
再現しないスロークエリを再現させた話

こんにちは、犯人はキャッシュミスと申します。ナビタイムジャパンで地点検索サービスの開発をしています。
今回は掲題の通り、特定リクエストによる再現性の無いパフォーマンス悪化の原因を特定して、解決したときの試行錯誤のエピソードについて書いてみたいと思います。
Solrを用いた検索システム上でのお話になりますが、試行錯誤の形跡や得られた教訓などはどのレイヤーの開発をしている方にも通じるところがあるものと考えておりますので、よろしければ検索エンジニアではない方もお読みください。
今回遭遇した事象の紹介
当社は沢山のサービスを提供しており、そのバックエンドにある地点検索システムはサービス横断的に共通のものが提供されています。
しかし、「特定のサービスからのフリーワード住所検索が、他サービスからのものと比べて平均約10倍遅いので改善してほしい」という問い合わせがありました。
ログを確認すると確かに遅いリクエストの存在が確認できましたが、同じリクエストを調査のために投げてみると一瞬でレスポンスが返ってきました。
過負荷で一時的にスループットが悪化した可能性も考えましたが、全時間帯にわたって満遍なく遅いリクエストが存在したためこの仮説は否定され、遅い原因の見当がつかない状態に陥りました。
さらにスロークエリの遅さが再現できていないため、「遅いリクエストのパラメータを1つずつ削っていき、どのパラメータが速度に致命的に効いているか」といった試行錯誤もできないことが非常に厄介でした。
当社の検索システムについて
調査の詳細に入る前にシステム構成の概要について紹介します。
当社の検索システムはまず検索サーバにリクエストが届き、条件に応じて検索サーバがバックエンドのSolr(全文検索エンジン)に複数回のリクエストを投げるという構成を取っています。
図にすると以下のようになります:

本記事の本筋からは逸れますが、最初に揺らぎ許容度の少ない検索を行い、それで0hitだったら多少の曖昧性を考慮した検索を行う、といった工夫をしています。
どう調査していったか
たくさんの容疑者
今回は、前節の構成図でいうところの検索サーバ層でリクエスト遅延発生の事実が観測されました。ただし検索サーバ層のスローログ単体では
単純にバックエンドのSolrが遅い
バックエンドのSolrが遅すぎてタイムアウトになり、Solr側にログが残っていない
検索サーバ内の何かが遅い
検索サーバ・Solr間のネットワークに遅延がある
など複数の可能性を排除できず、疑わしい点に絞った効率的な調査が難しいと感じました。
トレーサビリティの担保
そこでまずはSolrリクエストのログ整備を行いました。検索サーバへのリクエストにはどのサービス由来のリクエストかを示すサービスIDがついているのですが、これをSolrまで引き回してリクエストログに記録されるようにしました。

この変更により、「遅くなるという指摘のあったサービスIDのリクエストでのみ、バックエンドのSolrが遅くなることがある」ということが判明しました。
依然として「同じリクエストを調査のために投げてみると一瞬でレスポンスが返る」という事象は解明されていませんが、トレーサビリティの担保によりその他の可能性を排除することができて調査が一歩前進しました。
次に、Solrに投げられているスロークエリを観察することで共通点を見つけることができました。「該当サービスからのリクエストでのみ、特定の絞込条件が付与されている」ことがわかりました。ただしスロークエリは再現していないため、何故遅いのか・その条件を消すと遅くならないのか、などの確認はこの段階ではできません。
スロークエリの再現
続いて、リクエスト条件を揃えてみようということで、ログ上で遅かったクエリだけでなく実際にSolrに投げられていたリクエストを時系列順に全て投げることを試しました。すると単体で投げて遅くならなかったリクエストもログと同程度に遅くなりました。ついにスロークエリを再現することができました。
また同じ投げ方で、先述したこのサービス特有の絞込条件をなくしたリクエストを投げると遅くならないことが確認できました。この段階でSolrのキャッシュに関連した挙動が原因である可能性を疑い始めました。
Solrのキャッシュについて
公式ドキュメントによると、Solrの `fq` パラメータによる絞り込みは「そのフィルタに合致したドキュメントIDの集合」を計算し、その結果をキャッシュするようです(参考)。 どの条件がキャッシュされているかは、Solrのキャッシュ設定に `showItems={表示したいキャッシュ件数}` を指定すると確認できるようになります。
<filterCache class="solr.FastLRUCache"
size="512"
initialSize="512"
showItems="512"
autowarmCount="0"/>
上記画像はid指定(fqパラメータに `id:xxx` と指定)のリクエストを大量に投げた場合のキャッシュ画面の様子で、
`CACHE.searcher.filterCache.item_id:500` などと絞込み内容がキャッシュされていることが分かります。
また絞り込み結果のドキュメント集合もキャッシュされており、`id:{* TO *}` (任意の id のドキュメントを抽出) の絞込み結果はドキュメント数が多いため2.3KBほどになっていることもここから読み取れます。
解決編
問題となっていたSolrについてキャッシュ内容を確認したところ、緯度経度による空間絞り込みのキャッシュが大量に存在することが分かりました。これは主に緯度経度から住所を割り出す「逆ジオコーディング(逆ジオ)」と呼ばれる処理によるものです。
キャッシュ周りの挙動は、多少状況を単純化して図にすると以下のようになっていました。
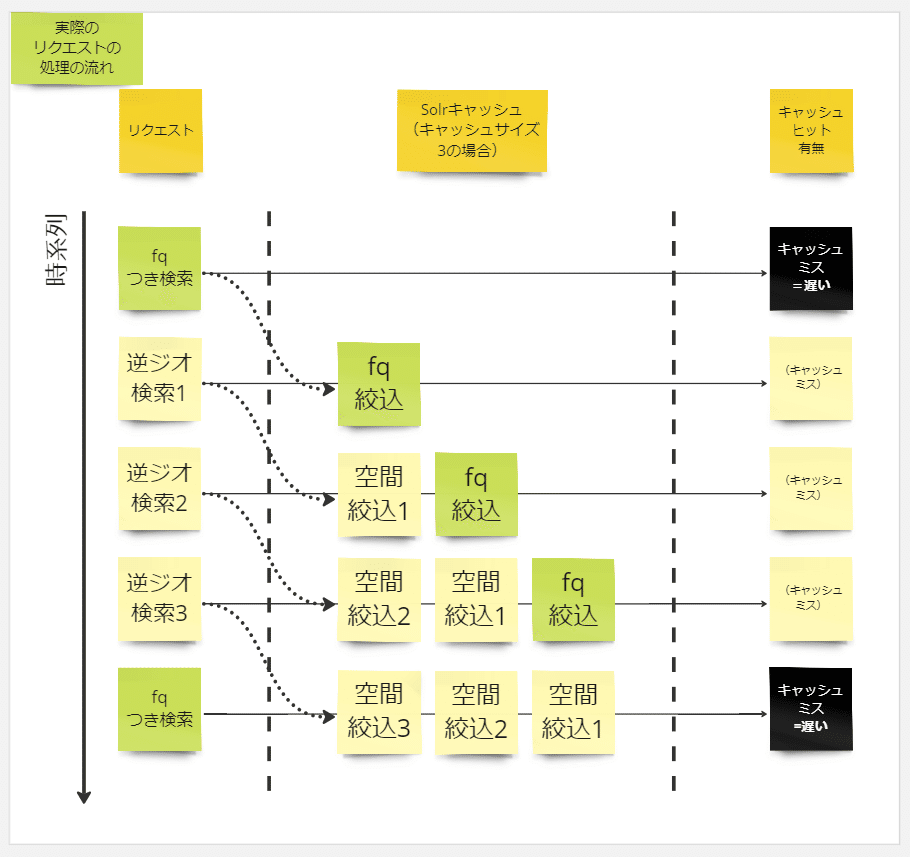
当社のアプリでは一定間隔で現在地の住所を取得して地域に応じた渋滞や災害情報などの配信を行うものもあり、逆ジオのリクエスト頻度が非常に高くなっています。
かつ逆ジオ利用シーンの性質から毎回別々の緯度経度が付与されるため、キャッシュ領域を埋め尽くすような状態になっていました。
ちなみにSolrのキャッシュはデフォルトでLRUキャッシュとして動作するので、キャッシュが溢れた場合は古いものから順に押し出される挙動になります。
一方で問題のスロークエリ(図中では「fqつき検索」と表記)は逆ジオよりリクエスト頻度が大幅に低いため、一度呼ばれてから次に呼ばれるまでにはその絞り込み結果がキャッシュから押し出されてしまっていました。
このようにキャッシュミスにより重い絞り込み計算を毎回行っていることがレスポンスの遅さの原因でした。
一方で、最初の調査時のキャッシュ周りの挙動は以下の通りでした。

遅かったリクエストを集めてきて流していたのですが、それらのリクエストにはどれも同じ絞り込み条件が付いていたためキャッシュがフルに活用でき、最初以外ほとんどのリクエストは一瞬で結果を返却できていました。これが「再現しない」スロークエリの正体でした。
原因がわかってしまえば対処はシンプルでした。逆ジオ時の緯度経度による絞り込みは同じものが連続で投げられる可能性が低く、かつキャッシュなしでもさほど遅くないのでキャッシュする意義が薄いため、 `{!cache=false}` というパラメータを付与してキャッシュされないよう変更してみました。
// 変更前
fq={!geofilt}
// 変更後
fq={!geofilt cache=false}その結果該当サービスで問題となっていた絞込条件はほぼ常にキャッシュに乗るようになり、スロークエリは解消しました。
ペアプロでの調査
なお補足となりますが、解決編に入るまでの調査の試行錯誤はペアプロで行いました。一人だけで調査するのに比べて
ちょっとしたコマンド(例:curlでリトライしたいときのオプションなんだっけ?)でハマる確率がだいぶ下がる
発想の多様性があるので、思考が行き詰って進まなくなることが起きにくくなる
再現しない調査は気が重くなりがちだが、仲間がいることで精神的に若干楽になれる
といった点が明確に利点で、早期の原因特定に大きく寄与しました。
まとめ
今回の調査ではいくつかの教訓が得られました。
まず1つ目はトレーサビリティの重要性です。同じリクエストを投げ直してもキャッシュやデータ更新などにより厳密に結果が再現できない場合があるため、その時どのリクエストに対して対応するバックエンドへのリクエストが送出されたのかを正確に把握できることが問題切り分けのために非常に重要だと身に染みて理解できました。
2つ目は「環境差異の要因として、投げたリクエスト以外のリクエストによる影響も無視できない場合がある」ということです。
今考えれば「再現しないならキャッシュを疑う」というのは当たり前にまず考えるべき選択肢だったと思いますが、キャッシュミス以外の原因による再現性関連調査においても応用が効く考え方ではないかと思います。
3つ目は難しい調査におけるペアプロの有効性です。今まであまり調査とペアプロを結び付けて考える場面が無かったのですが、ゴールまでの道筋が見通せていない総合格闘技のような調査タスクにおいては効率面でも精神面でも非常にメリットが大きかったです。
本記事がこの世の再現性をわずかばかりでも高める助けになりましたら幸いです。