📕【解説】【解釈】AIイラストの学習と生成について

↑こちらの記事で作った図解についての説明をします
【学習について】
メーカーがネット上に「公開している」画像を
機械的に取得していき、タグを付けます
それを使ってAIはトレーニングをします
いわゆる「教師あり学習」というものだと思います
画像はタグとに特徴をセットにして学習します
膨大な画像でそれを行うことで
「色の概念、形状の概念、雰囲気の概念、モノの概念」などを得ます
「茶色い、大きい、可愛い、クマのぬいぐるみ」というのを指定されたら
大体どんな絵にしたらいいか予測ができるでしょう?
そのための学習です
これにより「アニメ絵」「可愛い」などのタグと絵師の絵の特徴が紐つけられていると思います
一枚絵の特徴を引き継ぐわけではありませんが
似た感じの絵が出てしまう場合はあります
データセットはそれを行った後の「使用済み問題集」なんだと思います
トレーニングが終わったら使いません
データセットはオープンになっているので他の企業も違うモデルの学習に利用することができています
学習は「ネット上で公開になっている画像」全部に行われているため
学習されたくない絵は非公開にするしかありません
学習拒否か拒否でないかは個別に判断ができないからです
もし嫌なら課金すると見れるように鍵をかけて非公開にするといいと思います

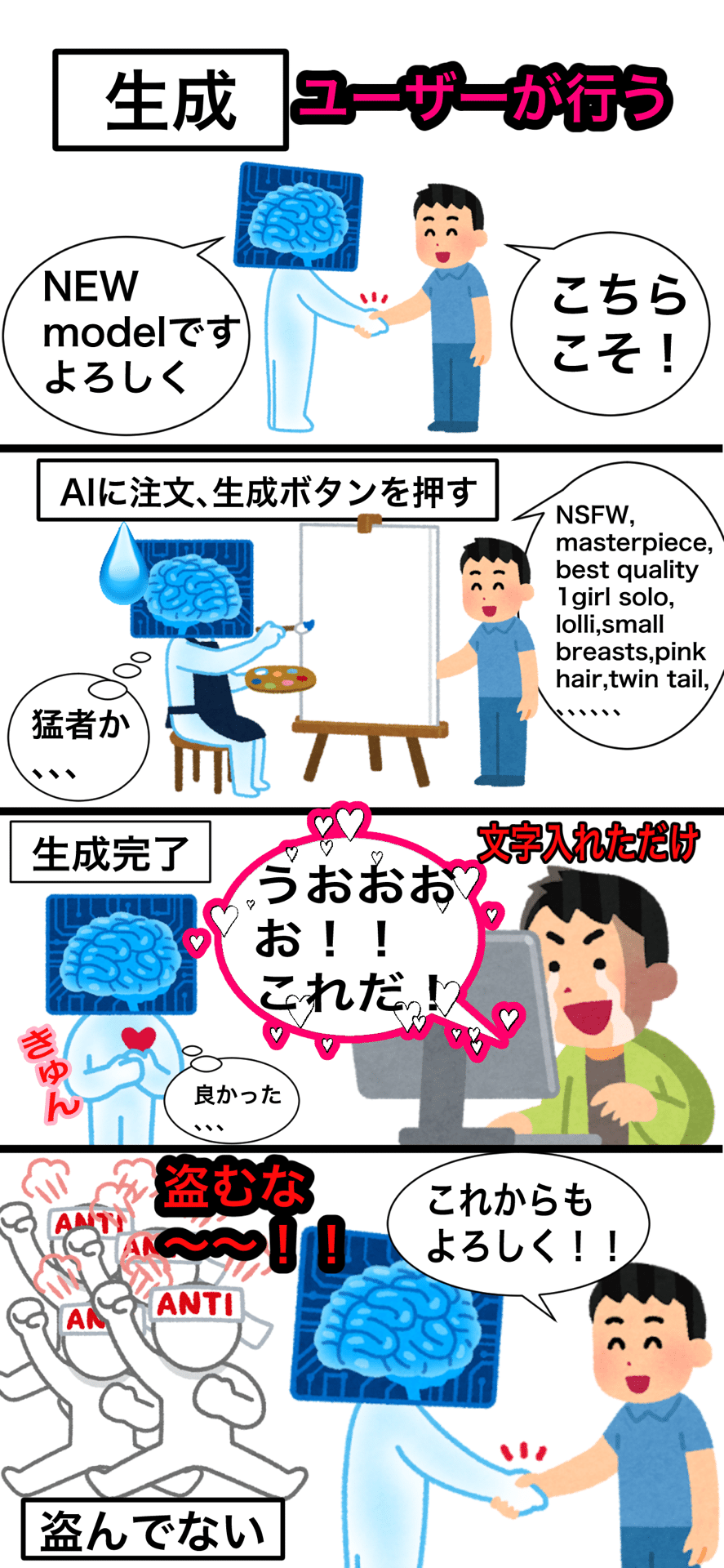
【生成について】
モデルは「色の概念、形状の概念、雰囲気の概念、モノの概念」が学習完了になっているので
プロンプトという「文字」を書き込み生成ボタンを押すと
予測された画像が生成されます
これは著作物の画像を混ぜ合わせる工程ではありません
まっさらなところから文字を元に予測をして生成しています
だからありえない画像ができてしまうのです
実際の絵師の絵を組み合わせているだけならあんな頻度で6本指のキャラや4本指のキャラは出ないです
絵師の絵で指が多かったり少なかったりする絵はほぼ見かけませんしね、、、
なのでほとんどのAIユーザーは文字を入れるだけで生成しています
【i2iについて】
i2iは画像をi2iのアップロード部分に入れて生成するものですが
大体こういう感じになります↓
モラルとしてAIユーザーは他人の画像は使いません
自分が描いた絵か
以前自分が生成した画像を使います
ストレングスの数値によっては全く違う絵が生成されてしまいます




面影がない、、、
【追加学習について】
特別に何かに特化した画像を生成するためにLoRaを作る場合があります
絵師の絵以外にも何かに共通した特徴を持った絵を生成するためにLoRaを作成したり使ったります
そのために画像を追加学習する場合があります
stable diffusionの拡張機能を使って行います
計算が速いPCでないと難しいのではと思うので高額なPCを所有している人が行えるのでは?と思います
ですのでLoRaを作る人は限られているかも知れません
ちなみに七瀬葵LoRaだそうです

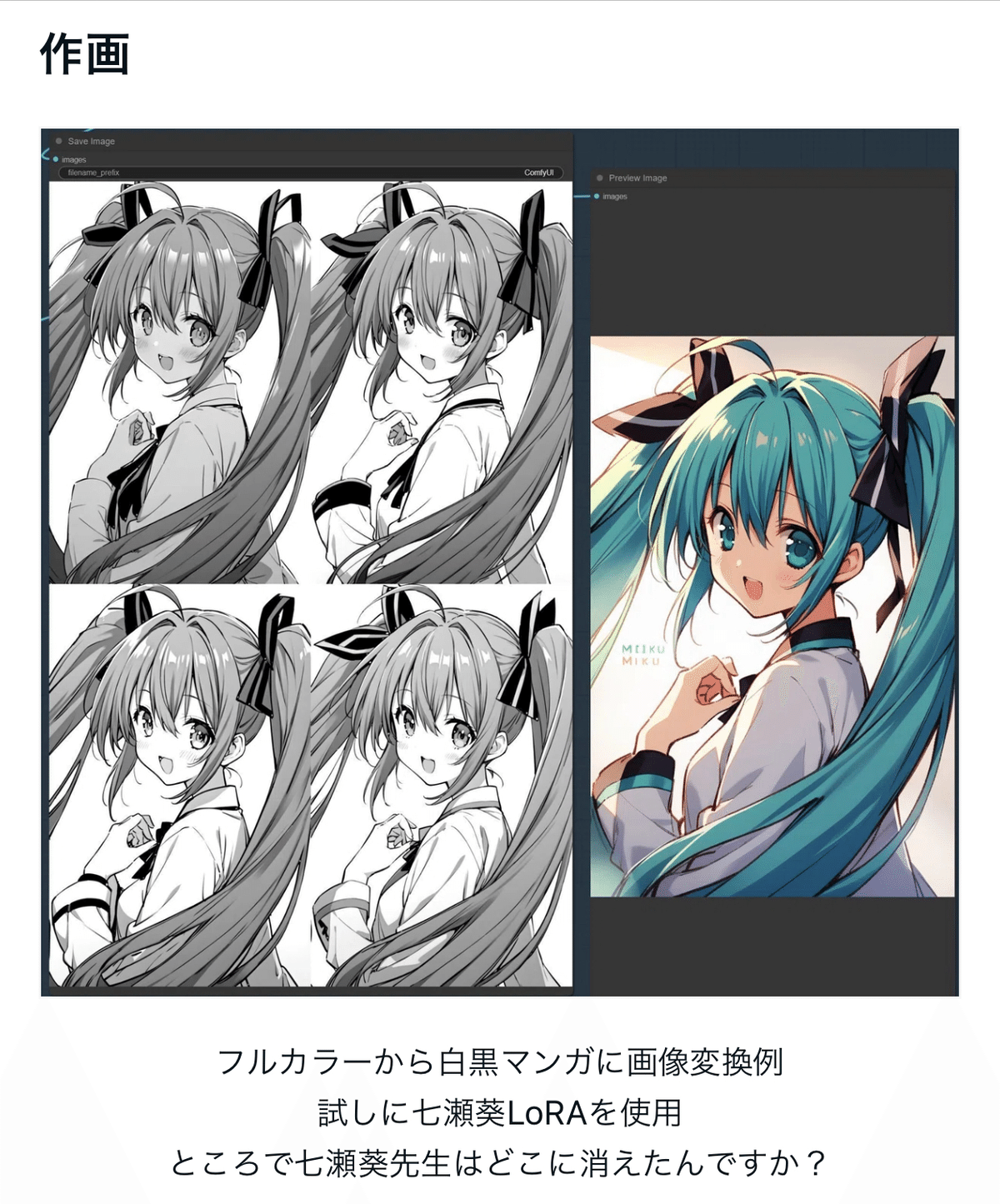
私はスマホアプリを使っているのですが
LoRaを作る機能は搭載されていないので追加学習はできません
なので私は他人の絵師の絵は一枚も使っていません
私個人はこういう理解をしているのですが
「ここ違うよ」というところがあったら言ってください
#マガジン 📕
#画像生成AI
#学習
#生成
#i2i
#LoRa
#AIユーザー
#解説
#図解
#仕組み
#概念
#理解