
iOS Accelerateでボイチェン高速化に挑戦したインターン学生の話

[Abstract] iOSのAccelerate Frameworkで汎用FFTライブラリに比較してグッと高速なボイチェン(実時間係数<1.0)試作したのですが、日本語での情報がほとんどなかったので共有します。実装上(1)vDSP_fft_zripD()内部で行われているスケーリング, (2)Appleのドキュメントにあるトラップ, (3)vDSPデータパッキングに注意が必要でした。
REALITY株式会社でのエンジニアリングを中心にお送りしているこのブログですが、REALITY株式会社には REALITY を作っているプラットフォーム事業と、REALITY XR Cloudなどのソリューション事業やVTuberプロダクション・XRライブを開発するXR Entertainment事業、そして研究開発部門として GREE VR Studio Laboratory が存在します。

今回のエンジニアブログは GREE VR Studio Laboratory (以下VR Studio Lab)の白井暁彦ディレクターとインターンとして活動している堀部貴紀さんでお送りします。

こんにちわ!堀部です。明治大学先端メディアサイエンス学科(FMS)の4年生です。VR Studio Labでは音声の基盤技術の研究をお手伝いさせていただいてます。皆さんに遊んでもらえる技術としては『転声こえうらない』が実験サービスとして公開されています。
このサービスは主にGoogle Cloud Platform(GCP)上に実装された音声分析合成システムWORLDで構築された声質変換エンジンとVueで書かれたフロントエンドで書かれていますが、今回はVR Studio Labのリサーチとして、この声質変換をiOSでリアルタイム化する挑戦をがんばってみました。
【社内ビルドによるiPhone実機demo(2021/2/10)】
GCP版はrealworldというエンジンでグリー開発本部の石原さんが開発されておりますMac/Linux/gcc版です(石原さんの機械学習ベースの任意話者変換技術についてはこちら)。またWORLDについては指導教員の森勢将雅先生のWORLDを軽く紹介しながら、ここで実装した際に格闘した高速フーリエ変換(FFT)のお話を中心に紹介させていただきます。
音声分析変換合成システムWORLD
【公式HP より】WORLDは、Vocoderのアイディアを発展させた音声分析変換合成システムです。発達した計算機能力を駆使し、高品質で柔軟な音声分析・変換・合成の実時間処理を目的としています。UTAUの合成エンジン、また音声創作ソフトウェアCeVIOの音声分析の一部にもWORLDが使われています。
【音声符号化 - Wikipedia より】分析合成符号化、あるいはボコーダー(vocoder, voice coderの略)とは、人間の声のモデルを元に信号を分析してパラメータ化し符号化を行う方式で、復号時には、音声の波形ではなく聴感上同じ音声に聞こえるように再合成を行う。
「恋声」などのソフトウェアボイスチェンジャー、「VT-4」などのハードウェア機器でも似たような同様の処理を行いますが、Vocoderは入力された音から取り出した音声パラメータに対して、pitch(声の高さ)とformant(声の特徴)の2つを用いて、目的の声に変換して合成します。
ちょうど、母音と同じ音が出るピアノの鍵盤を構えて声を聞きながら、聞いた声に近いキーを押していく感じです(子音は異なる分析手法が必要です)。
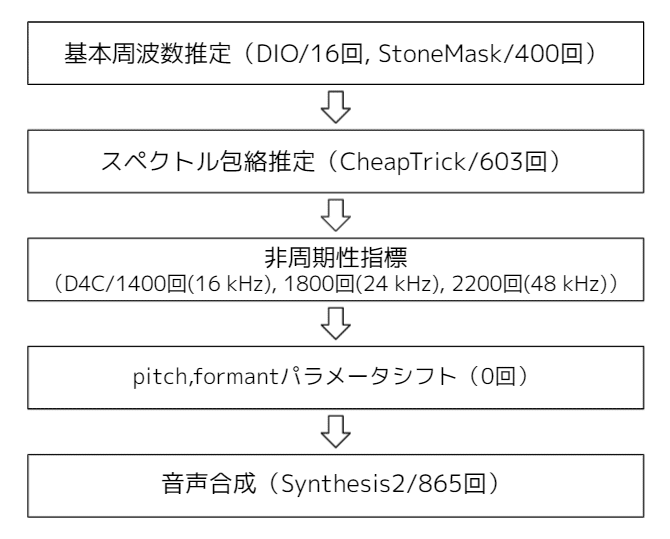
簡単にステップを紹介すると上図のような感じです(一例です。実際の実装とは異なる場合があります)。これらの一連の過程において、波形を周波数で分析する必要が生まれるので高速フーリエ変換(FFT)はめっちゃ使います。だいたい1秒間に数千回のFFT関数が呼ばれます。
AppleのAccelerate Frameworkを使う
そこで今回は、元祖WORLDのC++ソースコードで書かれた汎用FFT関数(ooura FFT)をAppleが提供するSwiftのAccelerate のAPI vDSP_fft_zripD() を中心に置き換えて、改善(高速化・高性能化・低消費電力化)を検討しました。
【補足】
Accelerate FrameworkはAppleが提供している大規模な数学的計算や画像処理を、高性能かつ低消費電力に最適化して行うライブラリです。iOS 4.0+, macOS 10.3+, Mac Catalyst 13.0+, tvOS 9.0+, watchOS 2.0+で動作します。コード内部の数学がどうなっているか?各プラットフォームのハードウェア内部でどのような動作をしているか?は公開されていないので開発者が調べる必要があります。
結論からいうと、汎用FFTライブラリに比較してグッと速くなりました(実時間係数<1.0)。「どれぐらい速くなったのか?」については機会があればまた発表したいと思いますが、今回は実装上で気をつける以下の3点について、日本語での情報がほとんどなかったので、共有したいと思います。
・vDSP_fft_zripD()内部で行われているスケーリングについて
・Appleのドキュメントにあるトラップ
・vDSPデータパッキング
FFTの算数をふりかえり
FFTを(数学を難しく説明しないで)簡潔に説明すると、「時系列に並んだ音声データを周波数成分の配列に変換する手法」といえます。FFT関数は音声に各周波数の成分がどれくらい多く含まれているか?を調べてもらえればいいのです。Accelerate FrameworkでのFFT計算式は、以下のとおりです。
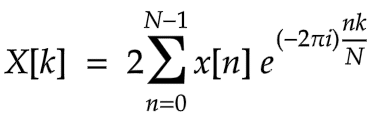
いたって普通のフーリエ変換ですが、なぜかΣの前に2があるのです。
Appleのドキュメントにあるトラップ
フーリエ変換といっても各FFT関数によって正規化されていたり、生値だったりで注意が必要ですが、vDSP_fft_zripD() では、一般的なフーリエ変換式に2倍された値が出力されます。公式の Data Packing for Fourier Transforms によると
[引用] To provide the best execution performance, vDSP’s Fourier routines don’t scale transform results.
とあります。参考までにDeepLで翻訳すると「最高の実行性能を提供するために、vDSPのフーリエ・ルーチンは変換結果をスケーリングしません」と翻訳されますが、え…ちょっとまって…2倍されてるじゃないですか…。つまり「vDSPでは、最高の性能を実現するために2倍がそのままになっている」と解釈したほうが良いようです(様々な実験による忖度)。
[注意] Using Fourier Transforms も公式のドキュメントで、スケーリングに関して同じように言及されていますが、最終更新が2015年な上にvDSPの仕様がいくつか変わっているため注意が必要です。
そして..."Accelerate"と名付けられていますが、より速くなるという保証はありません。大規模な数学的計算や画像処理を、高性能かつ低消費電力に最適化して行うライブラリです。Appleの中の人もいろいろあるんでしょうね…。
vDSPのデータパッキング
さて Accelerate Frameworkとその下のvDSP系のAPIには音声配列をそのまま渡しても正しく動作しません。実際にはエラーも出ずに通ってしまうのですが、実行してみると何だかプツプツ音が鳴っているだけで正しく分析も変換もされません。
vDSPについてはちょっと癖のあるデータパッキングが必要なようです。公式のData Packing for Fourier Transforms に、以下のように説明があります。
The result of a forward Fourier transform on n real values is n complex values:
- Complex element 0 contains the DC component (equal to the sum of the time domain values) in its real part and zero in its imaginary part.
- Complex elements 1 through n/2 contain the complex frequency-domain values.
- Complex element n/2 + 1 contains the Nyquist component (the cosine component coefficient at the Nyquist frequency) in its real part and zero in its imaginary part.
- The remaining complex elements contain the complex conjugates of the complex frequency-domain values.
参考までにDeePL翻訳です。
n個の実数値を前方フーリエ変換した結果は、n個の複素数値となる。
- 複素数要素0には,実数部にDC成分(時間領域の値の合計に等しい),虚数部にゼロが含まれる。
- 複素数要素1〜n/2には,周波数領域の複素数値が含まれる。
- 複素数要素n/2+1には,ナイキスト成分(ナイキスト周波数における余弦成分の係数)が実数部に,虚数部に0が含まれる。
- 残りの複素数要素には,複素数周波数領域の値の複素共役が含まれています。
わけがわかりませんので公式のData Packing for Fourier Transforms に加えて 日本語で補足説明すると、以下のとおりです。

DC component(DC成分)は先ほどの計算式におけるk=0のとき結果、Nyquist component(ナイキスト成分)はk=N/2の結果を指しています。通常、FFT計算結果は複素数値になりますが、k=0, N/2のときだけ実数値になります。
これは、複素数値は2つの実数の組で表現されるため、2倍のメモリを必要とするところ、k=0, N/2では半分のメモリで済むことを意味しています。これを利用して、この関数では、k=0の虚数部にk=N/2の実数値を格納することでメモリを節約しているということですね!また計算過程において、要素N/2+2~Nに要素1~N/2の複素共役成分が発生します。これらは符号+/-が反対になっているだけで、どちらかがあれば復元可能なので省略しているようです。
実装例
入力配列は、Split-Complex型と呼ばれる実数部と虚数部が別々の配列になっている形式である必要があります。1次配列をSplit-Complex型配列に変換してくれる関数が、vDSP_ctozDです。以下の実装例はデータがDouble型のときのコードです。Float型のときは、関数名の語尾に"D"がないものを使ってください。
// in: 入力配列
// doublesplitcomplex: 出力配列
// n: 入力配列の長さ
vDSP_ctozD((DOUBLE_COMPLEX*)in, 2, &doublesplitcomplex, 1, n/2);
// FFT
vDSP_fft_zripD(fftsetupD, &doublesplitcomplex, 1, log2n, FFT_FORWARD);
// scaling
double scale = 1.0/2.0;
vDSP_vsmulD(doublesplitcomplex.realp, 1, &scale, doublesplitcomplex.realp, 1, n/2);
vDSP_vsmulD(doublesplitcomplex.imagp, 1, &scale, doublesplitcomplex.imagp, 1, n/2);今回のWORLDを使ったボイチェンでは、最後に2次元配列に要素列を考えてiOSのAVAudioPCMBufferに渡す処理を加えます。
// c_out: FFT計算後の出力2次元配列
c_out[0][0] = doublesplitcomplex.realp[0]; // DC component
c_out[0][1] = 0.0;
for(int i=1; i<n/2; i++) {
c_out[i][0] = doublesplitcomplex.realp[i];
c_out[i][1] = doublesplitcomplex.imagp[i];
c_out[i+p.n/2][0] = 0.0; // complex conjugate
c_out[i+p.n/2][1] = 0.0;
}
c_out[p.n/2][0] = doublesplitcomplex.imagp[0]; // Nyquist component
c_out[p.n/2][1] = 0.0;苦労したこと
実はこのプロジェクトはコロナ禍の2020年8月ごろから開始していましたが、ゼロからリモートオフィス中心でSwiftを勉強しながら、実装だけでなくベンチマークデータの取得や論文化なども含めると、1年近くかかってしまいました。
iOSやAndroidなどで音声配信サービスは人気ですが、iOSでの音声処理の最適化に特化したドキュメントは少なく、英語の公式ドキュメントを自分の知識と照らし合わせたり、C++で書かれたWORLDとSwiftを連携させるBridging処理を漏れなく行うためにC++のビルドの仕組みやSwiftでのポインタの勉強をやり直す必要があったり…と紆余曲折しましたが、高速かつ技術的透明度の高い実装にたどり着くことができとても良い経験になりました。
今後:GREE VR Studio LaboratoryでのR&Dについて
以上、Accelerate FrameworkのFFTを使って高速化を検討したお話でした。なお、今回の実装を含めたWORLDでのFFT速度比較に関する内容は他のプラットフォームでのFFT関数のベンチマーク結果も含めて、2021年9月に開催される音響学会秋季研究会にて発表を予定しております。
GREE VR Studio Laboratoryでは先進的なXRユーザエクスペリエンスを未来のREALITYで実現すべく、上記のようなプロトタイプや実験サービス「転声こえうらない」を通した、ボイスチェンジャー利用者の声の特徴や利用環境の統計的分析など、基礎的な研究を行ってきました。以下に学術成果を紹介します。

・堀部貴紀(REALITY/明治大),白井暁彦(REALITY),森勢将雅(明治大),「『転声こえうらない』を通したボイスチェンジャー品質改善のための定性分析と考察」, 日本音響学会2021年春季研究発表会, [SlideShare] (2021/3/11)
・堀部 貴紀, 石原 達馬, 白井 暁彦, 森勢 将雅; 『転声こえうらない』利用者の基本周波数分析, 情報処理学会研究報告, [SlideShare] (2020/05/30)
まとめ・謝辞
以上でVR Studio Labの研究開発のようすを紹介いたしました。
ご支援・ご指導いただいた、明治大学の森勢先生、REALITY株式会社プラットフォームのmoritaさん、ションローさん、漫喫さん、開発本部の石原さん、橋本さん、それからDJRIO社長ありがとうございます。
こういうコアな技術と製品・サービス技術の両方に興味がある人は中途採用はREALITY株式会社(https://reality.inc/jobs/)、新卒はグリーグループ新卒採用にエントリーするとよいと思います。まだ新卒採用のタイミングじゃない人はアルバイト、コンピュータサイエンスや信号処理が出身なんだけど、今お勤めで担当している仕事が微妙だな…という方はREALITY株式会社窓口で業務委託でも採用募集していますので、迷わずエントリーしてみるといいと思います。モバイル、音声信号処理だけでなく、クラウド、通信、グラフィックスなど多岐に!垂直に!新しい仕事がありますよ!