
BitTransformer界隈に激震!ついに使える乗算フリーLLMが登場!?

今年の3月ごろに話題になって、それから僕も実験してみたけどさっぱり学習できないBitTransformerに変わり、新たにMutmulFreeTransformerというものが出てきたようだと、NOGUCHI, Shojiさんが教えてくれたので試してみた
LLM 1Bパラメータで行列計算を完全に排除できた(らしい)。メモリ消費量を学習時10倍、推論時61%Max削減(らしい)。https://t.co/tB3x1kmo4Fhttps://t.co/pb0YgAKSpw
— NOGUCHI, Shoji (@noguchis) June 26, 2024
HFにモデルがアップロードされているので試してみよう。
学習は8x H100で370M:5h、1.3B: 84h、2.7B: 173hらしく1x 4090は厳しい
ただ、2.7Bモデルが量子化なしで4090で推論できてるとしたらそれだけですごい(というかMutMulFree自体が一種の量子化なのだが)。
僕も試してみた。
まず、conda環境を作ってインストールする。多少罠があるので補足
CUDA11.8とPytorch2を使用
$ conda create -n matmulfree python=3.10
$ conda activate matmulfree
$ conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c
nvidia
$ pip install packaging
$ pip install -U git+https://github.com/ridgerchu/matmulfreellm
$ pythonそしてPythonのREPLにて
>>> import os
>>> os.environ["TOKENIZERS_PARALLELISM"] = "false"
>>> import mmfreelm
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> name='ridger/MMfreeLM-2.7B'
>>> tokenizer = AutoTokenizer.from_pretrained(name)
tokenizer_config.json: 100%|████████████████████████| 967/967 [00:00<00:00, 3.54MB/s]
tokenizer.model: 100%|████████████████████████████| 493k/493k [00:00<00:00, 1.84MB/s]
tokenizer.json: 100%|███████████████████████████| 1.80M/1.80M [00:00<00:00, 4.25MB/s]
special_tokens_map.json: 100%|██████████████████████| 414/414 [00:00<00:00, 1.59MB/s]
>>> model = AutoModelForCausalLM.from_pretrained(name).cuda().half()
model.safetensors.index.json: 100%|████████| 38.7k/38.7k [00:00<00:00, 1.57MB/s]
model-00001-of-00002.safetensors: 100%|████| 4.98G/4.98G [11:27<00:00, 7.24MB/s]
model-00002-of-00002.safetensors: 100%|██████| 429M/429M [00:13<00:00, 32.2MB/s]
Downloading shards: 100%|████████████████████████| 2/2 [11:41<00:00, 350.98s/it]
Loading checkpoint shards: 100%|██████████████████| 2/2 [00:01<00:00, 1.53it/s]
generation_config.json: 100%|███████████████████| 111/111 [00:00<00:00, 801kB/s]
>>> def q(input_prompt):
... input_ids = tokenizer(input_prompt, return_tensors="pt").input_ids.cuda()
... outputs = model.generate(input_ids, max_length=32, do_sample=True, repetition_penalty=5.0,
... top_p=0.4, temperature=0.6)
... print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
...
>>> これで準備完了。念の為、コピペ用にq関数だけ抜き出したものを次に書いておく
def q(input_prompt):
input_ids = tokenizer(input_prompt, return_tensors="pt").input_ids.cuda()
outputs = model.generate(input_ids, max_length=32, do_sample=True, repetition_penalty=5.0,
top_p=0.4, temperature=0.6)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])これでREPLからこのMutMulFreeTransformerを直接使うことができる。InstructionモデルではなくCompletionモデルなので、「質問」ではなく「文章の書き出し」を指示することに注意
>>> q("A Mt. Fuji is")
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your
input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:2 for open-end generation.
A Mt. Fuji is a mountain in Japan that has been an important symbol of the country for centuries, as it was on this very spot
where 富士山について正しい知識を持っていそうなことが確認できた。
この時点で使用しているVRAMは10GBちょい
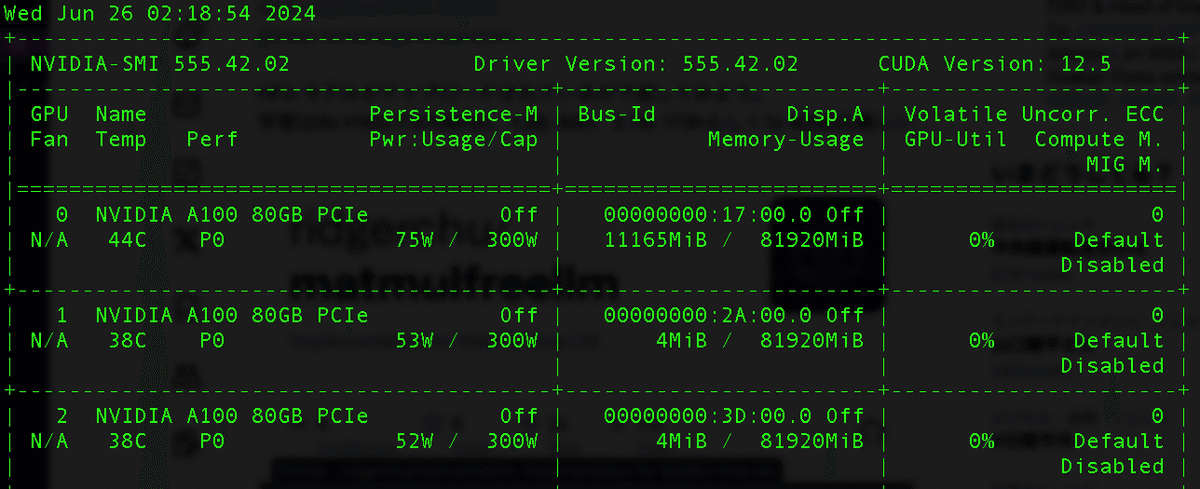
ということは、もっと小さいVRAM、例えば3060とかでも(VRAM12GB以上なら)推論できる可能性あるし、A100 40GBや80GB一枚でもファインチューニングできる可能性が出てくる。何よりフットプリントが小さく、しかも量子化によって性能が劣化しないので、もしも全ての話が本当だとすれば、かなり画期的なものとなる。
元の論文もなかなか読み応えがあるのでおすすめ


