【Python初心者による業務効率化】自然言語処理モデル(BERT)の活用

はじめに
このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています。
自己紹介
私は某コンサルティングファームでアシスタントとして働きながら、データサイエンティストを目指す1児の新米ママです。
Python初心者ではありますが、実務にどのように活かせるのかをアウトプットを通して学習し、日々の業務効率化を目指しています。
本記事の概要
👇どんな人に読んでほしいか
Python初心者で、自然言語処理(NLP)や学習モデルBERTを使って業務効率化に挑戦したい人
👇この記事で分かること
Pythonを使った自然言語処理の基本や、BERTモデルを使ってテキストデータを分析する方法、具体的な業務での効率化例を紹介しています。
実際のプロジェクトでの悩み
今回は、最近仕事の中で感じた課題に対して、自然言語処理モデル(BERT)を活用した解決方法を検証してみます。
あるプロジェクトにおいて、ITSMツールのJiraを用いたプロジェクト管理を行っていました。
ITSM(ITサービスマネジメント)は、会社のITシステムを管理して、問題が起きないようにしたり、起きた問題を早く解決したりするための手法です。
規模の大きな会社では、一般的に、ITIL(アイティル)という国際基準を満たす必要があります。なぜなら、世界中で同じ基準を守ることで、IT活用におけるトラブルが少なくなり、他の会社とも一緒に仕事がしやすくなるからです。
JSM(Jira Service Management)は、ITILの管理基準を満たしながら、ITチームが効率よくユーザーサポートや問題解決をするために使用されるITSMツールです。
ITSM(IT Service Management)ツールとは、
ITサービスの計画、提供、運用、制御を効率的に管理するためのソフトウェアのことを指します。
これらのツールは、国際的な管理基準であるITIL(Information Technology Infrastructure Library)フレームに基づいたベストプラクティスをサポートし、インシデント管理・問題管理・変更管理・資産管理といったさまざまなプロセスを自動化・標準化します。
Jiraはもともとプロジェクト管理ツールとして開発されましたが、Jira Service Managementを使用することで、ITSMツールとしての機能を持つようになります。
Jira Service Managementは、インシデント管理、サービスリクエスト管理、問題管理、変更管理など、ITSMの基本機能を提供しています。
What is ITSM? A guide to IT service management | Atlassian
JSM(Jira Service Management)を用いたプロジェクト管理
こうしてJiraを活用し、インシデント管理などに取り組む中で、重複するチケットの問題に直面しました。
大規模且つ複雑なITプラットフォームの開発運用においては、現場のメンバーが日々の業務に追われ、同じ問題に関する複数のチケットが登録されてしまうことがあります。
今回はこの課題に対処するため、BERT(Bidirectional Encoder Representations from Transformers)を活用し、類似したチケットを自動的に抽出するアプローチを試みました。
自然言語処理モデル(BERT)の活用
準備
今回の作業は、Google Colab上で行います。
まずはじめに、KaggleのDatasetsよりJiraのインシデントレポートをインストールします。
今回は下記の公開データを使用しました。
Jira Issue Reports v1 (kaggle.com)
次に、MyDrive上にデータをアップロードし、Google Colab上にMyDriveをマウントします。
from google.colab import drive
drive.mount('/content/drive')Google Colab上に今回使用するデータをインストールします。
import pandas as pd
base_path = '/content/drive/MyDrive/'
zip_path = 'jira_issues.csv.zip'
df = pd.read_csv(base_path + zip_path)
df.head()今回はGoogle Colabを使用するため、容量が大きすぎるデータを圧縮し作業します。
df.shape
(701002, 18)df = df.iloc[:10]
df.shape
(10, 18)データの圧縮に成功しました。
今回の作業に必要なライブラリを使えるようにします。
!pip install transformers
!pip install sentence_transformers
!pip install fugashi[unidic-lite]
!pip install ipadic次にライブラリのインポートを行い、
from transformers import BertJapaneseTokenizer, BertModel
from sentence_transformers import SentenceTransformer
from sentence_transformers import models
import torch
import numpy as nphugging face上で公開されているどの学習済みモデルを使うかを決め、
(今回は、データの内容が英語のため英語の学習済みモデルを使用します)
# MODEL_NAME = 'cl-tohoku/bert-base-japanese-whole-word-masking'
MODEL_NAME = 'bert-base-uncased'tokenizerと学習済みBERTモデルのインスタンスを生成します。
tokenizer = BertJapaneseTokenizer.from_pretrained(MODEL_NAME, model_max_length=512, truncation=True, padding="max_length")
model = BertModel.from_pretrained(MODEL_NAME)BERTも万能ではないので、文をまるまる全部与えられても解釈できません。
そこで、文の意味を理解しやすいように単語(token)ごとに区切り、さらにはその単語を数字ラベルに変換してあげるのが、tokenizerの役割になります。
文章のベクトル化
BERTに文(単語)を渡すと、入力単語ごとのベクトルを吐き出します。
この作業は、文を文の意味を表すベクトルに変換し、文同士の意味上の類似度を計算するために利用します。
変換する関数は以下です。
def sentence_to_vector(model,token):
# BERTモデルの処理のためtensor型に変換
input = torch.tensor(token).reshape(1,-1)
# BERTモデルに入力し文のベクトルを取得
with torch.no_grad():
outputs = model(input, output_hidden_states=True)
last_hidden_state = outputs.last_hidden_state[0]
averaged_hidden_state = last_hidden_state.sum(dim=0) / len(last_hidden_state)
return averaged_hidden_statedef tokenize(tokenizer, sentences):
# 文を単語に区切って数字にラベル化
tokens = tokenizer(sentences)["input_ids"]
return tokens文章の類似度計算
文の類似度計算はcos類似度というものを使って算出します。
-1.0 ~ 1.0の間の値で、大きければ大きいほど文の意味が似ているという解釈ができます。
tokens = tokenize(tokenizer, [str(i) for i in df["description"].tolist()])
sim_mat = np.zeros((len(tokens), len(tokens)))
for i in range(len(tokens)):
for j in range(len(tokens)):
token1 = tokens[i]
token2 = tokens[j]
try:
sentence_vector1 = sentence_to_vector(model, token1)
sentence_vector2 = sentence_to_vector(model, token2)
score = torch.nn.functional.cosine_similarity(sentence_vector1, sentence_vector2, dim=0).detach().numpy().copy()
sim_mat[i, j] = score
except:
continue
pd.DataFrame(sim_mat)下記のように、各チケットのDescriptionの総当たりのコサイン類似度が出力されました。
※類似度0.0は対象外のデータ
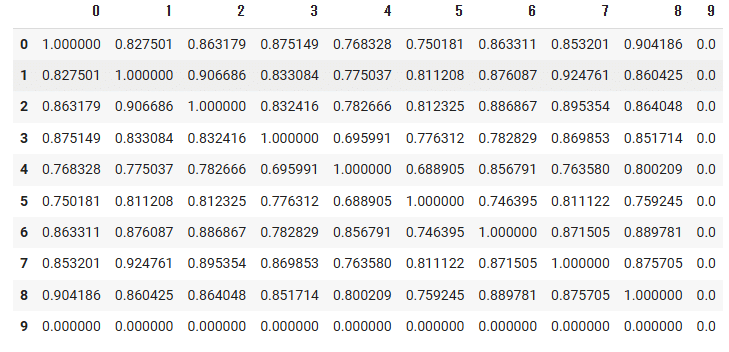
出力結果の検証
正しく類似度が計算されているかを検証してみます。
0番と8番(0.904186)のDescriptionを和訳し両者を比較してみると、
◇0番 の内容
xdocletを有効にしたejb/webプロジェクトを生成する方法が欲しい。既存のMaven Eclipse Pluginはjst.javaとjst.ejb/jst.webのfacetを追加します。XDocletの作成は、<faceted-project>内に<installed facet="jst.ejb.xdoclet" version="1.2.3"/>または<installed facet="jst.web.xdoclet" version="1.2.3"/>を追加することで可能です。この追加facetをオプションにし、バージョンを設定可能にするのが良いでしょう。または、ビルドに使用されるmaven-xdocletプラグインに基づいてこれを含めることも考えられます(適切なxdocletバージョンも抽出されます)。始めに、resolveEjbVersionに見られるようなダミーのバージョンリゾルバが全くxdocletサポートよりも良いでしょう。
◇8番 の内容
ISPN内にインデックスを保存するサポートを削除することを検討すべきです。
0番は、開発ツール(MavenとEclipse Plugin)を使用してプロジェクトを設定する方法に関する技術的提案
8番は、システムの設計やアーキテクチャに関する提案
となっており、両者はテクノロジーや開発手法に関して異なる側面を扱っているため、類似度は高くないようにみえます。
1番と7番(0.925761)を比較してみると、
◇1番 の内容
リポジトリが起動する際、JNDIにそのリポジトリを登録しようとしますが、読み取り専用のグローバルコンテキスト(例:Tomcatなど)では{{NamingException}}が発生します。このような場合、例外/エラーをログに記録するのではなく、情報/警告メッセージのみをログに記録すべきです。
◇7番 の内容
eclipseインストールに含まれるJBoss IDEからの""make-artifacts""ゴールを使用する際に、org.jbpm.core_3.0.9.jarでNPEが発生します。
1番は、システムのランタイム時における挙動の改善案に関する内容、
7番は、特定の開発ツール(EclipseとJBoss IDE)を使用してプロジェクトをビルドする際に発生するバグに関する報告となっており、
どちらもソフトウェア開発の過程で発生する問題についての報告や改善案を述べていますが、内容的には異なる側面を扱っています。
従って、類似度は高いとは言い難いです。
さいごに
今回はBERTモデルを使って、文章の意味の類似度を算出するタスクを実施しました。
結果として、元データの文章が長すぎること、記号が混在していることが類似度の正確性に影響を与えました。
そのため、重複と判断するための閾値を高く設定しても、完全な自動化は難しいと感じました。
Jiraを通じてインシデントを起票する際に、ラベルやカテゴリ、入力規則の設定などを管理することが理想ですが、こういった取り組みが業務負荷を増やす可能性もあります。
そのため、引き続きプログラミングによる自動化のアプローチを模索したいと考えます。
次回は生成AIをAPIで呼び出して活用することで、より正確に大量のデータの類似度の検出ができるかを検証してみたいと思います。