
DXプロジェクト構想をDifyでワークフロー化してみました

DXプロジェクト構想のフレームワークに関して、ChatGPTに考えさせてみた記事を書きました。ブラウザのChatGPTはインタラクティブでいいのですが、ステップが多いと作業が大変です。そこでDifyを使ってフロー化してみました。
※初めてDifyを使ったので無駄が多いと思いますが、何かの参考になれば幸いです。
全体像
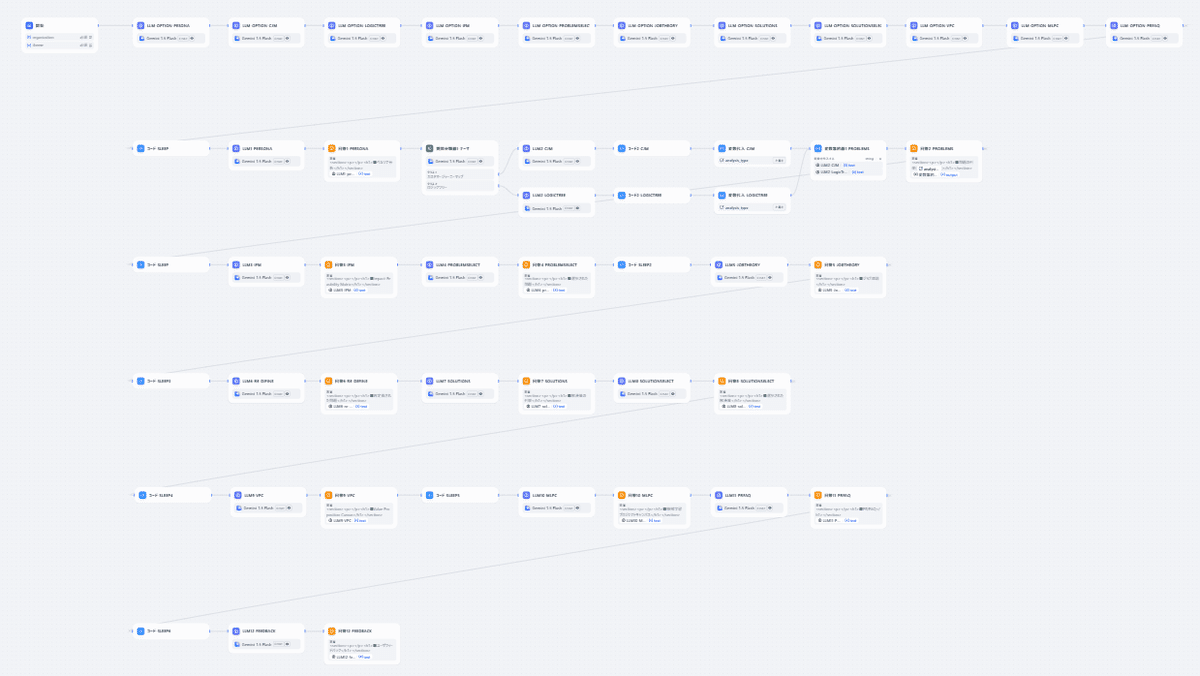
長いです。50ブロックもあります。基本構造は、開始ブロックのあとに「LLM→回答」という2つのブロックの繰り返しです。その他の要素は後半で説明します。
開始ブロック
まず開始ブロックですが、必須入力は「組織」と「テーマ」だけにしました。結果的にメインのプロンプトには何も書かなくていいという、チャット的でないUIになっています。「開始してください」などで始められますし、「解決手段として、需要予測は実装済みなので不要です」など特定のこだわりがあればプロンプトに記載します。そのこだわりをプロンプトに反映する方法は後述します。

LLMブロック
LLMのブロックはこんな感じです。DifyからChatGPTを叩くときはSYSTEMの部分にプロンプトを書くのに対し、GeminiだとUSERの部分にメインのプロンプトを書くようです。ですので、LLMのモデルを切り替えるとブロックの中身を編集しないといけないのが手間です。

フローのいいところは、考慮すべき要素を正確に書けることです。下のブロックは後半に出て来るのですが、上流のどのLLMの結果をどう反映させるのか非常に分かりやすいです。

質問分類器ブロック
フローの別の利点は、条件分岐ができることです。ここでは、テーマの内容によってカスタマージャーニーマップを用いるのか、ロジックツリーを用いるのかの分岐処理を行っています。


分岐の結果は変数集約器ブロックで集めますが、特に迷うところはなかったので説明は省略します。
その他の要素
冒頭に「LLM→回答」の繰り返しと述べましたが、その他の要素は2つあります。
ひとつは休止です。今回はライセンスの関係でGemini 1.5 Flashを使っているのですが、そのまま流すと1分あたりの使用量に引っ掛かって止まってしまうので、Pythonノードを用い、途中で10秒程度のsleepを入れて遅延させています。こんな原始的なこと、皆さん本当にやっているのでしょうか……
import time
def main() -> int:
time.sleep(10)
return {
'result': 0
}もうひとつは、プロンプトに書かれたこだわりの部分に関して、どのノードで反映させるかの解析です。本格的な処理をする前の冒頭部分に、プロンプトからペルソナ分析・カスタマージャーニーマップなどそれぞれの処理への言及内容を抽出しています。こちらも、もっとスマートなやり方がある気がします。

詰まったところ、未解決なところ
ワークフローかチャットフローか
最初は直感的にワークフローにしていました。動作としては全く問題ないのですが、結果の出力を終了ブロックでまとめて表示しますので、①最後になるまでユーザがぼーっと待つことになる ②文字数が多いと最後だけ表示され序盤の結果が見えない という形になり、本ユースケースでは向いていないことが分かり、チャットフローを採用しています。

回答の表示形式
回答ブロックの出力はどんどん追記される形で出力されるのですが、表形式と箇条書きなどが混在すると表示が崩れる傾向にあります。回答ブロックに無理やりHTMLのタグを記入するなどしましたが、解決できませんでした。結果的に表形式を断念し、すべて箇条書きにしています。
条件分岐のどちらを通ったかを表示
質問分類ブロックで分岐した際に、最終的に変数集約ブロックでまとめてしまうので、どちらを通ったのか分かりにくいことがあります。そこで、まずコードブロックで値を定義し、それを事前に定義した会話変数に代入することで解決しています。コードブロックで会話変数を直接扱えるか、変数代入ブロックで値を指定して代入できるかだったら良かったのですが、やり方が分からず回りくどい方法を採っています。

def main() -> str:
return {
'result': 'Customer Journey Map'
}APIの残クレジット
LLMのモデルは、最初はデフォルトのChatGPT o1-miniを使っていました。残クレジットが200から減らないけど大丈夫なのかな?と思っていたら、急に動かなくなって、チェックしたら残りゼロ。復活する条件も分からないのでGeminiに乗り換えましたが、初心者には分かりづらかったです。
結果
以下がこのフローの出力内容です。長いので流し読み推奨です。少し的外れな内容を含みますが、これはモデルの影響だと思っています。ChatGPT o1-miniやGemini 1.5 Flashなど簡易なモデルでは、やはり上位のモデルより分析精度は劣る印象です。本気で使う際には有料APIを契約した方が良さそうです。
■ペルソナ分析## 半導体大手製造業 従業員ペルソナ (10名)
1. 佐藤 健太郎 (48歳) 開発部門 シニアマネージャー
役割: 新製品開発の責任者。長年会社に貢献してきたベテランだが、最近の開発遅延に苦悩している。
性格: 真面目、責任感強い、几帳面だが、やや保守的で新しい技術への対応に戸惑いを感じている。
家族: 妻、大学生の子ども2人。住宅ローンを抱えている。
悩み: 新製品開発の遅れ、部下のモチベーション維持、自身のキャリアの将来。
目標: 次世代半導体の開発成功、部下の育成、早期退職後のセカンドキャリアの準備。
2. 田中 美咲 (25歳) 製造部門 生産技術者
役割: 新製造ラインの導入・保守を担当。最新技術に精通しており、意欲的な若手。
性格: 明るく社交的、好奇心旺盛、新しい技術を学ぶことに貪欲。
家族: 独身、一人暮らし。趣味は海外旅行とゲーム。
悩み: 仕事の忙しさ、ワークライフバランス、キャリアパス。
目標: 最新技術を習得し、専門家として認められること、海外勤務経験を積むこと。
3. 鈴木一郎 (60歳) 研究開発部門 上級研究員
役割: 長年半導体研究に携わってきた第一人者。豊富な知識と経験を持つが、最近は体力的な限界を感じている。
性格: 穏やかで知識豊富、几帳面だが、やや頑固な面もある。
家族: 妻と二人暮らし。定年退職が近い。
悩み: 体力的な衰え、後進の育成、自身の研究成果の継承。
目標: 後進に技術を伝え、研究成果を社会に役立てること。穏やかな老後を送ること。
4. 渡辺 花子 (32歳) 人事部 採用担当
役割: 新卒・中途採用の担当。優秀な人材確保に奔走している。
性格: 親しみやすく、コミュニケーション能力が高い。責任感も強い。
家族: 結婚5年目、まだ子供はいない。
悩み: 優秀な人材の確保、採用活動の効率化、仕事と家庭の両立。
目標: 企業の成長に貢献できる人材を採用すること、ワークライフバランスを実現すること。
5. 山田太郎 (55歳) 営業部門 課長
役割: 海外顧客との取引を担当。グローバルな視点と交渉力を持つ。
性格: 積極的で外交的、交渉力が高いが、やや短気な面もある。
家族: 妻と中学生の子ども。
悩み: 新製品不足による顧客からのクレーム、海外出張の多さ、部下の育成。
目標: 新製品の早期リリース、顧客満足度の向上、部下の成長。
6. 吉田 恵子 (28歳) 品質管理部門 検査員
役割: 製品検査を担当。正確さと細やかさが求められる職務。
性格: 真面目、几帳面、責任感強い、几帳面で真面目だが、やや神経質な面もある。
家族: 独身、一人暮らし。趣味は読書と映画鑑賞。
悩み: 仕事のプレッシャー、ミスへの恐怖、将来のキャリアプラン。
目標: 製品品質の向上に貢献すること、専門性を高めること。
7. 加藤 誠 (38歳) 生産管理部門 係長
役割: 生産ラインの管理を担当。効率的な生産計画の立案と実行が求められる。
性格: 理性的、計画的、責任感強い。
家族: 妻と小学生の子ども1人。
悩み: 生産ラインの効率化、人材不足、残業時間の削減。
目標: 生産効率の向上、コスト削減、働き方改革の推進。
8. 森下 あき (45歳) 財務部門 経理担当
役割: 会社の財務状況の管理を担当。正確性と効率性が求められる。
性格: 真面目、几帳面、責任感強い。
家族: 夫と高校生の子ども1人。
悩み: 会社の財務状況の悪化、コスト削減、将来への不安。
目標: 会社の財務状況の改善、安定した経営の維持。
9. 高橋 亮 (22歳) 技術開発部門 研究員
役割: 新技術の研究開発に従事。意欲的な若手。
性格: 好奇心旺盛、学習意欲が高い、やや内向的。
家族: 独身、一人暮らし。趣味はプログラミングと読書。
悩み: 研究の進捗、成果が出ないことへの焦燥感、将来への不安。
目標: 新技術の開発、専門家の育成。
10. 小林 美紀 (50歳) 人事部 人事部長
役割: 人事部門のトップとして、全社の従業員管理を担当。
性格: 落ち着いていて、冷静な判断力を持つ。
家族: 夫と社会人になった子ども。
悩み: 人材不足、従業員のモチベーション維持、企業文化の改革。
目標: 企業の成長に貢献できる人材育成、働きがいのある職場環境づくり。
これらのペルソナは架空の人物ですが、現実の半導体企業の従業員を参考に、可能な限りリアルに描写しました。 それぞれの年齢、職種、性格、家族構成、悩み、目標などを考慮することで、より具体的なイメージが掴めると思います。
■問題の列挙(Logic Tree)*
**投資対効果が出ない原因の特定**
* システム導入における課題
* 導入前の要件定義の不足
* システムの機能不足・不適合
* 従業員のスキル不足・抵抗感
* 導入後の運用・保守の不備
* プロセス改善の不足
* 外部環境要因
* 市場環境の変化
* 競合状況の変化
* 経済状況の変化 *
**現状分析**
* 導入したERPシステムの機能と利用状況の把握
* 従業員のシステム利用状況と満足度調査
* 導入前後の業務効率、コスト、売上等のデータ比較分析
* 競合他社の状況調査 *
**改善策の検討**
* システムの機能拡張・カスタマイズ
* 従業員教育・研修の実施
* 業務プロセスの再設計・改善
* 外部コンサルタントの活用
* システムの刷新・代替案の検討
* 部分的なシステム廃止・代替システム導入 *
**費用対効果の検証**
* 各改善策の費用と効果の試算
* ROI(投資収益率)の算出 * リスク評価 *
**優先順位付けと計画策定**
* 改善策の優先順位付け
* 実施スケジュール策定
* 担当者割り当て * 予算確保 *
**実行とモニタリング**
* 改善策の実施
* 定期的な進捗状況の確認
* 効果測定 * 問題点の発見と解決 *
**評価と改善**
* 最終的な投資対効果の評価
* 改善点の洗い出し
* 今後の戦略への反映
このロジックツリーは、問題解決のための段階的なアプローチを示しています。各項目はさらに詳細に分解し、具体的なアクションプランを作成する必要があります。
■Impact-Feasibility Matrix
以下に、Impact-Feasibility Matrix の結果を、指示に従って箇条書きで出力します。インパクトと技術的可能性は主観的な判断に基づいて1~5の段階で評価しています。
問題: 導入前の要件定義不足によるERPシステムの機能不適合
解決策: 要件定義支援ツールを用いた詳細な要件定義プロセス
インパクト: 3 (業務効率の向上、一部コスト削減)
技術的可能性: 4 (ツールは容易に入手可能)
問題: ERPシステムの機能不足
解決策: システムのカスタマイズ、追加機能開発
インパクト: 4 (業務効率の大幅向上、コスト削減)
技術的可能性: 3 (開発難易度、コスト次第)
問題: 従業員のスキル不足によるシステム活用率の低さ
解決策: オンライン研修システムによるeラーニング導入
インパクト: 3 (業務効率の向上、エラー減少)
技術的可能性: 5 (容易に導入可能)
問題: 従業員のシステム利用抵抗
解決策: 従業員へのヒアリングと改善提案システム導入
インパクト: 2 (心理的抵抗の軽減、間接的な効率向上)
技術的可能性: 4 (比較的容易なシステム導入)
問題: 導入後の運用・保守の不備
解決策: システム運用管理ツール導入、保守契約の見直し
インパクト: 3 (システム安定性向上、ダウンタイム減少)
技術的可能性: 4 (ツール・契約は容易に入手可能)
問題: プロセス改善の不足
解決策: 業務プロセス分析ツールを用いたプロセス改善
インパクト: 4 (業務効率の大幅向上、コスト削減)
技術的可能性: 3 (ツールの選定と導入に時間とコストが必要)
問題: 市場環境の変化への対応不足
解決策: リアルタイムデータ分析ダッシュボード導入
インパクト: 5 (迅速な意思決定、市場変化への柔軟な対応)
技術的可能性: 4 (導入は比較的容易)
問題: 競合状況の変化への対応遅れ
解決策: 競合情報分析システム導入
インパクト: 4 (競争優位性の維持・向上)
技術的可能性: 3 (データ収集と分析の難易度次第)
問題: 経済状況の変化への対応不足
解決策: 予測分析システムによるリスク管理強化
インパクト: 3 (リスク軽減、コスト最適化)
技術的可能性: 2 (予測精度の限界、高度なシステムが必要)
問題: ERPシステムの機能と利用状況の把握不足
解決策: システム利用状況監視ツール導入
インパクト: 2 (現状把握の精度向上)
技術的可能性: 5 (容易に導入可能)
問題: 従業員のシステム利用状況と満足度の把握不足
解決策: 従業員アンケートシステム導入
インパクト: 2 (問題点の早期発見、改善策の検討)
技術的可能性: 5 (容易に導入可能)
問題: 導入前後の業務効率、コスト、売上等のデータ比較分析不足
解決策: データ分析ツール導入、KPI設定とモニタリング
インパクト: 4 (効果測定の精度向上、改善策の検証)
技術的可能性: 4 (ツールは容易に入手可能)
このリストは、問題解決のための優先順位付けや、より詳細なアクションプラン策定の基礎として活用できます。 インパクトと技術的可能性の評価はあくまで目安であり、状況に応じて修正する必要があります。
■選択された問題インパクトと技術的可能性の合計点を計算し、最も高いものを選びます。
合計点が最も高いのは「市場環境の変化への対応不足」(合計9点)と「従業員のスキル不足によるシステム活用率の低さ」(合計8点)、「導入前後の業務効率、コスト、売上等のデータ比較分析不足」(合計8点)です。
同点である「従業員のスキル不足によるシステム活用率の低さ」と「導入前後の業務効率、コスト、売上等のデータ比較分析不足」のうち、私は**「市場環境の変化への対応不足」**を選択する。
その理由は、インパクトが5と最も高く、ビジネス上の影響度が非常に大きいと判断したためです。 市場環境の変化に対応できないことは、企業の存続に関わる重大な問題であり、迅速な意思決定と柔軟な対応が求められます。リアルタイムデータ分析ダッシュボードの導入は、この問題に対する効果的な解決策であり、技術的可能性も高いことから、優先順位を高くすべきと考えます。 一方、スキル不足やデータ分析不足は重要ではありますが、市場環境の変化への対応遅れほど、緊急性とインパクトが大きいとは言い切れません。
■ジョブ理論
未達成の目標: 企業の持続的な成長と競争優位性の確保
状況: 市場環境の変化や競合状況の変化への対応が遅れ、ビジネス上の大きな損失や機会損失が発生している可能性がある。現状のシステムやデータ分析では、迅速かつ的確な意思決定が困難。
障壁: 市場環境の変化への対応不足、データ分析による迅速な意思決定の遅れ、従業員のスキル不足によるシステム活用率の低さ。
代替: 現状のシステムや分析手法を無理やり活用し、部分的な対応をしているが、不十分で非効率。
基準: インパクト(ビジネスへの影響度)と技術的実現可能性の高さ。 企業の存続に関わる重大な問題への対応を優先する。犠牲にできる側面は、短期的なコストや、比較的影響の少ない問題への対応の遅れ。
■再定義された問題
**再設定された問題:**
企業の持続的な成長と競争優位性を確保するために、市場環境の変化に迅速かつ的確に対応できる意思決定システムを構築する必要がある。 これは、現状のデータ分析能力の不足と従業員のスキルギャップを克服し、ビジネス上の損失や機会損失を最小限に抑えることを含む。
より具体的には、以下の3つの課題を解決する必要がある。市場環境変化へのリアルタイムな対応能力の向上: 市場トレンドや競合動向を迅速に把握し、それに基づいた戦略的・戦術的な意思決定を可能にするシステムを構築する。
データに基づいた迅速かつ的確な意思決定プロセスの確立: 既存データの有効活用と新たなデータ分析技術の導入により、意思決定に必要な情報を迅速に提供し、その精度を高める。
従業員のデータ分析スキル向上とシステム活用率の最大化: 従業員が新しいシステムを効果的に活用できるよう、適切なトレーニングプログラムを提供し、システムの使いやすさを向上させる。
この再設定された問題は、元の結果に示された未達成目標、状況、障壁、代替案、基準を統合し、解決すべき核心的な問題を明確に示しています。 優先順位は企業の存続に関わる問題への対応に置かれ、短期的なコストや影響の少ない問題への対応の遅れは犠牲にできるとしています。 具体的な3つの課題を設定することで、解決策の策定と進捗管理が容易になります。
■解決策の列挙
企業の持続的な成長と競争優位性確保のための意思決定システム構築に関する20以上のデジタル技術ソリューション:
リアルタイムデータストリーム処理プラットフォーム (e.g., Apache Kafka, Apache Flink): 市場データのリアルタイム収集と分析。
AI搭載ダッシュボード (e.g., Tableau, Power BI): 重要な指標の可視化と迅速な意思決定支援。
予測分析プラットフォーム (e.g., SAS, SPSS): 未来の市場動向予測とリスク管理。
機械学習モデル (e.g., TensorFlow, PyTorch): 競合分析、顧客セグメンテーション、需要予測。
自然言語処理 (NLP) エンジン: 市場調査レポートやニュース記事からの情報抽出。
センチメント分析ツール: ソーシャルメディアや顧客レビューからの市場感情分析。
競合分析プラットフォーム: 競合企業の戦略や動向の追跡。
ビジネスインテリジェンス (BI) ツール: データ分析とレポート作成。
データ統合プラットフォーム (e.g., Informatica, Talend): 複数データソースからのデータ統合。
クラウドコンピューティングサービス (e.g., AWS, Azure, GCP): スケーラブルなデータ処理と分析環境。
データ可視化ツール (e.g., D3.js, Plotly): データの視覚的な表現と理解促進。
意思決定支援システム (DSS): データに基づいた意思決定プロセスを支援。
シミュレーションソフトウェア: 様々なシナリオにおける影響予測。
オンライン学習プラットフォーム (e.g., Coursera, Udemy): 従業員のデータ分析スキル向上。
内部トレーニングプログラム: カスタム設計されたデータ分析トレーニング。
デジタルツイン技術: ビジネスプロセスのシミュレーションと最適化。
ロボットプロセスオートメーション (RPA): 反復的なタスクの自動化。
ブロックチェーン技術: データのセキュリティと信頼性の向上。
IoTセンサーとデータ収集システム: リアルタイムの市場データ収集。
自動化されたレポート生成ツール: 効率的なレポート作成と情報共有。
知識ベースシステム (Expert System): 専門家の知識をシステムに組み込み、意思決定支援。
カスタマーリレーションシップマネジメント (CRM) システム: 顧客データ分析と顧客理解の深化。
これらの技術は単独で、あるいは組み合わせて利用することで、3つの課題を解決し、企業の持続的な成長と競争優位性を確保する意思決定システムを構築できます。 優先順位は、リアルタイム対応能力の向上(1, 2, 3, 4, 5, 6, 7, 19)とデータに基づいた意思決定プロセスの確立(8, 9, 10, 11, 12, 13, 21, 22)に置かれ、従業員のスキル向上(14, 15, 16)はそれらと並行して進めるべきです。 RPA (17) とブロックチェーン (18) は、必要に応じて導入を検討します。 自動化されたレポート生成 (20) は、効率化に貢献します。
■選択された解決策ベストな方法は**機械学習モデル (4)**です。
根拠:
他の多くの解決策は、機械学習モデルによって実現できる機能のサブセット、あるいはそのための基盤技術に過ぎません。 例えば、リアルタイムデータストリーム処理(1)やデータ統合(9)は機械学習モデルの入力データを提供する役割、AI搭載ダッシュボード(2)は機械学習モデルの出力結果を可視化する役割、予測分析(3)は機械学習モデルの一種、競合分析プラットフォーム(7)やセンチメント分析ツール(6)は機械学習モデルによって高度化できる機能です。 ビジネスインテリジェンス(8)も、機械学習モデルによってより高度な分析が可能になります。
機械学習モデルは、競合分析、顧客セグメンテーション、需要予測など、企業の持続的な成長と競争優位性確保に直接的に貢献する様々なタスクを自動化・最適化できます。 他の多くのソリューションは、このコアとなる分析能力を支える周辺技術であり、機械学習モデルがなければその効果は限定的です。 したがって、シンプルな結論として、最も効果的で包括的な解決策は機械学習モデルとなります。
■Value Proposition Canvas
## Value Proposition Canvas - 半導体大手製造業
Value Proposition: 市場変化への先回り対応による、持続的な成長と競争優位性の確保
Customer Segment: 半導体大手製造業における、経営層と戦略立案部門の意思決定者
Customer Jobs: 市場の動向を的確に予測し、新製品開発戦略を迅速に立案・実行すること。
Pains:新製品開発の遅れによる機会損失
市場トレンドの把握不足による戦略ミスの発生
競合製品への対応の遅れ
データ分析の非効率性による意思決定の遅延
従業員のスキル不足によるシステムの活用率低下
Gains:新製品の早期市場投入による収益増加
競合優位性の強化
迅速かつ的確な意思決定によるリスク軽減
データに基づいた戦略立案による成功確率向上
従業員の能力向上と生産性向上
Products and Services: 機械学習モデルを活用した予測分析システム
Pain Relievers:リアルタイム市場データ分析による迅速な状況把握
予測精度の高い需要予測モデルによる新製品開発戦略の最適化
競合分析によるリスク軽減と戦略策定支援
従業員向けの機械学習モデル活用トレーニングプログラム
Gain Creators:新製品開発のリードタイム短縮
市場シェア拡大
収益増加と利益率向上
データに基づいた意思決定による自信の向上
従業員のスキル向上とモチベーション向上
■機械学習プロジェクトキャンバス
## 機械学習プロジェクトキャンバス:半導体大手製造業向け新製品開発支援システム
Purpose/Goal: 新製品開発の遅延を解消し、市場投入までのリードタイムを短縮することで、競争優位性を回復し、持続的な成長を実現する。
User Segments: 新製品開発部門のエンジニア、製品企画担当者、経営層(意思決定者)。特に、新製品開発の遅延に責任を持つ中堅〜上級エンジニア。
Actions Based on the Prediction: 機械学習モデルによる予測(需要予測、競合製品分析、技術トレンド予測など)を参考に、新製品の開発内容、投入時期、リソース配分を決定する。 予測結果を基に、リスクを軽減した開発計画を策定する。
Metrics of Success:需要予測の精度:平均絶対パーセント誤差 (MAPE) 15%以下
競合製品分析の精度:市場シェア予測の誤差 ±5%以内
技術トレンド予測の精度:主要技術の登場時期予測の誤差 ±6ヶ月以内
新製品開発期間の短縮率:現状比 20%短縮
Data:販売データ(過去5年間、製品別、地域別):数十万件
市場調査データ(市場規模、競合製品情報、顧客ニーズ):数千件
技術動向データ(特許情報、論文、技術発表):数百万件
内部開発データ(開発コスト、開発期間、技術課題):数万件
顧客フィードバックデータ(アンケート、レビュー):数万件
Algorithms/Infrastructure for Trial:アルゴリズム:時系列分析(ARIMA、Prophetなど)、回帰分析(線形回帰、ランダムフォレストなど)、クラスタリング(k-means、DBSCANなど)、自然言語処理(BERT、GPTなど)
インフラ:クラウドベースの機械学習プラットフォーム(AWS SageMaker、Google Cloud AI Platformなど)、GPUサーバ
Data Enhancement:専門家の知識を用いたデータ補正:市場調査データ、技術動向データの精度向上
シミュレーションによるデータ生成:市場環境の変化をシミュレートし、予測モデルの頑健性を向上
半構造化データ(技術文書、特許明細書)からの情報抽出:自然言語処理技術を活用
Open Strategy:学習済み機械学習モデル:需要予測、センチメント分析モデルなど
オープンデータ:市場調査データ、技術動向データなど
Past Knowledge/Professional Advisors:過去の失敗事例:新製品開発の遅延、市場ニーズの読み違い
専門家:新製品開発部門のベテランエンジニア、市場調査担当者、技術開発担当者
UI/Systems for End Users:ダッシュボード:予測結果、開発状況、リスクなどを可視化
API:機械学習モデルへのアクセスを提供
レポート機能:予測結果、分析結果をレポートとして出力
Model Update/Maintenance:定期的なモデル再学習:最新データを用いてモデルを更新
パフォーマンスモニタリング:モデルの精度を継続的に監視
フィードバックループ:ユーザーからのフィードバックを収集し、モデルを改善
Expansion/Secondary Goal:新製品開発プロセス全体の最適化:開発工程の自動化、効率化
顧客ニーズのより深い理解:顧客セグメンテーション、パーソナライズドマーケティング
リスク管理の強化:市場リスク、技術リスクの予測と軽減
このキャンバスは、半導体大手製造業の現状と課題を踏まえ、機械学習モデルを活用することで新製品開発を加速させ、競争優位性を回復させるための具体的な計画を示しています。 各項目は、企業の持続的な成長という最終目標達成に貢献するよう設計されています。
■PR/FAQ## プレスリリース資料
発表日: 2024年10月26日
タイトル: [企業名]、AI駆動型新製品開発支援システム「[システム名]」を発表 ― 市場変化への先回り対応で持続的な成長を実現 ―
本文:
[企業名](本社: [所在地]、代表取締役社長: [代表取締役社長名])は本日、機械学習を活用した新製品開発支援システム「[システム名]」を発表いたします。「[システム名]」は、最新のERPシステム導入による投資対効果の最大化を図るべく、市場動向の予測精度向上と新製品開発期間の短縮を目的として開発されました。
半導体業界は、激しい市場競争と技術革新により、新製品の迅速な開発と市場投入が企業の存続と成長に不可欠となっています。従来の開発プロセスでは、市場トレンドの把握不足やデータ分析の非効率性、従業員のスキル不足などが課題となっていました。
「[システム名]」は、これらの課題を解決するため、最先端の機械学習技術と豊富なデータ分析ノウハウを統合したシステムです。リアルタイムの市場データ分析、精度の高い需要予測、競合分析、技術トレンド予測などを提供することで、新製品開発における意思決定を迅速かつ的確に支援します。
主な機能:リアルタイム市場データ分析: 最新の市場動向を即座に把握し、迅速な対応を可能にします。
精度の高い需要予測: 平均絶対パーセント誤差(MAPE)15%以下の精度で需要を予測し、最適な開発計画策定を支援します。
競合分析: 競合製品の動向を分析し、市場シェア予測誤差±5%以内の精度でリスクを軽減した戦略立案を支援します。
技術トレンド予測: 主要技術の登場時期予測誤差±6ヶ月以内の精度で、技術開発戦略の最適化を支援します。
従業員向けトレーニングプログラム: システムの活用方法を習得するためのトレーニングプログラムを提供し、従業員のスキル向上を支援します。
ダッシュボードによる可視化: 予測結果、開発状況、リスクなどを直感的に理解できるダッシュボードを提供します。
導入効果:
「[システム名]」の導入により、[企業名]は新製品開発期間を現状比20%短縮することを目指しています。これにより、市場機会の早期獲得、収益増加、競争優位性の強化を実現できると期待しています。さらに、データに基づいた意思決定により、リスク軽減と経営の安定化にも貢献します。
「[システム名]」は、社内向けシステムとして、新製品開発部門のエンジニア、製品企画担当者、経営層(意思決定者)を主なユーザーとして展開していきます。
報道陣向け想定QA:
Q1: このシステムは、社内システムとしてのみ利用されるのでしょうか?将来的に外部企業への提供は検討されていますか?
A1: 現状は社内システムとして運用する予定ですが、将来的には、本システムの技術やノウハウを活かしたソリューションを外部企業向けに提供する可能性も検討しています。特に、半導体業界以外の業界にも応用可能な汎用的な機能を備えているため、市場ニーズを調査した上で、提供範囲を拡大していく予定です。
Q2: システムの開発に要した期間と費用はどのくらいですか?
A2: 開発期間は[期間]、費用は[費用]です。これは、機械学習モデルの開発、データ収集・精緻化、システム構築、テスト、トレーニングプログラム作成などを含めた総費用です。
Q3: システムの精度をどのように保証していますか?また、予測の誤差が生じた場合、どのように対応しますか?
A3: 精度の保証については、過去のデータを用いた検証と、専門家によるレビューを徹底的に行っています。具体的には、MAPE15%以下、市場シェア予測誤差±5%以内、技術トレンド予測誤差±6ヶ月以内を目標としています。予測の誤差が生じた場合は、原因分析を行い、モデルの再学習やデータ補正を行うことで、継続的に精度向上を目指します。また、ユーザーからのフィードバックも積極的に収集し、モデル改善に反映していきます。
Q4: データのセキュリティとプライバシー保護については、どのような対策を講じていますか?
A4: データセキュリティとプライバシー保護は、最優先事項として取り組んでいます。厳格なアクセス制御、データ暗号化、不正アクセス検知システムなどを導入し、データの安全性を確保しています。また、個人情報保護に関する法令・規制を遵守し、適切な管理体制を構築しています。
Q5: ERPシステムとの連携について教えてください。
A5: 本システムは、既存のERPシステムと連携することで、より効率的な情報活用を可能にします。ERPシステムから取得したデータを本システムに取り込むことで、より精度の高い予測を実現します。また、本システムの予測結果をERPシステムにフィードバックすることで、計画立案や経営判断の精度向上に貢献します。
連絡先:
[企業名] 広報部
[電話番号]
[メールアドレス]
■ユーザフィードバックこのプレスリリース資料を上記の10人のペルソナに見せたときのフィードバックを、自分事として想像してみます。
佐藤健太郎さん(48歳、開発部門シニアマネージャー):
分かりやすさ: 全体的に分かりやすいが、具体的な数値目標(開発期間20%短縮など)は評価できるものの、その根拠となるデータや事例が不足しているため、少し懐疑的。MAPEや予測誤差の数値は、専門用語なので、もう少し噛み砕いた説明が必要。
期待: 開発遅延に悩んでいるので、開発期間短縮は魅力的。しかし、本当に効果があるのか、導入コストや運用コスト、リスクについても詳しく知りたい。保守的な性格なので、導入への決断には慎重になるだろう。
ダメなところ: 「最新ERPシステム導入による投資対効果の最大化」という文言は、彼の立場からすると、既にERPシステムを導入済みである可能性が高く、無関係な情報として捉えかねない。彼の悩みを直接的に解決する内容(開発遅延解消)をもっと前面に出すべき。
田中美咲さん(25歳、製造部門生産技術者):
分かりやすさ: 最新技術を使ったシステムという点で興味を持つだろうが、機能説明が専門用語が多く、具体例が少ないため、ピンとこない部分もあるかもしれない。
期待: 新しい技術に触れられることに魅力を感じる。ダッシュボードによる可視化やリアルタイムデータ分析は、彼女のような若手にとって魅力的なポイント。
ダメなところ: 彼女のような若い世代は、具体的な業務改善へのインパクトを明確に示してもらわないと、興味を持続できない。単なる機能羅列ではなく、具体的な業務フローへの影響を説明すべき。
鈴木一郎さん(60歳、研究開発部門上級研究員):
分かりやすさ: 技術的な内容を理解できるが、具体的なアルゴリズムやデータソースについての説明が不足しているため、精度への信頼感が低い。
期待: 長年の経験から、数値目標の達成可能性に疑問を持つ可能性が高い。過去の成功事例や類似システムの導入効果などを示す必要がある。
ダメなところ: 彼の年齢層には、システム導入による業務効率化よりも、自身の研究成果の継承や後進育成への貢献を強調する方が効果的。
残りのペルソナ(渡辺さん、山田さん、吉田さん、加藤さん、森下さん、高橋さん、小林さん):
それぞれの役割と立場によって、関心の度合いと着眼点が異なります。例えば、人事部(渡辺さん、小林さん)は人材育成プログラムに、財務部(森下さん)はコストやROIに、営業部(山田さん)は顧客へのメリットに注目するでしょう。
全体的なフィードバック:
ペルソナへの訴求力の低さ: プレスリリース全体として、各ペルソナのニーズや課題に的確に答えているとは言えない。各ペルソナの抱える問題を明確に理解し、その解決策としてシステムを提示する必要がある。
抽象的な表現が多い: 「迅速な対応」「精度の高い予測」「最適な開発計画」など、抽象的な表現が多すぎる。具体的な数値データや事例、導入による具体的なメリットを提示することで説得力を高めるべき。
ベネフィットの明確化不足: システムの導入によって得られる具体的なメリット(コスト削減、売上向上など)を、定量的に示す必要がある。
ビジュアル要素の欠如: プレスリリースは文章のみなので、図表などを活用して、システムの機能や効果を分かりやすく伝えるべき。
結論として、現状のプレスリリース資料では、多くのペルソナにとって十分な魅力を伝えきれていないと考えられます。各ペルソナの立場に立って、具体的な数値データや事例を交え、彼らの課題解決にどのように貢献できるのかを明確に示すことで、より説得力のある資料になるでしょう。 特に、佐藤さんや鈴木さんといったキーマン層への訴求が弱いため、彼らの懸念点を解消する情報提供が重要です。
以上、Difyデビュー戦でした。ChatGPT PlusにAPI利用料が含まれれば使いやすいんですけどね。