
Python.01 データ前処理

勝手に自由研究でのPython、備忘録含め、誰かの役に立ったら嬉しいなということで、データ前処理について書きます。(この記事はこの後のグラフ作成に続く予定です)
使用データ
厚生労働省さんのデータからわかる-新型コロナウイルス感染症情報-から、新規陽性者数の推移(日別)のオープンデータ(CSV形式)を使わせてもらいました。ファイル名は「newly_confirmed_cases_daily.csv」
※ Macはそのままいけますが、Windowsの方は、一旦メモ帳で開いて、
テキストエンコーディングをUTF-8にして保存し直してください。
CSVファイル読み込み
ファイル「newly_confirmed_cases_daily.csv」を、フォルダ「data」の下に保存。Pythonのファイル名を新規作成しましょう。
日付を横軸にしてグラフで使いたいので、読み込む際に、日付の型を指定します。
0列目(日付)をインデックスに、日付をdatetime型に変換して読み込ませます。
# ファイル読み込みのためにpandasを宣言
import pandas as pd
# 0列目(日付)をインデックスに、日付を datetime型 に変換して読み込み
df = pd.read_csv('./data/newly_confirmed_cases_daily.csv', index_col=0, parse_dates=True)
df.tail(3)全部表示させるとすごい量なので、末尾3行を表示させて、うまくインポートできたか見ます。

Pandasのデータ型
pandasのデータが使用に都合のいい型になっているか、確認します。
Pandasの代表的な型は下記の表の通り。

df.dtypes # dfに入っているデータの型を確認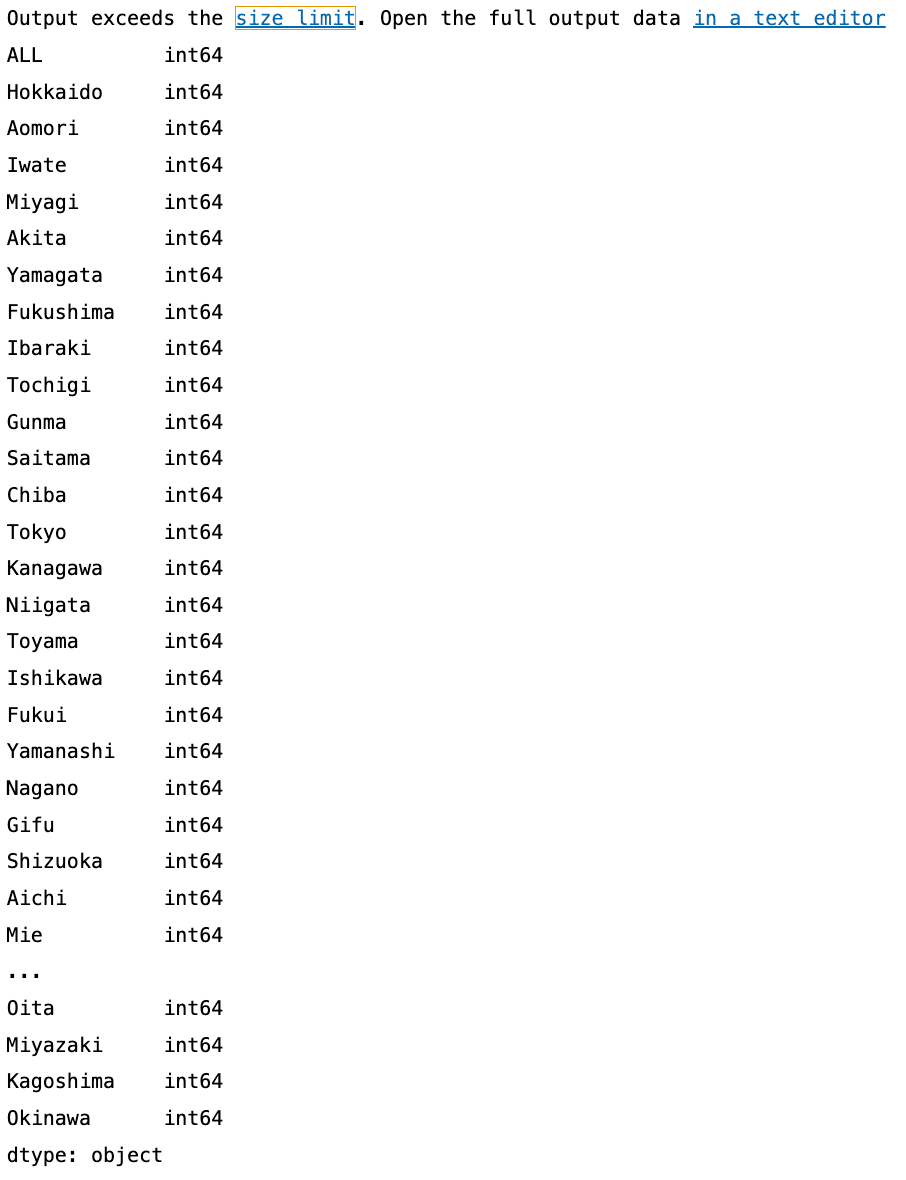
各都道府県の新規養成者数がint64型で入っていることがわかりました。グラフを描きたいので、整数型で入っていることがわかり、このまま使えそうです!厚生労働省さんありがとう!!
欠損値NaNをやっつけろ!
欠損値があってはいけないですよね。
とりあえず各列に欠損値があるかどうかを知りたいので、
1)isnull関数とany関数の組み合わせ→欠損値のある列にTrueが返される
2)notnull関数とall関数の組み合わせ→欠損値のある列にFalseが返される
の、パターンから1)を使ってみます。
df.isnull().any()
欠損値はなさそう。なんて使いやすいデータなんだ。ありがとう厚生労働省さん(2度目)
datetimeで期間集計しておこう
この後グラフにしたい。でも日にちごとで増減されると流石に動きが見にくいので、datetimeを使って、週、月、四半期、年の集計データを作っておくことにします。
import datetime # 標準ライブラリ
df_W = df.resample('W').sum() # 週ごとに合計
df_W.head(5)
df_M = df.resample('M').sum() # 月別で集計
df_M.head(2)
df_Q = df.resample('Q').sum() # 四半期ごとの集計
df_Q.head(3)
df_Y = df.resample('Y').sum() # 年ごとに集計
df_Y
まとめ
これを使ってそれぞれのグラフを描いていきたいと思います。
欠損値がなく、データ型の変換もいらないのでかなり使いやすいデータが元から提供されいて勉強用にはとても助かりました。
追記
(欠損値の扱い)
厚生労働省さんの提供データが素敵すぎて、
データ前処理で欠損値を取り扱わなくて良かったのですが、欠損値が出た場合はどうしましょうか。
今回は、時系列での増減を見たい、かつ、ある程度の期間でまとめてみようとしているので、欠損行は丸ごと削除しようと思ってました。
df = df.dropna() # 欠損値が一つでも含まれる行が削除
df.isnull().sum() # 行・列ごとに欠損値NaNの個数をカウント
欠損値の行列削除に合わせて、
実行結果後に欠損値はないことも確認できました。
ここまでのコードまとめ
# ファイル読み込みのためにpandasを宣言
import pandas as pd
# 0列目(日付)をindexにして読み込み、日付はdatetime型に変換指定
df = pd.read_csv('./data/newly_confirmed_cases_daily.csv', index_col=0, parse_dates=True)
# dfに入っているデータの型を確認
df.dtypes
# 欠損値がないか確認
df.isnull().any()
# 期間ごとの合計を作る
import datetime
df_W = df.resample('W').sum() # 週別に合計
df_M = df.resample('M').sum() # 月別で集計
df_Q = df.resample('Q').sum() # 四半期ごとの集計
df_Y = df.resample('Y').sum() # 年ごとに集計欠損がないから期間合計でよかったけど、欠損値があったら、期間ごとに平均値の方が良かったなと
これを作りながら、気がつきました。OMG
よろしければサポートお願いいたします。いただいたサポートは勉強のための書籍購入費に使う予定です。