
パワハラプロンプトの論文と適応範囲の考察

今日では、当たり前のようにパワハラプロンプトを利用してますが、実際の効果や適用範囲について言及した人があまり多くない印象です。
本稿では、パワハラプロンプトの有効性、最適な反復回数、注意点、適用可能なタスクについて、関連論文の検証を基に詳細に考察します。
なお、他の論文解説のように網羅的なレビューをするのではなく、端的にパワハラプロンプトの具合を知るための個人noteなので、研究者が見ると異議を唱えたくなる構成になっています。
*明確にパワハラプロンプトという名前が使われた論文はないので、その他周辺から関連性のありそうな論文を収集(そのため、拾いそこなっている可能性大)
*本稿ではパワハラプロンプトと述べているが、実際にパワハラプロンプトが使われたわけではないので注意。
では、この出力を60点とします。100点の答えになるように再度、生成してください。
*パワハラプロンプト自体は提唱者である深津氏が、名前の変更を望んでいるので、良識のある人は周りで使うのは止めた方がいいだろう。
プロンプトの呼び方かえてほしい。あれは擬似的なベクトルコントロールなの。
— 深津 貴之 / THE GUILD (@fladdict) June 25, 2024
生成AIの回答の空間に、擬似的に基準アンカーを打ち込んで、そこから任意の方向に回答のベクトル空間をずらす技法。
関連研究の論文
Self-Refine論文
実験内容: GPT-3.5およびGPT-4を用いて、ダイアログ応答生成、数学的推論、コード最適化、コード可読性、Webインタラクションなど7つのタスクで自己批評と改善の効果を評価。
プロンプト設計: FeedbackプロンプトとRefineプロンプトを設定し、自己批評と改善のプロセスをプログラム上に実装。
評価方法: タスク固有のメトリクス、人間評価、GPT-4による自動評価を実施。
結果: ほぼすべてのタスクでベースライン(Zero-Shot)を上回る性能向上を確認。特に、反復回数を増やすことで性能が向上する傾向が見られました(最大4回の反復で顕著な改善)。
Recursively Criticizes and Improves (RCI)論文
実験内容: GPT-3.5を用いて数学推論タスクを、GPT-3.5およびGPT-4を用いてWebインタラクションタスクを評価。
プロンプト設計: プロンプトリンクに基づく自己批評と改善のプロセスを実装。
評価方法: タスク固有のメトリクスとベースライン(Zero-Shot、Zero-Shot-CoT、CoT)と比較。
結果: ほぼすべてのタスクでベースラインを上回る性能を示しましたが、推論タスクでは誤ったフィードバックにより性能が劣化するケースがあり、反復回数を2回に制限する必要があると示されました。
Large Language Models Cannot Self-Correct Reasoning Yet論文
実験内容:
ベンチマーク: 数学推論、常識推論、Q/A(GSM8K、CommonsenseQA、HotpotQA)
モデル: GPT-3.5-Turbo、GPT-4-Turbo、Llama-2-70b-chat
プロンプト設計: 自己修正のために3段階のプロンプト戦略を適用
モデルに初期生成を行わせるプロンプト
モデルに前の生成をレビューしフィードバックを生成させるプロンプト
モデルにフィードバックを用いて元の質問に再び答えさせるプロンプト。
結果:
正解ラベル(オラクルラベル)を使わない自己修正(内在的自己修正)を行ったところ、パフォーマンスが劣化。
GPT-3.5-TurboとLlama-2-70b-chatでは、自己修正後にすべてのベンチマークで精度が低下。
GPT-4およびGPT-4-Turboは初期の答えを保持する傾向が強く、性能の低下が抑えられるが、依然として限界が存在。
共通の課題:
誤ったフィードバックの影響: どの論文も、誤ったフィードバックがAIの性能に悪影響を与える可能性を指摘しています。
反復回数の最適化: 反復回数の設定が性能向上に大きく影響するため、タスクに応じた最適な反復回数の設定が求められます。
自己修正の限界: 内在的自己修正では、外部フィードバックなしでは性能向上が難しく、場合によっては劣化することが明らかになっています。
パワハラプロンプトの効果と問題点
効果の有無
パワハラプロンプトの直接的な効果については具体的なデータが不足しています。
(面白いことに定量的な評価をしている人は少ない。SNSでは、様々な人(フォロワーが数万単位のアカウントも含め)が称賛しているが、彼らは定性的情報(主として主観的評価が大半)を述べているに過ぎない)
しかし、類似の手法であるSELF-REFINEやRCIの研究結果から、適切なフィードバックがAIの出力品質を向上させる可能性が示唆されています。
ただし、効果はフィードバックの内容やタスクの種類に依存します。
例えばSelf-Refine論文でダイアログ応答生成、数学的推論、コード最適化、コード可読性、Webインタラクションなどは、パワハラプロンプトで改善する傾向にあるとの結果になりましたが、逆にLarge Language Models Cannot Self-Correct Reasoning Yet論文で数学推論、常識推論にパワハラプロンプトを利用するとむしろ精度の悪化や出力の低下が確認されました。
さらに、Large Language Models Cannot Self-Correct Reasoning Yet論文では、内在的自己修正が逆効果になることが示されており、パワハラプロンプトの効果には慎重な検討が必要です。
最適な反復回数
こちらも現時点では明確な最適反復回数は定まっていません。
RCI論文では誤ったフィードバックを避けるために2回に制限していますが、SELF-Refine論文では最大4回の反復で性能向上が確認されています。
LLMの自己修正に関する新たな研究(Large Language Models Cannot Self-Correct Reasoning Yet論文)では、内在的自己修正が性能を低下させることが示されており、反復回数の増加が必ずしも性能向上につながらないことが明らかになっています。
タスクの複雑さやAIの学習能力に応じて調整が必要です。
注意点
倫理的配慮: パワハラプロンプトは倫理的に問題があるとされています。AIに対しても敬意を持ち、人格攻撃や侮辱、脅迫を避ける建設的なフィードバックが必要です。
フィードバックの質: 具体的かつ建設的なフィードバックを提供し、AIの学習を阻害しないようにすることが重要です。
自己修正の限界: 内在的自己修正では、外部フィードバックなしでは性能向上が難しく、誤ったフィードバックによる性能劣化のリスクがあります。Large Language Models Cannot Self-Correct Reasoning Yet論文では、オラクルラベルなしの自己修正が性能を低下させることが示されており、これに対処するための技術的改善が求められます。
適用可能なタスク
現在のところ、パワハラプロンプトの具体的な適用範囲は明確ではありません。
しかし、SELF-REFINEやRCIの研究では、ダイアログ応答生成、数学的推論、コード最適化、コード可読性、Webインタラクションなど多様なタスクで性能向上が確認されています。
これらのタスクにおいて、パワハラプロンプトも有効である可能性がありますが、LLMの自己修正の限界を考慮する必要があります。
特に、Large Language Models Cannot Self-Correct Reasoning Yet論文の結果を踏まえ、内在的自己修正の有効性には疑問が残ります。
パワハラプロンプトの技術的側面
自己批評型AIモデルの技術的成果
多様なタスクへの適用可能性: 対話応答生成、数学的推論、コード最適化、コード可読性、Webインタラクションなど、幅広いタスクで適用可能。
ベースライン性能の向上: Zero-Shot、Zero-Shot-CoT、CoTなどのベースライン手法と比較して、自己批評型プロンプトは性能が向上。
反復による性能向上: 反復回数が増えることで、AIモデルの性能が向上する傾向が確認されています(ただし、内在的自己修正では限界がある)。
技術的な改善点
フィードバック生成の高度化:
高度な言語モデルの利用: より強力な言語モデル(例: GPT-4)を用いることで、洗練されたフィードバックが可能。
外部知識ベースとの連携: 専門的な知識ベースと連携し、正確で詳細なフィードバックを提供。
フィードバック特化型モデルの開発: フィードバック生成に特化したモデルを開発し、タスクに最適化された批評を実現。
フィードバック内容の制御:
プロンプトエンジニアリング: フィードバックの具体性と建設性を高めるためにプロンプトを工夫。例として、フィードバックの形式や特定の観点からの批評を要求。
制約条件の設定: 不適切な内容を防ぐために、特定の単語や表現の禁止、フィードバックの長さ制限などを設定。
自己評価能力の向上:
フィードバック妥当性判断: AI自身が生成したフィードバックの妥当性を判断する能力を開発し、誤ったフィードバックによる性能劣化を防止。
誤フィードバックの無視: AIがフィードバックの妥当性を判断できるように設計し、誤ったフィードバックを無視する機能を実装。
論文の簡単な解説
自己批評の反復による性能向上

この図は、Self-Refine論文における実験結果を示しており、対話応答生成、数学的推論、コード最適化など7つのタスクにおいて、自己批評の反復回数が増えるほど性能が向上する傾向を示しています。
ただし、特定のタスクでは反復回数が一定数を超えると性能が飽和または低下するケースも見られます。
コンピュータタスクにおける行動選択プロセス
この図は、RCI論文で提案されているAIエージェントの行動選択プロセスを示しています。
タスクのグラウンディング、状態のグラウンディング、エージェントのグラウンディングの3つのステップで自己批評(RCI)を用いて出力を改善しています。
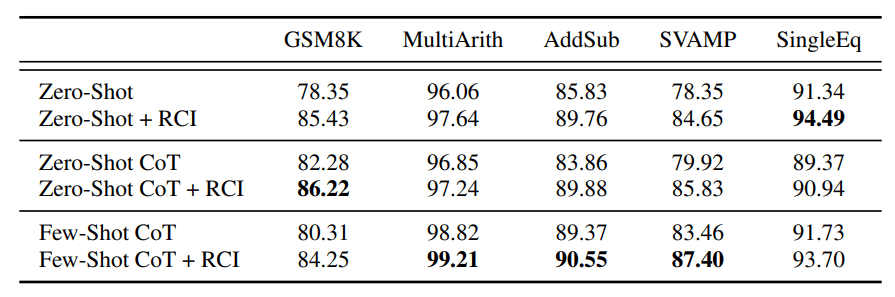
タスクレベル性能比較

この図は、RCI論文におけるWebインタラクションタスクの性能比較を示しており、RCIを用いたエージェントが既存の手法よりも高い性能を発揮していることが確認できます。
特に、複雑なタスクほどRCIによる性能向上が顕著です。
Large Language Models Cannot Self-Correct Reasoning Yet論文の実験結果


LLMが内在的自己修正を行った際のパフォーマンス低下を示しています。
特に、GPT-3.5-TurboとLlama-2-70b-chatでは、自己修正後にすべてのベンチマークで精度が低下しています。
これに対し、GPT-4およびGPT-4-Turboは初期の答えを保持する傾向が強く、性能の低下が抑えられています。
ポイントと感想
Large Language Models(LLM)の自己修正能力について、これまでの研究では自己批評型プロンプトが性能向上に寄与することが示されていました。
しかし、Huang et al.の研究は、オラクルラベルを用いない内在的自己修正が実際にはパフォーマンスを低下させることを明らかにしています。
これは、自己修正の過程で誤ったフィードバックが生成され、それがモデルの出力に悪影響を及ぼすためです。
この結果は、自己修正手法が万能ではなく、特に外部フィードバックが欠如している場合には慎重なアプローチが必要であることを示しています。
具体的な疑問への回答 (Q&A)
Q1: パワハラプロンプトはどのような仕組みでAIの性能を向上させるのでしょうか?
A1: パワハラプロンプトは、AIに厳しいフィードバックを繰り返し与えることで、AIが自身の誤りを認識し、修正することを促します。
この過程を通じて、AIはより正確で洗練された出力を生成できるよう学習していきます。
ただし、誤ったフィードバックが性能劣化を招くリスクも伴います。
Q2: パワハラプロンプトはどのようなタスクに有効なのでしょうか?
A2: パワハラプロンプトは、AIが明確な目標を持って出力を生成する必要があるタスク、例えば文章生成、翻訳、要約、質問応答などに有効である可能性があります。
しかし、創造性や多様性が求められるタスクには不向きかもしれません。
また、数学的推論や常識推論のようなタスクでは、適切なフィードバックが不可欠です。
Q3: パワハラプロンプトの具体的な例を教えてください。
A3: 例えば、AIが生成した文章に対して、「では、この出力を60点とします。100点の答えになるように再度、生成してください。」といったフィードバックを繰り返し与えることがパワハラプロンプトとされています。
このようなフィードバックにより、AIは応答の改善を試みることが期待されますが、数学・常識推論などではユーザーに適切な知識がないと、誤ったフィードバックを送ることになり、むしろ逆効果の可能性があります。
またどの論文も4回以上パワハラプロンプトを使っていないので、自己改善を断続的に利用した場合、出力結果の低下を招く可能性も考慮する必要があるでしょう。
Q4: パワハラプロンプトの危険性は何でしょうか?
A4: パワハラプロンプトは、倫理的に問題があるだけでなく、技術的な観点からもいくつかの危険性を孕んでいます。
例えば、誤ったフィードバックによってAIの学習が阻害されたり、AIがフィードバックの内容に過剰に適応し、偏った出力を生成する可能性があります。
また、AIに対する過度なフィードバックは、AIの出力の多様性や創造性を損なう恐れがあります。
考察
自己批評を用いたAIモデルは、AIの性能向上に大きく貢献する可能性を秘めています。
しかし、その実現には、フィードバック生成の高度化、フィードバック内容の制御、自己評価能力の向上など、多くの技術的課題を克服する必要があります。
さらに、Large Language Models Cannot Self-Correct Reasoning Yet論文の結果から、内在的自己修正には限界があることが示されており、外部フィードバックの重要性が再認識されました。
AI技術の健全な発展のためには、パワハラプロンプトのような手法ではなく、SELF-REFINEやRCIのような、AIの自己学習能力を促進する倫理的な手法を採用することが重要です。
(つまり、パワハラではなくとも良いとも言える。)
結論
本稿では、パワハラプロンプトの効果と問題点について、関連論文を基に詳細に考察しました。
自己批評型プロンプト手法は、多様なタスクでの性能向上を示す一方で、誤ったフィードバックや倫理的課題が存在します。
さらに、LLMの自己修正能力に関する最新の研究から、内在的自己修正には限界があり、外部フィードバックの活用が重要であることが示されました。
今後の研究では、これらの課題を克服し、より効果的で倫理的な自己批評型プロンプトの開発が求められます。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?