちらの記事に書いてありますので、参考にしてください。(A1111もForge系も、操作方法や画面の見た目はほとんど同じです)
そのほか、知っておくと生成が捗る設定やテクニックについては、こちらの記事にまとめてあります。生成した画像を綺麗に管理できるデータベース化の方法や、外出先から自宅の母艦PCを操作して生成するやり方など、覚えておくと役立つ小ワザをたくさん紹介しています。
学習モデルはどこで入手する?
さて、ここまでがStableDiffusionで画像生成するための基礎知識です。インストールがうまくいき、プロンプトやスケール値がどんなものか理解できれば、少なくとも「1girl,smile,sky」というプロンプトでイラスト生成することまではできるようになっているはずです。では、イラスト生成のクォリティに直結するモデル(checkpoint)やVAEなどをみなさんどこで入手しているのかというと、「HuggingFace」や「Civitai」といった海外プラットフォームが主な流通場所となっています。
<Huggingface>
「HuggingFace」は学習済みの機械学習モデルやデータセットなどを公開している米国発のプラットフォーム。下記のCIVITAIに比べてより技術者寄りで、アップデートや技術討論などが盛んに行われています。WebUI用の拡張機能などはこちらで配布されることが多いです。
<Civitai>

「CIVITAI」はStable Diffusionのモデルをアップロードできる海外プラットフォーム。こちらはHuggingFaceに比べてより一般ユーザー寄りで、多くのユーザーが学習モデルのほか、「LoRA」や「Textual Invarsion」と呼ばれる追加学習のファイルなどを公開しています。無修正の18禁画像などもバンバン出てきますので、表示設定や各モデルのライセンスをよく確認して、自己責任でご利用ください。

実際にイラストを生成してみよう
さて、ここまでの基礎知識を覚えたら、あとは実行するだけ。一緒にCivitaiからCheckpointを入手して、テスト生成をやってみましょう。このテストでは、SDXL系の人気アニメ調モデル「AnimagineXL3.1」を使用します。
【重要】ライセンスとパーミッションを確認しよう
AnimagineXL3.1をダウンロードする前に、Civitai上でライセンス欄を見てみましょう。

ライセンス欄にはSDXLのライセンスである「CreativeML Open RAIL++-M」と「Addendum(このAnimagineモデル独自の追加分)」があり、リンク先で全文(英文)を読むことができます。
さらにその横のショッピングカートのようなアイコンをクリックすると、このような注意書きが出てきます。これは、上記のライセンスを投稿者が嚙み砕いて表現した「やっていいこと・悪いこと」の一覧という位置づけです。

Stable Diffusionなど、多くの画像生成AIモデルはCreativeML OpenRAIL-Mライセンスか、その拡張版ライセンスで公開されています。例えば、SDXL1.0のライセンスは「CreativeML Open RAIL++-M」ですが、"-M"はライセンスの適用範囲がモデル(Model)に限定されているという意味。"+"(プラス)がついていると、もとのライセンスに追加の条件、制限、または拡張が加えられているバージョンであることを示しています。
こうしたライセンス表記を読まずにモデルを使用していると、知らないうちに権利侵害をしていて法的トラブルに巻き込まれる恐れがあります。特に、商用利用する場合はよく読んで、リスクがあることを十分理解した上で使う必要があります。忘れがちですが、LoRAやControlnetといった拡張機能にも一つ一つこうしたライセンスがあり、条件によって莫大な使用料を求めるようなものも中にはありますので、くれぐれもご注意ください。

さっそく生成してみよう
ライセンスとパーミッションを確認したら、さっそく画像生成してみましょう。
・リンク先からダウンロードしてきたanimagineXLV31_v31.safetensors(※6.46GBあります)を、webUIの「models\Stable-diffusion」フォルダに放りみます。
・横の青い更新ボタンを押すと、左上のプルダウンメニューに表示されます。
・その隣の欄のSD VAEは「Automatic」を選びましょう。

プロンプト欄には「1girl,upper body,smile,sitting,chair,sky, classroom,black hair,sailor uniform」と入力します。
キャンバスサイズは基本の1024×1024px、サンプラーは「Euler A」、ステップは28、スケールは7。Seed値は「11111」、CLIP SKIPは「2」とします。準備ができたら、右上の「生成」ボタンをクリック。

すると、このような画像が表示されました。

「セーラー服を着た黒髪の女の子が1人、笑顔で教室の椅子に座っており、空が映り込んでいる」というプロンプト通りのものが描かれていますね。VAEやステップ、Seed値などの設定値が全て同じなら、皆様の生成環境でもほぼ同じものが生成されたはずです。
より高精細にするには
さて、AnimagineXL3.1のCivitaiページをよく見ると、さまざまな推奨設定が書かれていることに気づきます。さきほどのサンプラーやステップ、スケール等は配布者の推奨設定を守ったものです。

ここに書かれているのは、イラストの品質を左右する「ネガティブプロンプト」と「クォリティタグ」と呼ばれるものです。
ネガティブプロンプト:生成したいものを記入する通常のプロンプト(ポジティブプロンプト)に対し、こちらは生成してほしくないものを記入する。「低画質なもの(low quality,bad quality等)は描かないで」と指示すると高画質になる。
クォリティタグ:ポジティブプロンプトに書き加えることで品質をアップできるタグ。「masterpiece, best quality」(傑作、最高品質)などがよく知られている。
仕様書の通り、クォリティタグを「1girl」の前に入れ、ネガティブプロンプト欄に指定された文字列を打ち込みました。これでもう一度生成してみましょう。

こちらの画像が生成されました。

なんだかいかにもAIらしい顔立ちだなぁと思った方は、AI絵をよくSNSなどで見てきた方でしょう。これが、Animagineの「マスピ顔」と呼ばれる顔立ちです。
マスピ顔(masterpiece顔)とは?
なぜこういう顔になるかというと、AnimagineXLの学習者が、学習データセットにあるイラストを以下のような「レーティング(ランク付け)」した上で学習させているからです。どこからがgreatでどこからがgoodかはまさにタグ付けした人物の主観によるわけですが、こうした品質によるタグがあると生成画像の品質管理も楽になるので、多くのモデルで取り入れられている手法でもあります。

「masterpiece, best quality」といったタグをポジティブプロンプトに入れ、「worst quality, low quality」などをネガティブプロンプトに入れたことで、そうしたタグ付けのされた画像に共通したあらゆる特徴が再現された(または遠ざかった)結果、最終的にこのような顔立ちが表現されたということですね。
イメージとしては、モンタージュで作る「平均顔」のような感覚が近いかと思います。顔の比率や塗り、線画の太さなど、「masterpiece, best quality」と評価された画像からさまざまな要素が平均化された結果、あのような画風に落ち着いたということです。

https://kyodonewsprwire.jp/release/202101250125
AnimagineXLを使うユーザーみんなが同じクォリティタグやネガティブプロンプトを使うと、このように誰もが投稿する画風がそっくり似通ってしまい、「AIっぽさあふれる画風」として認知されてしまいます。元はクォリティを上げるための取り組みだったのに、逆に没個性的になってしまっては意味がありませんね。

下の2枚は、どちらもAnimagineXLで生成した画像ですが、クォリティタグだけの違いでここまで画風が変わっています。このように、クォリティタグやネガティブプロンプトを独自のものにすることで、同じモデルでも画風はかなり大幅に変えることができるので、まずは自分らしい画風を見つけることが上達への道ということになります。

そして、いまでは各ユーザーが自分で追加学習を行うことで、プロンプトで制御するよりも個性的で一貫性のある画風を再現することが可能になってきました。こうした技術進歩により、人気モデルの一極集中による「あからさまなマスピ顔」の氾濫も、だんだんと収束していくものと思われます。

【コラム】画像サイズはとても重要
閑話休題。
さきほどはさらっと「1024×1024pxで生成しましょう」と説明しましたが、実はこの画像サイズをどうするかも絵作りと画質に大きく関わってきます。一般に、縦長のイラストには人物の全身像が描かれることが多く、横長のイラストには複数人数のバストアップが描かれることが多いのは想像できると思いますが、そうしたイラストで学習している学習済みモデルも、自然とキャンバスサイズによって描く構図が変わってくるのです。
キャラクターの全身図を描きたいなら「full body」などのタグを使いますが、縦長のキャンバスにしないと体の一部が見切れたり、不自然にかがんだポーズのイラストが出やすいことになります。こちらのイラストはすべて同じ設定でキャンバスサイズだけ変更したものですが、横長のキャンバスではかなりむりやり収めた感じがしますね。

また、キャンバスサイズは画質にも影響します。SD1.5系は512×512px、SDXL系は1024×1024pxの画像で学習しているため、これより大きくなりすぎても小さくなりすぎても上手に生成できず、画質が下がってしまいます。だいたい縦横のアスペクト比は4:3か16:9、大きくても3:2くらいにおさめておくと良いでしょう。
SDXL系モデルで4096x4096pxの画像をいきなり出そうとすると、このように大崩壊してしまいます。

これを避けて4096px規模の高精細なイラストを出す方法ももちろんあり、それが「アップスケール」と呼ばれる手法。それについては後述します。
生成した画像は必ず取っておこう
さて、ここまでで少なくとも「好きなモデルをダウンロードして」「設定やプロンプトを考えて」「画像生成する」という画像生成の基本まではたどり着きました。
ちなみに、StableDiffusionで生成された画像ファイルには、あなたが生成時に設定したSeed値やプロンプト、生成サイズといったあらゆる情報がちゃんと保存されています。Seed値などをいちいち書き留めておく必要がなくてありがたいですね。

text2imageのタブの2つとなりにある「PNG内の情報を表示」タブで画像を読み込ませると、このように生成時の情報をいつでも呼び戻すことができ、ボタンひとつでtext2imageのページにすべての情報を飛ばすこともできます。こうすることで、生成画像をちょっとだけ設定変更して、より意図通りにする…といったこともできるようになります。不要になったイラストも、あとでどんな役に立つかわからないので、削除せず大事にとっておきましょう。
pngを大事に取っておくべき理由はもう一つあります。AIイラストやそのユーザーに向けられている目は依然として厳しく、SNSなどに投稿していたら、「既存のイラストのパクリではないか」と突然疑われてしまうことがあるかもしれません。そういったときも、そのイラストのpngに内包されているプロンプトやseed値といった各種情報や、前後に生成したイラスト群がきちんと残っていれば、自分がそのイラストをどんな方法で作ろうとしていたかを示す何よりの証拠になります。

右の絵がどうやって生成したかを証明できるのはとても大切なことです
image2imageしてみよう
さて、ここまで説明してきたのは、完全なノイズ画像からプロンプトを頼りにイラストを作る「text2image」のやり方でした。画像生成AIを使ったもう一つの生成法が「image2image」です。
二つの違いはざっくり、このような感じ。

完全なノイズ画像からスタートするのではなく、自分で指定した画像をスタート地点にするので、色合いや形をある程度継承させることができるのがimage2imageのポイント。細部の書き込みを増やすクォリティーアップに使えるだけでなく、構図を維持しながら別のイラストに変えることもできますし、自分の手描きイラストをAIに「清書」してもらうこともできます。
←手描き / AIに直してもらったもの→
— 賢木イオ🍀AIイラスト (@studiomasakaki) March 2, 2024
自分の何がズレてるのか、次からどうしたらいいのか、得られるものが多すぎるのよ pic.twitter.com/6GSggVrRui
実際にやってみましょう。まず、さきほどテスト生成した画像を、「PNG内の情報を表示」タブで読み込ませます。

「img2imgに転送」ボタンを押すと、この画像と生成情報がすべてimg2imgのタブに転送されます。

さきほどの画像は1024x1408pxでしたので、そのサイズがデフォルト値として読み込まれています。画像サイズの設定は「Resize to」で縦横を数字で指定し直すこともできますし、「Resize by」で元画像の何倍、と指定することもできます。

ステップとCFGスケールはText2imgと同じ意味。ノイズ除去強度(Denoising)はノイズをどれほど加えて除去するか、つまり「どれくらいこの元画像を参照するか」を意味しています。ほとんどノイズを加えなければ元画像のままになりますし、ノイズを濃く掛けるほど新しい生成設定に近づくわけですね。
こちらは、モデルをAnimagineXLから私のオリジナルモデルに変えて「image2image」した例です。ノイズ除去強度が0だと元画像のままで、最大の「1」に近づくにつれて私のモデルの画風に近づいていくことが分かります。

image2imageアップスケール
今度は、さきほどの画像を「2倍」(つまり1024x1408pxから2048x2816pxへ)拡大してみます。ノイズ除去強度は0.5(50%)。うまくいけば、AnimagineXL3.1と私のモデルのハーフ&ハーフのような感じで、しかも2倍サイズに高解像度化してもらえるはずですが…。
こちらが生成されたもの。細部は高精細化していますが、よく見ると胸のあたりに指らしきものが増えていたり、両手がおかしかったりと破綻が見えるのが分かるでしょうか。

これは、元画像のポケットが肌色に近い色だったため、そこに指があると誤認されて、そのままノイズ除去が行われてしまったために起こった現象。さきほど4096pxサイズでいきなり生成しようとしたところ大崩壊を起こしましたが、それの小規模バージョンがここでも起きているわけです。
image2imageで大きなキャンバスサイズにアップスケールする場合、ノイズ除去強度が高すぎると細部が崩壊するし、弱すぎると効果が薄くなる。このトレードオフを理解することがまず第一歩です。アップスケールにはimage2image以外にもさまざまな手法やコツがありますので、こちらの記事にまとめています。
プロンプトの一部変更
image2imageはアップスケールに使うばかりではなく、画像の意図的な変更も行うことができます。今度はこちらの画像を読み込ませ、プロンプトに「angry」と書き加えてみましょう。

元画像をプロンプトにしたがって「描き直す」わけですが、大きく構図を変化させない内容なら…

ほぼ同じイラストで、表情だけを変更することができました。ノイズ除去委強度は0.75でしたので、かなり強力に変化させています。

髪の白いリボンに注目すると分かりやすいです
こちらはノイズ除去強度別の比較図。強度を高めるほどに「angry」度が増していくのが分かります。

ところで、ミナちゃんを「笑顔のTシャツ姿の男の子」に変えようとするとどうでしょうか。プロンプトは「1boy,upper body,grin,standing,sky,classroom,black hair,T shirt」に変えて、強度別にimage2imageしてみます。
こちらが生成結果。

このように、0.8でやっと眼鏡を消すことができ、最強の「1」でなんとか男の子に変えることはできましたが、もはやミナちゃんをimage2imageした意味がほぼありません。大幅な描き直しをするなら、最初からやり直した方がよいことが分かります。
「インペイント」で一部分だけi2i
さきほどは画面全体をimage2imageしましたが、イラストの一部だけに作用させる「インペイント」という機能もあります。これは、キャンバス上の良い部分は残して、気に入らない部分だけをピンポイントでレタッチ(修正)するimage2imageです。
このように、顔部分を「マスク」で塗りつぶして…

さきほどのようにプロンプトを変更して生成すると、今度は顔だけを変化させることができました!

このGIF動画は、顔以外のデザインをきちんと保持しながら、表情と手だけをインペイントで変化させたものの紙芝居です。
ミナちゃん百面相 pic.twitter.com/9pkE3B52Za
— 賢木イオ🍀AIイラスト (@studiomasakaki) December 12, 2024
NovelAIのインペイントに比べると、SDでのインペイントは操作がやや複雑ですので、使い方についてはこちらの記事をご参照ください。上の例はこの中で紹介している「controlnet(CN)インペイント」という手法で行っています。
NovelAI「V3」のインペイント機能は記事執筆時点で群を抜いており、表情変化だけでなく、服やポーズ、キャラごと変化させるなど、幅広い絵作りが可能になっています。こちらも解説記事が複数ありますので、ぜひ試してみて下さいね。
【重要】炎上やトラブルを避けるために
画像生成AIはさまざまな不可能を可能にする夢のようなツールですが、画像生成AIとそのユーザーに向けられる視線は厳しいものがあります。ひとたび使い方やウェブ上での言動を間違えると、誹謗中傷の対象となって「炎上」したり、最悪の場合は訴訟沙汰に陥ったりする恐れがあります。
何がマナーであるかはおのおのが考えるべきことですので、この記事でマナー講師のように「ユーザーのあるべき姿」を説いたりするつもりはありません。ここでは画像生成AIをめぐってこれまでにどのような問題やトラブルが起きてきたかを紹介することで、これを読む方が自衛するための一助にできればと思います。
1.他人の著作物のimage2image(i2iパクリ)
画像生成AIユーザーとして、最大のタブーの一つが「他人が権利を持つ画像をimage2image(通称i2i)すること」です。AIイラストをめぐっては、他人が苦労して描いたイラストをi2iして自作品と称したり、「こっちのほうがうまい」と愚弄したりする悪質行為が黎明期に繰り返し露見し、画像生成AIユーザー全体にとって大きなダメージとなりました。
二次創作でもこんなんされたら泣くわ pic.twitter.com/3Y7st4BuuR
— 山波つい (@tsuitate1572) January 22, 2023
i2iパクリはどんなに加工しても元絵を知っている人にはバレますし、著作権侵害訴訟に発展する恐れもあります。絶対にしないようにしましょう。i2iしていいのは、主に「自分でt2iした画像」「自分で描いた絵」「自分で撮った写真」「使用許可を取っている素材」と、それらを元に自分で加工した画像だけだと思って下さい。Google画像検索で出てきた画像をポンと放り込んでi2i・・・のようなことを日常的にやっていると、あるとき突然権利者の代理人弁護士からお手紙が届くことになりかねません。
AI生成物と著作権の関係をどのように理解すればよいかについては、文化庁が有識者を集めて議論を重ね、「素案」を作ってパブリックコメントも募集した上で、2024年3月に「AI と著作権に関する考え方について」という資料にまとめられました。

非常に長大な内容の上、正確性を期すためにある程度著作権法の知識がないと何を伝えたいのか分かりにくい言い回しがたくさん出てきますので、まずは要点のみをまとめた「概要版」を読むことをオススメします。ここに示された考え方は、あくまで有識者が「現行法や過去の判例からはこう解釈するべきであろう」と示したもので、最終的には裁判官による司法判断に委ねられることも覚えておきましょう。
ポイントは、手書きだろうがAIだろうが、「他人の著作物に相当類似していて、それが偶然でなければアウト」ということ。これを「類似性」と「依拠性」と言います。たとえある著作物に依拠して(パクって)いても、そもそも似ていなければ著作権侵害ではありませんから、image2imageのノイズ除去強度を強めれば、権利侵害と言えるか微妙な状態にはなります。それでも他人の著作物のi2iはトラブルを巻き起こすものですから、自衛のためにも手を出さないのが賢明でしょう。
i2iパクリをめぐるこれまでの経緯は、こちらの全体公開記事でも紹介しています。パクリ行為だけでなく、2022年10月以降のAIイラスト技術の歩みも俯瞰できるつくりになっていますので、時間がある方はご一読ください。
2.クリエイターへの敬意のない言動
画像生成AIは絵心のない人でもハイクォリティなイラストを生成できる反面、苦労してイラスト技術を研鑽してきた人々にとっては、「これまでの努力を無にするもの」と受け取られても仕方のない技術です。ただでさえそうした背景がある上に、他人の作品のi2iや画風を模倣したLoRAを使った嫌がらせを行うユーザーが相次いで現れ、イラストレーターや漫画家、作家などクリエイターへの敬意に欠けた言動も繰り返されてきました。
FANZAやPixivといったプラットフォームでは、粗製濫造した作品を毎日大量投稿する行為が散見され、ランキングやタグがAI生成作品ばかりになってしまう現象も。この問題は、のちに表示方式の変更やAIフロアへの隔離、FANBOXやファンティアといった支援サイトでのAI生成コンテンツの投稿禁止といったことにつながってしまいました。(※ちなみに、AI生成の技術解説コンテンツは独自の創作性を持ったコンテンツとしてFANBOXの利用が認められています)
クリエイターを軽んじるような言動は、合法かどうかを問わずトラブルを招きます。最終的に法廷で無罪や訴えの却下を勝ち取れたとしても、トラブルになった時点で人生割とめちゃくちゃになるわけですよね。AIイラストを楽しめる日常を守るためにも、本物の法廷バトルに巻き込まれないためにも、おのおのがラインを引いて行動することが大切だなと感じています。
一方で、画像生成AIを利用した人物・企業に対し、SNS上で一方的に苛烈な言葉を浴びせる事案も枚挙にいとまがありません。例えば、Xの人気アカウントとして知られるナウル共和国政府観光局(@nauru_japan)は24年9月、Grokで生成したナウルの風景を投稿したことが不適切だとされ、大炎上に巻き込まれました。
【生成AIについて】
— ナウル共和国政府観光局(公式) (@nauru_japan) December 12, 2024
先日より、多くの皆様がGrokを使い始められていて、以前に我々がXの新機能であるGrok使用(AI使用)を明記して、試験的にナウル風景の画像を作成して投稿したポストが一部の方から叩かれて大炎上したのはどういうことだったのかと考えています。… pic.twitter.com/kClEEVS5cR
画像生成AIを使っただけで、または逆に画像生成AIへの懸念を口にしただけで、誹謗中傷や攻撃のターゲットにしてよいという法はありません。個人的には、文化庁の示した「考え方」に沿って利用している限り、必要以上に萎縮する必要はないと考えています。
<コラム:AI絵を「描いた」と言うリスク>
AIイラストを投稿する人は当初、SNSで「AI絵師」と呼ばれ、気軽に自称する人も多くいました。ところが、次第に「描いていないのに絵師を名乗るな」と憤る人や、「AI絵師=AIイラストを自分で手描きしたとうそをつく人」の意味に使う人が増えていき、にわかに蔑称化。いまでは自称する人はほとんどいなくなり、悪口として使われているのを目にした人が「彼らは描いていないのに絵師を名乗っているのか」と怒る状態になっています。
その後、呪文を唱えるイメージから「AI術師」などの言い換えが生まれましたが、さほど定着しなかったようです。スタジオ真榊では単に、「画像生成AIユーザー」や「AIイラスト投稿者」を使うことが多いです。
こうした言葉狩りのような現状は全くよくないことですが、初心者が悪気なく「AI絵師です」とか「AIを使って絵を描いています」とSNSに投稿しただけで襲いかかる人がたくさんいます。中には、生成画像を画像編集ソフトで加筆修正している様子を投稿したのを「手描き詐称」とみなして攻撃的な言葉とともに晒し上げる迷惑ユーザーも。
これから画像生成AIを触る人が自衛するために、こうした現状はありのままにお伝えしておくべきと考え、コラムとして掲載しておきます。
3.無修正画像の投稿
これはちょっと違う方向からの注意事項。画像生成AIが生成するエロ画像は、性器のほとんどが無修正であることが多いです。これは、日本以外の多くの国では性器にモザイクを掛ける習慣がなく、エロ画像を生成するために学習させた画像セットが無修正のものであることに由来しています。
自分で楽しむぶんには良いのですが、投稿するときは画像編集ソフトなどを使って、必ず自分で修正しましょう。プラットフォームからのアカウントBANを避けるためにも、センシティブ表記をONにする、R-18タグをつけるといったSNSごとのNSFW投稿ルールも調べておくことをお勧めします。

AnimagineXL3のようにHイラストの描写が得意なモデルだと、全年齢イラストを作るつもりのプロンプトでも、nsfwなイラストが生成されてしまうことがあります。これは、ポジティブプロンプトに「safe」や「general」、ネガティブプロンプトに「nsfw」や「nude」などのワードを入れることで避けることができます。ちなみに「censored」「bar censored」「mosaic censoring」などのタグを使えば、修正したような状態でAI生成することも技術的には可能ですが、完璧ではありません。
4.「本物」と見紛う画像の投稿
著作権以外にも、配慮しなくてはならない名誉権や肖像権、パブリシティー権などの問題があります。画像生成AIに習熟してくると、例えば追加学習によって特定のイラストレーターの画風をそっくり真似たり、実在する人物の「存在しない写真」を生成したり、児童ポルノと見紛うような精巧な「非実在児童」のnsfw画像を生成したりすることができるようになります。
これらに共通するのは、「本物」と見紛う画像であるということです。こうした紛らわしい画像を公の場に公開すると、著作権上の問題をたとえクリアしたとしても、全く別の文脈で法的トラブルを招くことが考えられます。実在の人物や商標がからむ場合、「自分がされたら怒ることはしない」のが、自衛するために必要な行動だと思います。
<作風や画風は保護されない?>
画風の模倣については、よく「作風や画風はアイデアと同じで著作権保護されない」「著作権保護されるのは表現(上の本質的特徴)だけだ」ということが言われます。
これは事実ではありますが、画風模倣LoRAを作ったときに、画風だけでなく著作権保護された「表現」まで模倣できてしまうことが往々にあります。画風と表現の境界線は、訴訟で争われない限りはっきりしたことは言えませんので、
①「自分が模倣しているのは画風だけだから合法だ」と言っても通らないことがあること
②著作権法上は問題がなくても、名誉権や肖像権、パブリシティー権など別の文脈で権利侵害が認定されることもあること
をきちんと覚えておきましょう。
よく聞く「LoRA」って何?
さて、ここで触れておきたいのが「LoRA」の存在についてです。既存のキャラクターや有名絵師の画風を再現できる技術として、これから画像生成に触る方でも耳にしたことがあるのではないでしょうか。
AIが学習していない概念を後付けで学習させることを「追加学習」と言いますが、この追加学習の簡単便利な手法として特によく知られているのが、「LoRA」という技術です。既存キャラを再現するだけでなく、目のデザインだけを変えたり、ポーズや構図を指定したり、描き込みを増やしたり、逆にフラットな塗りに変えたり、線画にしたり、画風を変えたりと、アイデア次第でありとあらゆる効果のあるLoRAを作ることができます。

プラス適用するほど線が太くなり、マイナス適用するほど細くなる
LoRAは数十枚程度の教師画像とテキストのペアを自分で学習させることで実現でき、最近は1枚の画像からでも画風などを学習できるようになりました。出来には「うまい・下手」がありますが、素人でも作ることができます。

イラストの瞳や顔部分だけに適用する技術(ADetailer)
一方で、この技術により理論上あらゆる画像生成が可能になるわけですから、当然「本物に見える画像」の生成もできてしまいます。たとえば特定の有名人の写真を追加学習させたLoRAで不名誉なニセ写真を作ったり、特定イラストレーターの過去の作品を追加学習させて本人を装って画像を投稿したりといった行為は、トラブルを呼び込むばかりか、刑事事件や民事訴訟に発展する恐れもある危険な行為です。
確かに画風は著作権保護されませんが、自分が学習させたLoRAが作品群に共通する本質的表現まで模倣できてしまった場合、教師データのダウンロードなどの行為が著作権侵害になりうることが文化庁の「考え方」でも示されています。ウェブ上で共有されているLoRAを使って生成だけをする場合でも、あまりに特定著作物に類似している画像が出てしまい、それを私的利用の範囲を超えて利用すれば(SNSに投稿するなど)、著作権侵害になり得ます。
生成されたものを責任を持ってよく見て、公共の場に出してよいものかを考えることが身を守る上で重要となります。「手描きでやってダメなことはAIでやってもダメ」ということをよく覚えておきましょう。
Controlnetでできるようになったこと
23年2月に登場したcontrolnetも、LoRAと並んで非常に重要な拡張技術です。それまではプロンプトかimage2imageでしか生成画像のコントロールができなかったところに、線画や深度情報、ポーズなどを入力画像から抽出することで、より直接的に画像生成をコントロールすることが可能になりました。
線画を保持できる「Canny」や深度情報を保持できる「Depth」、落書きで構図を指示できる「Scribble」、マスク部分を自然に再生成できる「Inpaint」などさまざまな種類があり、活用法も多岐にわたっています。

現在圧倒的によく使うSDXL用Conrolnetは、月須和・那々さんの「Anytest v3」「Anytest v4」。この二つは線画部分を守りつつ、ほかの部分をプロンプト指示によって自在に変化させられる画期的なもので、大変重宝しています。V3のほうが線画を守る力が強く、V4は大きくスタイルチェンジできるのが特徴。例えばこのように、ミナちゃんのイラストを1発でフィギュア風に変えられます。

ContolnetはLoRAよりももっと高度な生成コントロールが可能になる拡張技術ですが、LoRAの追加学習と違って相当規模のデータセットの構築とマシンパワーが求められるため、個人で作るのは相当大変。開発者に感謝して使わせていただきましょう。
中級者になるために
ここまでの内容がだいたい飲み込めたら、ある程度好きなイラストを生成できるようになっていると思います。最初は好みの学習モデルを探したり、エッチな画像を作れるか試してみたり、プロンプトを勉強してみたり、スケールやステップ、サンプラーにこだわってみたり、LoRAを使ったイラストに挑戦してみたりと、触っているほどに上達していくことと思います。
次のような順番で知識をつけていくと、必要な技術を取りこぼすことなくスムーズに上達できると思います。上の方が基礎的技術で、下の方にいくほど高度なテクニックになっていきます。
・プロンプトの基礎知識をおおむね理解する
・生成に必要なタグを自力で見つけることができる
・いろいろなアップスケールができる
・バリエーション生成ができる
・必要なLoRAを探し、効果的に適用できる
・XYZ plotを使って最適な設定を探せる
・Controlnetでさまざまな構図操作ができる
・ローカル生成でインペイントができる
・Controlnetを使ったインペイントができる
・NovelAI V3でインペイントができる
・ADetailerで画質向上ができる
・CLIPSTUDIOを使って瞳や指の簡単な加筆修正ができる
AIイラストのためのCLIP STUDIO超入門
▶【第1回】プランとペンタブ選び、初期設定、おすすめ素材まで
▶【第2回】絵心一切関係なし!破綻した手を描き直す
▶【第3回】最重要ポイント『AI瞳』をレタッチしよう
・「1枚絵からのLoRA学習」ができる
・複数の技術を組み合わせて、より高度な画像生成ができる
・オリジナルキャラを身上書からデザインし、LoRAで容姿を再現できる
今読んで頂いている「AIイラストが理解る!」には、画像生成を始める上で最低限必要な知識をできるだけ網羅的に詰め込みましたが、ここから重要なのは「画像生成技術を使って、自分は何をしたいか」だと思います。
推しキャラの絵を生成したいのか、手描きイラストの補助にしたいのか、漫画を作ってみたいのか、はたまたNSFW目的なのか…。人によってやりたいことはさまざまだと思いますが、思ったとおりの絵を生成するためには、上に書いたようなさまざまな知識が必要になるはず。
いま紹介したものはこれまで公開してきた記事群のごく一部です。こちらのnote上で、これまでの検証記事をジャンル別に整理していますので、お役に立てばと思います。
終わりに
画像生成のワークフロー、つまり何のUIで何のモデルを使い、どんな設定で生成してどうアップスケールするかは、人によってさまざまです。そして、同じ人でも、時期によってどんどんその方法は変わっていきます。
2024年12月現在の私の生成フローは次のような感じですが、半年前とは全然違う技術で画像作りをしています。ベースモデルや拡張機能の進化はめまぐるしいので、半年後はまた全く違うことをしていると思います。
・Illustrious系モデルをベースにCoppyLoRAwebUIで自分画風LoRAを作り、マージモデルを作成
・ADetailer専用の顔修正・瞳修正LoRAを作成
・難解な構図の場合はNiji journeyで案出ししてControlnetを使用
・簡単な構図の場合は前景(人物)と背景を別々に生成
・足りない部分、間違っている部分をインペイントもしくは加筆で整える
・Clipstudioで最終仕上げ。グラデーション仕上げをしたり、ノイズやRGBずらしをしたり
例えばこの記事のタイトル画像。

これはこのように、まず色んなポーズの案出しをしてから、タイトル文字や説明文にミナちゃんの体が重ならないようなポーズを固め、バッグやスマホやさまざまな小物を別々に生成して、最終的にClipstuioで合成・加筆して作っています。

一番最初に生成した案をさかのぼると、こんなのでした。思いつくままにまずは色んな案を出してみて、それらを見比べて、何が必要で何を間引くべきかを考えて作っていくようにしています。AI絵は考えなしに要素を盛っていくとあまり良い結果にならないので、絵の魅力や意図がストレートに伝わる「引き算」の考え方が重要なのかなと思っています。

こちらのnoteにも書きましたが、私が画像生成AIに取り組んできたモチベーションは「理想のスレミオ(水星の魔女のキャラクター)が見たい!」に尽きているので、意図通りのポーズや表情、構図にするべく、ControlnetやLoRA、手描き技術との掛け合わせ方を重点的に研究してきました。
が、どの技術がその人にとって「使える」かは千差万別です。一番AIイラストのクォリティそのものが上がるのは、結局優れた学習モデルを入手することと、画風に合ったアップスケールの手法を身につけること。ただし、誰かにとっての「マスピ顔」ではなく、自分だけの「マスピ顔」を見つけて一貫性を持って生成できるようになることが大切…というのがこの2年間で得た個人的な考えです。
どんな創作でも、はじめから最終像のイメージがはっきりしていて、「あとはそれをその通り作るだけ」ということはほぼありません。さきほどのイルカ絵のように、まずはファーストアイデアを形にしてみて、ちょっと違うところを直してみたり、新しいアイデアを思いついて反映してみたり、先人の技術やアイデアを参考にしてみたりと試行錯誤しているうちに、だんだんとその人の創作性が表れてくるものだと思います。
AI創作に対する風当たりは依然厳しいものがありますが、人間の創意をきちんと込められた面白いAI作品がどんどん出てくれば、いずれは制作過程にAIを使ったかどうかで態度を変える人も減ってくるのではないかと思っています。
ここまで長い文章を読んでくださり、ありがとうございました。最新情報はXアカウントでお知らせしているので、ぜひフォローしてみてください。もしこの記事が何かの役に立ちましたら、こちらをリポストしていただけると嬉しいです。どうぞよろしくお願いします…!
今からAIイラストを覚えたい方向けに、140本を超える連載で得た知見を、3万字のnoteにまとめました。これだけ読めば、今のAIが何をできて何ができないか、最新事情がまるっと分かるはず。もちろん全文無料です。
— 賢木イオ🍀AIイラスト (@studiomasakaki) December 31, 2024
AIイラストが理解る!StableDiffusion超入門【2025年最新版】https://t.co/Z5gI4EOX0n pic.twitter.com/WDBx8bGRwj
これを読んでくださったあなたが、AIを活用したイラスト作りを楽しめることを祈っています。スタジオ真榊でした!
【おまけ】「♡スキ」を押すと謎の感謝画像が出ます(ノーマル、レア、SSRの全十種)