
日々の壁打ち:ComfyUIのワークフローを工夫することは、ただの自己満足なのか、それとも意味があることなのか、視覚化出来る方法を考えてみた

最近のSDXLチェックポイントに、IllustriousXL系というものがある。
上のオリジナルのチェックポイント配布先の説明を見ると、以下のように書いてあり、イラストレーションの表現に特化したモデルであることがわかる。
Illustrious-XLは、包括的な Danbooru2023 データセットとそのバリエーションに基づいて微調整された強力な生成モデル シリーズです。データセットから派生したさまざまなキャラクター デザイン、スタイル、芸術的知識が含まれており、クリエイティブで芸術的な AI 生成タスクに適しています。
IllustriousXLは、『公正なパブリック AI ライセンスの下で v0.1 および v0.1-GUIDED モデルをリリースしていますが、収益化目的やクローズドソース目的でのモデルの使用は推奨されません』とあるように、ホビーユースや研究目的での使用が推奨されている(というか、多くの版権キャラを学習しているために、そこを突っ込まれることを避けるための予防線だろう)が、使ってみると、版権名タグやキャラタグに特化しているチェックポイントで、それらを避けたプロンプト指定をすると、極端に画質がさがるという特性を持っているのがずっと気になっていた。
例えば、普段自分は版権キャライラストを生成し、パブリックに掲示することは滅多にやらないが、IllustriousXLに「初音ミク(hatsune miku)」と指定してやれば、このぐらいの絵はすぐに出てくる。

しかしほぼ同じような生成条件で、本noteの看板娘を生成させてみても、せいぜいこの程度にしかならない。

まったく同じComfyUIワークフローを使い、AnimagineXLで生成した結果は以下である。

さすがにここまで差があると、ちょっと使う気にはなれない。周りの人に尋ねてみても、IllustriousXL系チェックポイントの画像生成はクオリティ管理が難しい、みたいな意見をいくつか聞いた。同時に「アレはファンアート用だから…」と言ってる人も結構いた。つまり版権タグやキャラクタータグ、アーティストタグを指定しないと使い物にならないということだ。もちろんあくまで自分の身の周りの話であるので、サンプルセレクションバイアスがあることは認めるが、そういう傾向があるのは事実だろう。
補足しておこう。上の2枚でIllustriousXLで生成した看板娘のほうを「ぶっちゃけ期待外れ」とは書いたが、この絵自体が格別に悪い訳ではない。あくまでここで「期待外れ」と書いたのは、普段自分が使っているプロンプトを別のモデルに用いたとしても、ある程度期待している絵が出てくるか、ということであって、それがズレているという話なだけである。だから「自分はIllustriousXLで生成した看板娘のほうが好みだな」という人がいても当然よい。
IllustriousXLの場合、版権タグ、キャラタグ、アーティストタグを用いると「商業的によく知られている」作風の絵が出やすいので、「敢えてそれを使わない」となると急に扱いが難しくなるということにすぎないのだろう。
ここのところ出てくるSDXL系チェックポイントには、何かに特化する代わりに何かの表現力が落ちる、という例は結構みかけるように思える。実際、IllustriousXLの派生モデルをいろいろとチェックしていて、特有の表現には強いが、その他になるとガクンと落ちるという例はいくつか経験した。
IllustriousXL系のカスタムチェックポイントがいくつか出てきたので、試してみたんだけど、キャラ単体だと悪くない出力が、背景も込みで指定すると、軒並み表現力が落ちることが気になって調べてみた。… pic.twitter.com/RcTGCfdsAX
— Nobu-Kobayashi (@nyaa_toraneko) October 14, 2024
その一方で、Latent Space(潜在空間)の特性を考えれば、高品質な絵から特徴量を学習しているならば、それらの学習結果のみをなんらかの方法で確率的に誘導できるのかもしれない。それも、版権タグやキャラクタータグ、アーティストタグを指定しないで、である。実際、上のAnimagineXLから生成された看板娘も、普通のDanbooruタグとはかなり違った独自傾向のプロンプトが使われている。これはどちらかというと、DALL-E 3由来のプロンプトをStable Diffusion向けにカスタマイズしていった結果として出来たもので、そこから学ぶことは沢山あった。
そこで、週末にかけてIllustriousXL系モデルからウチの看板娘を可愛く誘導する条件をComfyUIのワークフロー内の生成条件の見直しも込みで、再度探索してみた。その結果が以下である。

AnimagineXL系とは表現は違うが、十分可愛いしクオリティも高い。
結論から言うと、従来のAnimagineXL向けのセッティングとは、かなり違っていた上に、プロンプトの指定にもかなり癖があった。しかし一旦それがわかってしまえば、オリジナルキャラクターもかなりよいクオリティで出せるようである。
複数キャラのデザインシートを与えて集合写真をレイアウトするワークフローを作っていたら、結局ガールズグループのジャケイラストみたいなのがいい感じに生成できるようになりました。
— Nobu-Kobayashi (@nyaa_toraneko) November 9, 2024
この『グループとしての統一感はあるんだけど、個々はバラバラ』ってネタだしするにも難しいんですよね。… pic.twitter.com/LONVLOa6uT
そこで、アイドルグループっぽい集合イラストを生成するComfyUIワークフローにその条件を適用してみたら、AnimagineXLでの例よりもかなりよいものが生成できたので、いくつか紹介しよう。

その辺りを上手に処理できているのは、個人的にポイントが高い。

まるで『METHODS』みたいだwww

後ろのコの表情も凄くよい。
最終的にPhotoshopでカラーフィルタ調整をしているが、絵自体はほぼComfyUIからのポンだし状態である。IllustriousXL系チェックポイントから生成された画像は、ちょっとホワイトバランスを調整してやると、今風の凄く良い絵になるようだ。

イケイケである。
こんなことを実験しているうちに、ふと考えた。
『結果はともかくとして、このComfyUIでのワークフローは本当に効果的なのだろうか?』
というのも、これらの絵を生成したComfyUIワークフローでの、各段階のデノイズ処理の値をみていくと、かなり慎重に作画修正を入れるようなタイプの処理になっていたからだ。それは、ある意味、チェックポイントの性能に任せて、余計なことをしないということでもある。実際、IllustriousXL系チェックポイントにコントロールネットを重ねがけすると、どんどん絵がハイキーな感じに焼けていく経験をすることがある。
そこで、こんな実験をしてみた。
ComfyUIワークフローでの生成条件を、できる限りSD UI Forgeに渡してやって、同じような絵が生成できるのかのテストである。
まず以下の様なテストをおこなってみる。
事前に準備として、SD UI ForgeとComfyUIとの間で画像生成時のClipやノイズ発生仕様の違いを調整しておく必要はあるが、この両者で極めて近い絵が生成できるならば、投入するプロンプトやパラメタなどのセッテイングは、同じような効率でチェックポイントの能力を引き出しているといえそうである。

ComfyUIワークフローで生成した画像は以下である。

上のテスト方式でSD UI Forgeで生成した画像は以下である。

ぱっと見でわかるように、画像のモチーフはレイアウトも込みで極めて近い。投入したプロンプト等のセッティングは、ほぼIllustriusXL系チェックポイントから同様に性能を引き出しているとみていいようだ。だがよく見ると、SD UI Forgeで生成した画像のほうは中央と右側のキャラクターの身体のアナトミーが混ざってしまっている。
これは、元々のComfyUIのワークフローが、「生成された画像のよい点を活かしつつ、おかしな部分を加筆修正していく」というものだから、「AIによる作画監督機能が効いている」とみることもできるだろう。
個人的には、絵としての品質はComfyUIワークフローで生成しているほうが上だと思うが、単なる嗜好の問題という可能性はある。
そこでもうひとつ別のテストを加えてみよう。
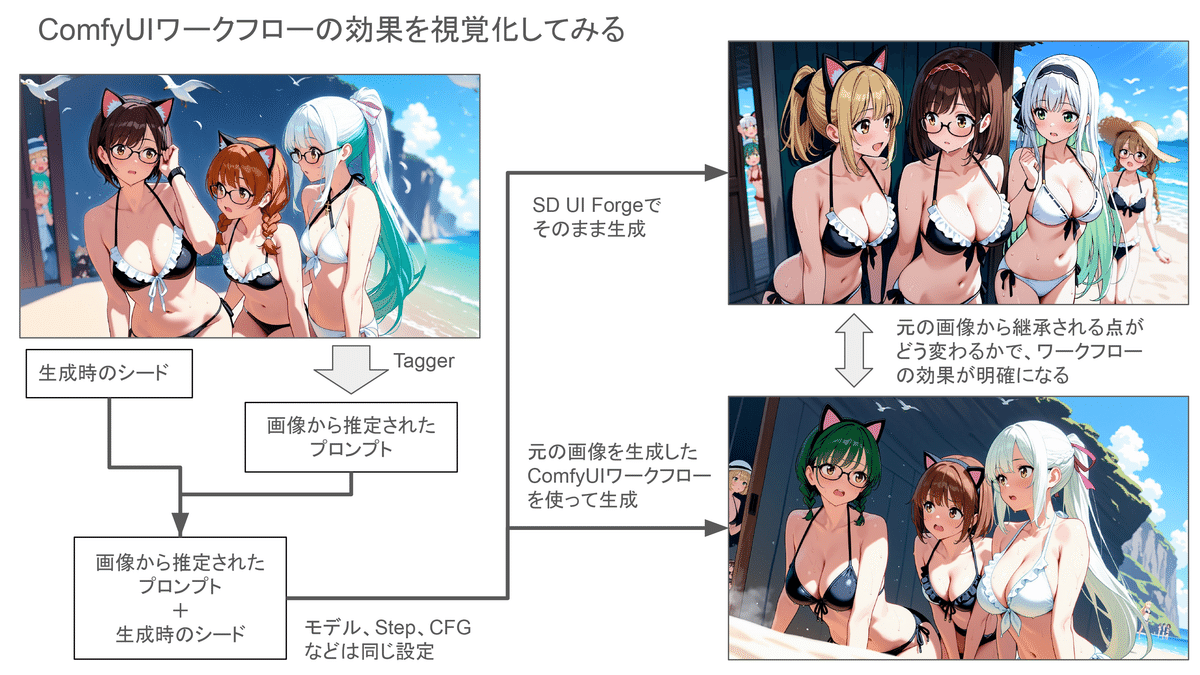
このテストは、元画像の生成時のシードのみを共通にした上で、プロンプトに関しては画像のルックから推定できるもののみとし、元画像を生成したComfyUIワークフローがどこまで元の絵を再現できるかチェックするものである。比較対象として、同一条件でSD UI Forgeにも画像生成させる。元の画像と2つの新規に生成された画像を比較することで、設計したComfyUIワークフローが設計時の仕様通りに動いているかを判断できる。
先に『アイドルグループっぽい集合イラストを生成するComfyUIワークフロー』と簡単に書いたが、そこでやっていることは、
画像生成ワークフロー内に、作画のイテレーション過程を作り上げることで、順次絵の品質をあげていくこと。
複数のキャラクターのレイアウトを効率的かつ効果的に実現できること。
の2点である。
テストの結果は以下の様になった。まずSD UI Forgeで生成した画像からみていこう。

この通り、同じシードを与えてやっても、まったくレイアウトやモチーフ、シチュエーションが違う絵が生成されてしまう。ちょっと気になるのは、手前三人のヒロインの体形が皆、同じに見えることだ。元画像から推定されたプロンプトでは、ヒロインの身体的な特徴の描き分けは難しいのかもしれない。あとヒロインの描写のタイプがかなりズレているようだ。ぶっちゃけ、美少女ゲームメーカー間のブランド違いみたいな感じのズレではあるが、美少女イラスト分野的な文脈では、「キャラが違う」と指摘される可能性はあるだろう。
続いて、元画像を生成したComfyUIワークフローに、その画像自身から推定されたプロンプトを差し込んで生成してみた結果である。

こちらは一見してわかるとおり、元絵の再現度はかなり高い。特に手前の三人のキャラクターは、かなり元絵のイメージに近く、身長差なども再現できている。
このことから、「複数のキャラクターのレイアウトを効率的かつ効果的に実現できる」ということを通じて、同時にキャラクターの描き分けをある程度実現できていると言ってもいいのかもしれない。
IllustriousXL系チェックポイントから生成されるイラスト群は、カラーに関してはPhotoshopで一度処理したほうがよいように思えるが、そこで一手間かけてやるだけで、相当いい感じの絵に仕上がるようだ。とにかくヒロイン達の表情が良いのは、使っていて楽しいと思える。
版権タグやキャラタグ、アーティストタグを一切使わないとなると、イラスト生成のセッティングが急に難しくなるのがちょっと辛いところだが、そこさえ乗り越えれば、オリジナルキャラクターの魅力を引き出す目的に使うのにも十分以上に使えるだけの性能があることがわかったのが、大きな収穫だったと思う。少なくともアナトミーで極端に酷いものが生成されないのは、使い方によっては面白いものになりそうだ。
以上のテストをもって、自分的には今回作成したIllustriousXL向けワークフローは十分使えるものと評価することにした。要は、「ええもん作ってみました」という自慢話にすぎないが、こんな長文をここまで付き合ってくださった皆様には感謝の一言を込めて、ウチの看板娘のとっておきのショットを贈らせていただきたい。
