
S&P500 AIで今後の価格を予測する

サブテーマ:AI /LSTMモデルで時系列予測 入門編
1 初めに
今回はついにAIを使った未来予測にチャレンジします。使用するのは話題の脳の神経細胞の動きを模したニューラルネットワークを使った深層学習モデルの中から、株価など時系列予測に強いと言われるLSTMというモデルを使って、S&P500の株価を予測します。反響次第で精度を上げる工夫等を盛り込みさらに改良を重ねた記事を紹介していきますが、まずは時系列の情報のAI・深層学習としてニューラルネットワーク入門とした基本コードとなりますので、ぜひお付き合いください。
今回のまとめ:
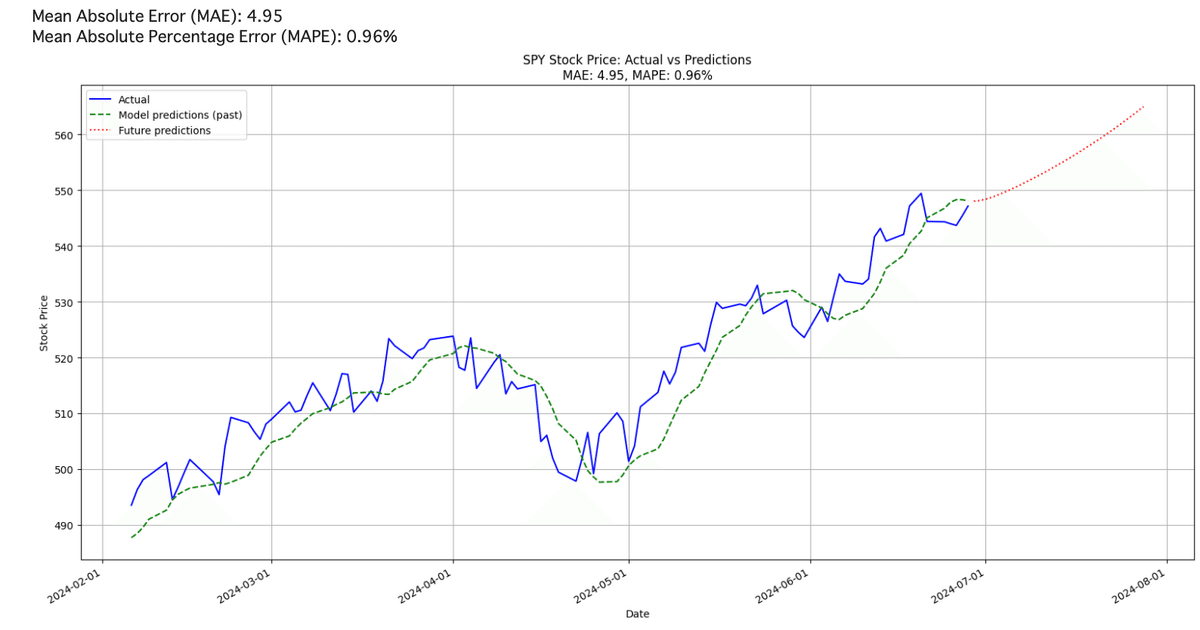
S&P500”SPY”をLSTMを使って予測できるコードを紹介
(過去区間ではMAE5以下、MAPE 1%以下)
知人よりプログラム部分が難しくてよくわからないとご指摘をいただきました。そのためこのチャンネルでは、PYTHONを使った米国株投資に関わるさまざまな調査の結果OUTPUTにこだわった記事にします。投資に関わる身近な疑問にも答えていきますので、投資リテラシー向上にお役立ちを目指します!!
なお、全ての解析データは引き続き、PYTHONを活用してコード全文も掲載します。Googleコラボで動作確認したコードですので、まずは”コピペ”でチャレンジできます。これから勉強始めたい方にも、プログラミングで何ができるのかを知る良いチャンスとなればと思っていますので応援お願いします!!
(申し訳ありませんが、コード全文のみ有料設定させてもらってます。応援いただける方、時系列予測に挑戦したい方はぜひご検討ください。)
2 豆知識
1)ニューラルネットワークとは
ニューラルネットワークは、人間の脳の構造と機能を模倣した機械学習の一形態です。基本的な構成要素は「ニューロン」と呼ばれる計算単位で、これらが層状に配置されます。ニューラルネットワークは通常、入力層、中間層(隠れ層)、および出力層の3つの主要な層から構成されます。
入力層は、外部からのデータを受け取り、中間層に渡します。中間層は、複数のニューロンで構成され、各ニューロンは入力データに対して特定の重みとバイアスを適用し、活性化関数を通じて非線形変換を行います。このプロセスにより、データの複雑なパターンや特徴を抽出します。出力層は、中間層からの処理結果を集約し、最終的な予測や分類結果を生成します。
ニューラルネットワークの学習は、訓練データを用いて行われます。目標は、出力が正確になるように重みとバイアスを調整することです。これは、誤差逆伝播法(バックプロパゲーション)を使用して行われ、出力と正解データの誤差を計算し、その誤差を最小化する方向に重みを更新します。一般的に言われるディープラーニングは、ニューラルネットワークの一種で、多層の中間層(ディープネットワーク)を持ち、より高度な特徴抽出と学習が可能です。これにより、画像認識、音声認識、自然言語処理など、様々な複雑なタスクで優れたパフォーマンスを発揮し、その強力な学習能力と柔軟性により、多くの分野で革新的な成果をもたらしています。特に、大量のデータが利用可能な場合、その効果は顕著であり、AI技術の中心的な役割を果たしています。
2)LSTMとは
LSTM(Long Short-Term Memory)は、音声認識、文章生成、株価予測など、長期依存性が重要なタスクに広く利用されています。特に株価予測では、過去の株価データのパターンを学習し、将来の動きを予測するのに効果的です。LSTMを使用することで、過去のトレンドや周期的な変動を考慮に入れた精度の高い予測が可能となります。
リカレントニューラルネットワーク(RNN)の一種であり、RNNは時系列データを処理するのに有効ですが、長期依存性の問題を抱えています。これに対し、LSTMは「記憶セル」を導入し、重要な情報を長期間保持する能力を持ちます。具体的には、LSTMはセルステートと3つのゲート(入力ゲート、忘却ゲート、出力ゲート)を使用して情報の流れを制御します。入力ゲートは新しい情報をセルに加えるかどうかを決定し、忘却ゲートは過去の情報をどれだけ忘れるかを決定します。出力ゲートはセルの情報を次のステップにどれだけ出力するかを制御します。このメカニズムにより、LSTMは重要な情報を長期間にわたって保持し、無関係な情報を忘れることができます。このように、LSTMはRNNの長期依存性の課題を克服するために設計された強力なモデルであり、多くの時系列データの予測タスクでその威力を発揮しています。
3 実践
1)実施内容
今回Pytorch-Lightningという比較的簡易にモデルが構築できるライブラリを用います。GoogleColabではPipコマンドでインストール・実行が可能です。解析するデータはYahooFinanceからS&P500インデックス連動ETF:SPYの価格を約20年分取得します。その結果をLSTMモデルを用い、学習させ、30日後までのS&P500の値動きの予測結果をグラフで出力させます。
ニューラルネットワークを用いたモデルは、モデル形態だけでなく、学習率や学習回数など多数のハイパーパラメータと呼ばれる変数があり、予測精度に大きな影響を与えます。今回はLSTM基本モデルでの学習としますが、今回のプログラムコードでもLSTM層数、隠れ層のユニット数、学習率等簡単に変更実行できるコードとなっていますので、興味のある方はぜひ挑戦してみてください。
2)実践
初めにPiPインストールし、必要なライブラリ等のインポートののち、株価を取得します。
!pip install yfinance japanize-matplotlib pytorch-lightning
import pandas as pd
import numpy as np
import math
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_absolute_error
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import yfinance as yf
from datetime import date
import pytorch_lightning as pl
# データの取得と前処理
end_date = date.today().strftime("%Y-%m-%d")
start_date = '2004-01-01'
df = yf.download('SPY', start=start_date, end=end_date)その学習データを訓練データと評価データを8:2に分割します。それぞれ関数を使っていますが、初めはコピペで実行してみて、必要に応じアレンジしてみてください。
training_data_len = math.ceil(len(df) * .8)
train_data = df[:training_data_len].iloc[:,:1]
test_data = df[training_data_len:].iloc[:,:1]
scaler = MinMaxScaler(feature_range=(0,1))
scaled_train = scaler.fit_transform(train_data)
scaled_test = scaler.transform(test_data)
def create_sequences(data, seq_length):
X, y = [], []
for i in range(len(data) - seq_length):
X.append(data[i:i+seq_length])
y.append(data[i+1:i+seq_length+1])
return np.array(X), np.array(y)
sequence_length = 50
X_train, y_train = create_sequences(scaled_train, sequence_length)
X_test, y_test = create_sequences(scaled_test, sequence_length)次に実際のLSTMモデル部分です。
ClassのLSTMモジュールのdefそれぞれに層構造や訓練・検証、学習時の学習率の設定等の記載を行っています。
class LSTMModel(pl.LightningModule):
def __init__(self, input_size, hidden_size, num_layers, dropout=0.2):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, dropout=dropout)
self.linear = nn.Linear(hidden_size, 1)
self.train_losses = []
self.val_losses = []
def forward(self, x):
out, _ = self.lstm(x)
out = self.linear(out)
return out
def training_step(self, batch, batch_idx):
X, y = batch
y_hat = self(X)
loss = F.mse_loss(y_hat, y)
self.log('train_loss', loss)
return loss
def validation_step(self, batch, batch_idx):
X, y = batch
y_hat = self(X)
loss = F.mse_loss(y_hat, y)
self.log('val_loss', loss)
return loss
def on_train_epoch_end(self):
# エポック終了時にTraining Lossを記録
self.train_losses.append(self.trainer.callback_metrics['train_loss'].item())
def on_validation_epoch_end(self):
# エポック終了時にValidation Lossを記録
self.val_losses.append(self.trainer.callback_metrics['val_loss'].item())
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=1e-4)
train_dataset = StockDataset(X_train, y_train)
val_dataset = StockDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32)次に、実際に改めて実際にモデルを”model=”を組み立て、trainer=&trainer.fitで訓練します。
model = LSTMModel(input_size=1, hidden_size=64, num_layers=2, dropout=0.2)
trainer = pl.Trainer(max_epochs=10, accelerator='auto')
trainer.fit(model, train_loader, val_loader)
学習後のTrainigLoss,ValideationLossは下記の関数でプロットし、学習過程を確認します。
# Training LossとValidation Lossのプロット
def plot_losses(model):
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(model.train_losses) + 1), model.train_losses, label='Training Loss')
plt.plot(range(1, len(model.val_losses) + 1), model.val_losses, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.grid(True)
plt.show()
# Lossのプロット
plot_losses(model)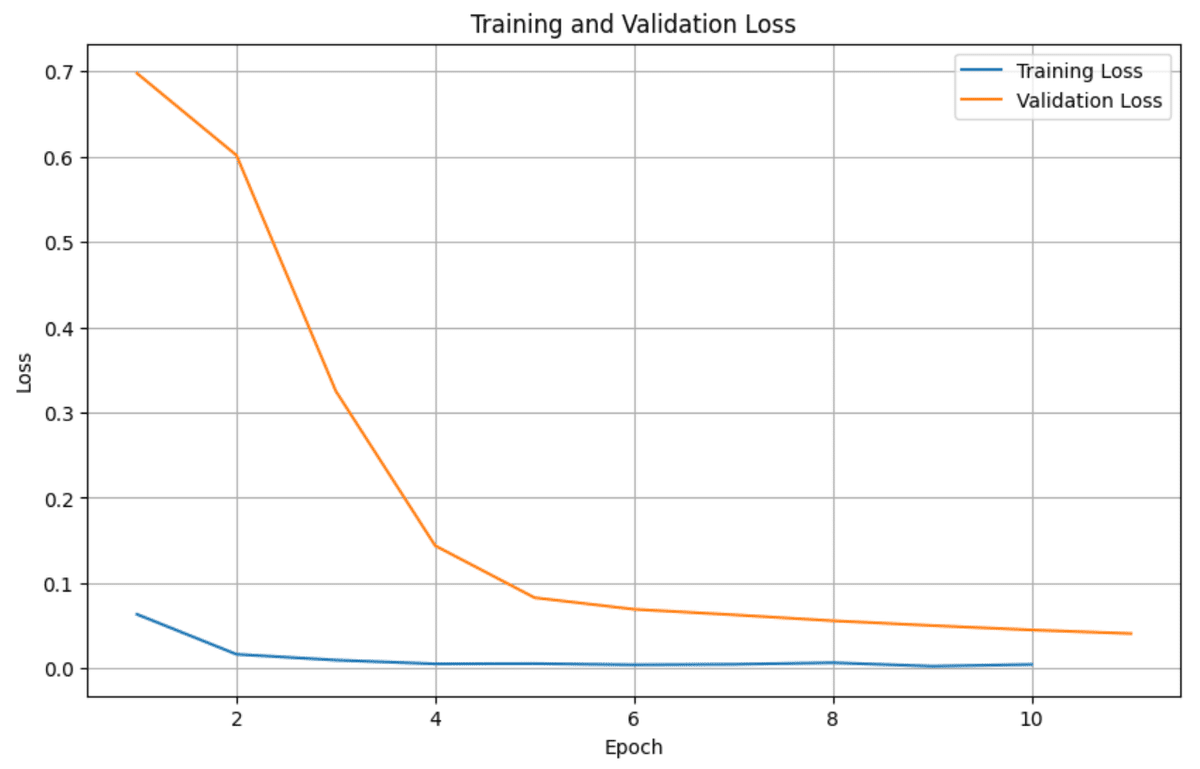
最後にこれまで学習したモデルを使って30日後の結果を予測します。参考まで過去100日間の実績と、このモデルが予測した値をプロットしモデルの精度を目で比較できるようにしました。またMAE(どれぐらいズレるか)とMAPE(何%ズレているか)という指標を計算して出力します。
# 予測
model.eval()
num_forecast_steps = 30
historical_data = torch.tensor(scaled_test[-sequence_length:]).unsqueeze(0).float()
forecasted_values = []
with torch.no_grad():
for _ in range(num_forecast_steps):
prediction = model(historical_data)
forecasted_values.append(prediction[:, -1, :].numpy())
historical_data = torch.cat([historical_data[:, 1:, :], prediction[:, -1:, :]], dim=1)
forecasted_values = np.array(forecasted_values).squeeze()
# 過去100日間の実績データと予測値の計算
past_100_days = test_data.index[-100:]
past_100_days_data = scaler.inverse_transform(scaled_test[-100:])
# モデルによる過去100日間の予測
model_predictions = []
with torch.no_grad():
for i in range(100):
input_data = torch.tensor(scaled_test[-(100-i+sequence_length):-(100-i)]).unsqueeze(0).float()
prediction = model(input_data)
model_predictions.append(prediction[:, -1, :].numpy())
model_predictions = scaler.inverse_transform(np.array(model_predictions).squeeze().reshape(-1, 1))
# 未来30日間の予測値
future_dates = pd.date_range(start=test_data.index[-1] + pd.Timedelta(days=1), periods=30)
future_predictions = scaler.inverse_transform(forecasted_values.reshape(-1, 1))
# MAEとMAPEの計算
def calculate_metrics(actual, predicted):
mae = mean_absolute_error(actual, predicted)
mape = np.mean(np.abs((actual - predicted) / actual)) * 100
return mae, mape
mae, mape = calculate_metrics(past_100_days_data, model_predictions)
print(f"Mean Absolute Error (MAE): {mae:.2f}")
print(f"Mean Absolute Percentage Error (MAPE): {mape:.2f}%")
# プロット
plt.figure(figsize=(16, 8))
# 過去100日間の実績
plt.plot(past_100_days, past_100_days_data, label='Actual', color='blue')
# 過去100日間のモデル予測
plt.plot(past_100_days, model_predictions, label='Model predictions (past)', color='green', linestyle='--')
# 未来30日間の予測
plt.plot(future_dates, future_predictions, label='Future predictions', color='red', linestyle=':')
plt.xlabel('Date')
plt.ylabel('Stock Price')
plt.title(f'SPY Stock Price: Actual vs Predictions\nMAE: {mae:.2f}, MAPE: {mape:.2f}%')
plt.legend()
plt.grid(True)
# x軸の日付フォーマットを設定
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
plt.gcf().autofmt_xdate() # 日付ラベルを斜めに表示
plt.tight_layout()
plt.show()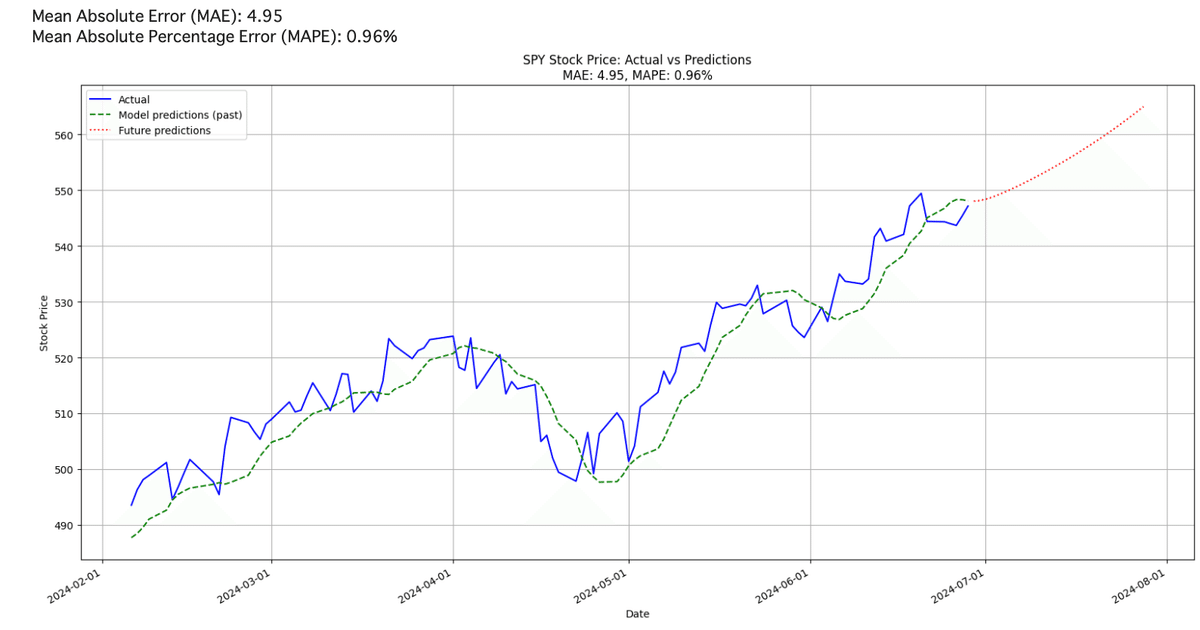
実際に学習・予測結果をプロットすると、過去区間に置いて比較的予測値と近くうまく学習できていることがわかります。その上で赤の点線が未来の予測ですが、このモデルではこれから30日間やや上昇傾向という結果が出ました。実際この区間において、MAEが誤差の大きさ(平均)で5以下、MAPEはこの区間の誤差の割合%で1%以下とか過去の区間においては十分な精度で計算できています。
この結果はたまたまな可能性が高いので、実際の売買するにはおすすめできませんが、今後さらにモデルの構造を見直したり、学習の仕方を最適化するなどして信頼できるモデルを開発してみては如何でしょうか?
補足)GoogleColabでGPUを使う
ニューラルネットワークを持ち学習すると通常のCPUでは時間がかかります。この学習に最適なのはNVIDAで有名なGPUを使うことではるかに早く学習させることができます。GoogleColabでは無料プランの枠内でも下記のノートブックの設定でT4GPUが設定でき学習の省時間化ができます。無料であれば使い続けることはできませんが、ニューラルネットワーク、AI等に興味のある方には力強いアイテムですのでぜひ使ってみてください。
4 まとめ
今回ニューラルネットワークによる時系列予測をLSTMモデルを使って、S &P500の今後の予測を行うコードを紹介しました。入門編としてのコードですが、LSTMの総数、隠れ層の数、ドロップアウトという手法を盛り込み、学習経緯のプロット、今後の予測など一連の動作がわかるようコードを用意してみました。今後も引き続き、投資リテラシー&プログラミングに関連した話題を提供していきますので応援よろしくお願いします。
*今回の結果は過去の結果を解析したものであり、今後の将来を保証するものではありません。実際の投資にあたってはご自身の判断でお願いいたします。
記事の感想、要望があれば下記X(旧Twitterまで)
*今後の記事に活用させていただきます!!
以下、過去記事、AI時系列予測等のご紹介
他サイトですがココならで、A I(LSTM)を使った株価予測の販売もやってます。こちらではFREDから、失業率や2年10年金利、銅価格等結果も取得しLSTMモデルで予測するコードとなってますので興味があれば見てみてください。またその他2件も米国株投資とは直接関係はありませんがプログラム入門におすすめです。
チャンネル紹介:Kota@Python&米国株投資チャンネル
過去の掲載記事:興味PYがあればぜひ読んでください。
グラフ化集計の基礎:S &P500と金や米国債を比較してます。
移動平均を使った時系列予測
コード全文:
ここから先は
¥ 2,400
この記事が気に入ったらチップで応援してみませんか?