No.013 映画Review "ブレットトレイン"

1.はじめに
先日ブラッド・ピット主演のブレットトレインという映画を見てきました。
歳のせいか、感想を自分でアウトプットしないと、数か月後には見たことすら忘れてしまいます。
私自身映画を見ること自体は好きですが、そもそも何も考えずに頭を空っぽにして見ているので、とても評論など書けません。
というわけで、pythonで口コミをウェブスクレイビングして、共感をえている口コミを参考してみようと考えました。
2.リファレンス
スクレイビングに関しては下記のサイトを参考にしました。
機械学習を使って東京23区のお買い得賃貸物件を探してみた 〜スクレイピング編〜 - データで見る世界 (analyze-world.com)
3.Python (Jupytor Notebook使用)
必要なライブラリを読み込みます。
from bs4 import BeautifulSoup
import urllib
import pandas as pd
import requests
import time
import math文字列の操作のため excelでいうright関数を定義しました。指定したTextの右からn番目までを抜き出す関数です。
def right(text, n):
return text[-n:]ブラッドトレインの口コミは下記のレビューサイトから抜き出しました。
html = requests.get('https://eiga.com/movie/96766/review/')
soup = BeautifulSoup(html.content,'html.parser')ブラッドトレインの口コミは下記のレビューサイトから抜き出しました。
サイトの構成ですが、レビューは1ページにつき20件並んでいるようです。
urlは 21-40件目のレビューは、all/2, 41件目-60件目のレビューは all/3と、規則的な数字がurlの末尾につくようです。
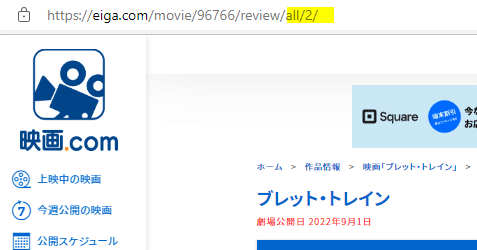
またグーグルクロームの検証を使ってコードを見るとdiv class = "user-review-inner"のなかにいろいろ情報が入っているようです。
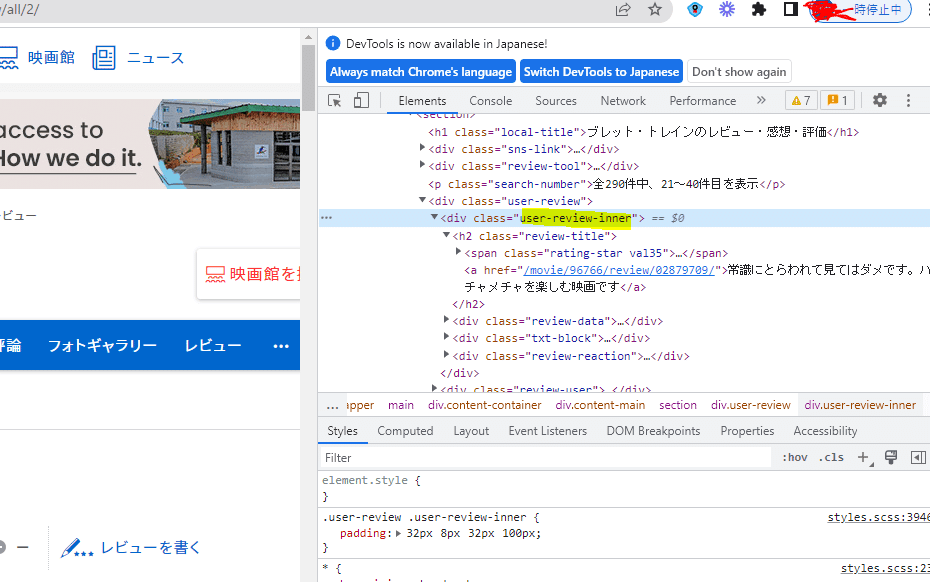
soup.find.allで'use-review-inner'を指定してデータをとりreviewsに格納
len(reviews)で数を見てみると20とでてきました。1ページあたりのレビュー数は20と確認できました。
reviews = soup.find_all("div",{'class':'user-review-inner'})
# soup.find_all("tag", {'option':オプションの内容})で、<tag option="オプションの内容">内容</tag>で囲まれたものの中身が取り出せる。リストとして。
#つまり、<div class="user-review-inner">個別のreviewの情報</div>に対して、soup.find_all("div", {'class':user-review-inner})で個別reviewの情報を得られる。
print("1ページのreview数は" + str(len(reviews))) # reviewsは個別情報のリスト。長さがわかれば、位置ページに含まれる物件数がわかる。
print(reviews[0]) #1つめのReview情報
次にTotalのReview数を抜き出します。
サイト自体からは全290件という事がわかっています。1ページ当たり20件のReviewがあるので、合計15ページ分のReviewがあることになります。


しかし、レビュー数自体は、投稿によりどんどん増えてきますので、Totalのページ数をpythonで把握できるようにしたほうが便利です。
#tmp
タグを調べたところ総数は"total-number icon-after arrowopen"に含まれていることがわかりましたので、この部分を抜き出してtmpに格納
#tmp2
str(tmp[0])でテキストにしてtmp2に返します。
#tmp3
テキストにはいろいろなタグが記述されていますが、'<span class="total-number icon-after arrowopen">全<span>'(文中にダブルクォーテーションがあるので、シングルクォーテーションで囲む)のあとにreview数の総数が記述されていることがわかりました。replaceでこのタグを空白("")に置き換えtmp3に返します。
#tmp4
残っているタグ"</span>件</span>"を空白("")に置き換えtmp4に返します。
この時点でtmp4は 文字型でReview総数(290件)が入っています。
#tmp5
1ページあたり20件なので、290/20で数字をだし
#page_num
切り上げで15という数字をが格納できました。
tmp = soup.find_all("span",{'class':'total-number icon-after arrowopen'})
tmp2 = str(tmp[0])
tmp3 = tmp2.replace('<span class="total-number icon-after arrowopen">全<span>',"")
tmp4 = tmp3.replace("</span>件</span>","")
tmp5 = int(tmp4)/len(reviews)
page_num = math.ceil(tmp5)
page_num
スクレイビングをするためのurlのリストをつくります。
urlsという変数に格納しました。
url = 'https://eiga.com/movie/96766/review/'
urls = [] # からのリスト
urls.append(url) #1ページ目(手作業でゲットしたもの)を記録
#2ページ目から最後のページまでを格納
for i in range(page_num-1):
pg = str(i+2)
url_page = url + 'all/' + pg
# リスト.append(中身)で、リストに中身が追加されます。
urls.append(url_page) # list.append(追加分)するとlistに追加分が追加される
print(url)
# 見てみる
print(type(urls))
urls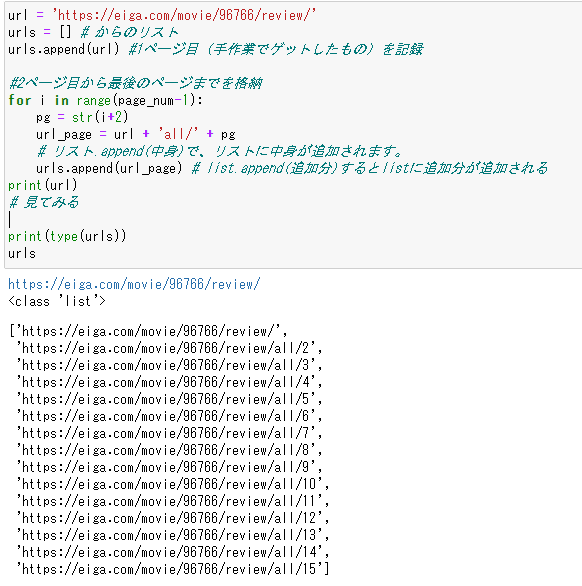
今回はreviewのタイトルと本文、得点、本文に共感した人数をデータにすることにしました。大変な作業でしたが、基本はそのタグを探し出して抜き出したものを、テキストにして、不要なタグを空白にリプレースしたり、splitしたりして、頑張って必要な情報をそれぞれの空のリストにappendしていきます。
title = []
text = []
rating = []
empathy = []
for url in urls: # 各ページ(URLに対して)
result = requests.get(url) # urlから情報をとってくる
c = result.content # htmlの中身だけを取り出す。
soup = BeautifulSoup(c, "html.parser") # htmlの中身が取り出しやすいよう要素を抽出
reviews = soup.find_all("div",{'class':'user-review-inner'}) # 各ページの個別情報をリストとして取り出す
for i in range(len(reviews)):#Reviewの長さ20件分くりかえす。
tmp = reviews[i].find_all("h2",{'class':'review-title'}) #タイトルがふくまれている記述の切り出し
tmp = str(tmp[0])
tmp = tmp.split('/">')
tmp = tmp[1]
tmp = tmp.replace("</a> </h2>","")
title.append(tmp)
for i in range(len(reviews)):
tmp = reviews[i].find_all("div",{'class':'txt-block'})#Review本文がふくまれている記述の切り出し
tmp = str(tmp[0])
tmp = tmp.replace('<div class="txt-block"> <p>',"")
tmp = tmp.replace('</p> </div>',"")
tmp = tmp.replace('<br/>',"")
tmp = tmp.replace('<div class="txt-block"> <p class="short">',"")
tmp = tmp.replace('<div class="txt-block"> <div class="toggle-btn"> <span class="netabare-mark icon hand">ネタバレ!</span> <span class="icon-after arrowopen">クリックして本文を読む</span> </div> <p class="hidden">',"")
text.append(tmp)
for i in range(len(reviews)):
tmp = reviews[i].find_all("span", class_ = ["rating-star val50",
"rating-star val45",
"rating-star val40",
"rating-star val35",
"rating-star val30",
"rating-star val25",
"rating-star val20",
"rating-star val15",
"rating-star val10",
"rating-star val05",
"rating-star val00",
])#Review得点がふくまれている記述の切り出し
tmp = str(tmp[0]) #文字型にして
tmp = tmp.replace("</span>","")
tmp = right(tmp,3)
rating.append(tmp)
for i in range(len(reviews)):
tmp = reviews[i].find_all("div",{'class':'empathy'}) # 共感した数の切り出し
tmp = str(tmp[0])
tmp = tmp.split('<span class="number">(共感した人 <strong>')
tmp = tmp[1]
tmp = tmp.replace('</strong> 件)</span> </div>',"")
tmp = int(tmp)
empathy.append(tmp)無事に動いたのでDataframeに格納します。
df=pd.DataFrame({
"レーティング":rating,
"タイトル":title,
"テキスト":text,
"共感した数": empathy
})290件無事に格納できました!

レーティングがobject型になっていたので、int型に変更してみようと思います。一応値を確認してみると… なんと1件変な値が入ってます。

188番目のやつです。webサイトでも確認してみます。

実際にレーティングがされてなかったです(泣)…

内容的にボロカスに書かれているわけではないので、0点という事ではなさそう。とりあえず3点に置き換えます。

float型に置き換えて、describe()でみてみます。

最後にCSVに書き出し。そのまま書き込もうとするとshift-jisで読めない文字がエラーになってしまい書き込めないのですが、errors='ignore'とすると無視して書き込んでくれます。
df.to_csv('kuchikomi.csv',encoding = "cp932", errors='ignore')

以上です。大変でしたが、次回から映画の口コミの確認が簡単になりました。