
ヘボkagglerのTitanic再挑戦【再調整編】 #kaggle #機械学習

お世話になっております。
前回までの挑戦はこちらで
いろいろやってみたが再構成。
ダイエットしたkernelがこちら。
ダイエット済み
Ver9まで
とりあえずOne-hot
Ver10から
考える。
df.isnull().sum()PassengerId 0
Survived 418
Pclass 0
Name 0
Sex 0
Age 263
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 1014
Embarked 2このデータを見た時に、今ならAgeの数値を埋めに行くと思う。
そこで、埋め方はAgeを機械学習で予測したものを入れて埋めて、全体を再度機械学習する方法がひとつ。
その他に計算で埋める方法。
まずこれをやってみる。
train['Age'] = np.round(train['Age'].fillna(train['Age'].mean()))上記コードを廃止。
df.corr()
最初はFareだろうな。0.178。
Fareの前処理
これには欠損値が1つ。
df[df['Fare'].isnull()]
1044番さん。60代男性、乗船場所がSかな。
Pclassが階級。船にとってえぇ客かどうかくらいの認識でもいいか。
左から順に見てPclassが気になる。※当たり前
Pclass
df.Pclass.unique()
array([3, 1, 2])df['Pclass'].value_counts()
3 709
1 323
2 277
Name: Pclass, dtype: int64grouped = df.groupby('Pclass')
grouped.Fare.mean()
Pclass
1 87.508992
2 21.179196
3 13.302889
Name: Fare, dtype: float64Pclass毎のFareの平均を出してみた。
高い運賃で乗っ取るんやから、1がお金持ち。
で、さっきの1044番さんはPclassが3だから、13.3かもしれない。
いやいや、まだ気になることがある。
Ageが60代ならどうなんだ?
grouped60 = grouped[grouped['Age'] >= 60]['Fare']
TypeError: '>=' not supported between instances of 'SeriesGroupBy' and 'int'あ、エラー出た。
age60 = df[(df['Age']>60) & (df['Age']<70)]60代でまとめた。
age60.groupby('Pclass').mean()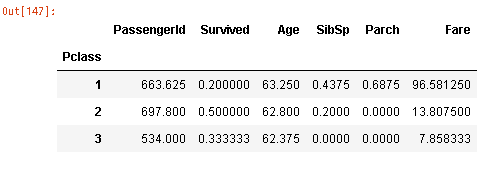
7.8か。7.8かな。
いや、乗船場所がSだったか。乗船場所によって、移動距離が違うだろうから、運賃も違うんだろうか。
Embarked=S
age60.groupby(['Pclass','Embarked']).mean()
7.9か。さほど変わらない?
いや、Pclassが3でQとSの差は表現するべきかもしれない。小数点第一位までは学習に含んでみるかぁ。今までは単純に丸めてしまっていた。
検討しよう。
Parch
これは家族の数だっけな。
df.Parch.unique()
array([0, 1, 2, 5, 3, 4, 6, 9])df['Parch'].value_counts()
0 1002
1 170
2 113
3 8
5 6
4 6
9 2
6 2
Name: Parch, dtype: int64SibSp
家族、親兄弟の数か、、、
うーむ。
1044番さんのFare
age60.groupby(['Pclass','Embarked','SibSp','Parch']).mean()7.9。変わらん。ふー。気が済んだ。
df.loc[df['PassengerId'] == 1044, 'Fare'] = 7.9
AgeとFare
Ageの欠損値をFareから予測できるのかな???
[df.Fare]=np.round([df.Fare],1)
df.Fare.unique()
plt.hist(df['Fare'])
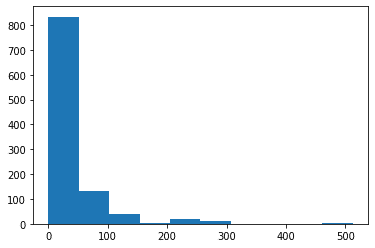
500ってなんだ?高い!

一組は夫婦だな。その他の二人はなんだ??
Ticketは一緒??Ticket?共同購入?
団体パスみたいなものか???
生存率に関係するか見てみた方がいいかもしれない。
Ticket
df.Ticket.unique()記号と数字。スペース区切りと、、、
ticket_split = df['Ticket'].str.rsplit(' ', expand=True)うまく分割できない。
ハマった。
根性論
test = df['Ticket'].str.extract('(.*)\s(.*)')
df['Ticket_head']=test[0]なんとか分割できたー。
今度はcommaがreplaceできない!
Ticket_head = df['Ticket_head'].apply(lambda x: x.replace(".", "") if type(x) is str else float(x))似たようなの落ちてた。いいね押しときました。
Ticket_headの新たな問題
array(['A/5', 'PC', 'STON/O2', nan, 'PP', 'CA', 'SC/Paris', 'A/4', 'SP',
'SOC', 'SO/C', 'W/C', 'WEP', 'STON/O 2', 'C', 'SOTON/OQ',
'SC/PARIS', 'SOP', 'A5', 'FCC', 'SW/PP', 'SCO/W', 'P/PP', 'SC',
'SC/AH', 'SC/AH Basle', 'WE/P', 'FC', 'SOTON/O2', 'SO/PP',
'CA/SOTON', 'STON/OQ', 'SC/A4', 'AQ/3'], dtype=object)STONとSOTONは同じか??
SOTONまたは「STONはサウサンプトンとか英語サイトに書いてあるのを見たけどどうなんだろう。
CA/SOTONってなんだ??'SOC', 'SO/C'って差があるのか?
from scipy.stats import rankdata
from scipy.stats import rankdata
df['Ticket_head']=rankdata(df['Ticket_head'], method='max')
df['Ticket_num']=rankdata(df['Ticket_num'], method='max')
df['Ticket_head']=np.log(df['Ticket_head'])
df['Ticket_num']=np.log(df['Ticket_num'])機械学習前に、上記のようにいたずらに変換を重ねる。
Ticketの数字
桁が合わない、、、
df['Ticket_num'].value_counts()数えてみた。
これで数が多いと生存率に関係するか見てみるには・・・と。
重複する数字を、うまく特徴量にするべきかもなー。
Ageの穴埋め
ここまでやってみて、穴が空いているAgeを再度見てみる。
このAgeの穴埋めは、生存率に関係するかしないかはっきりしないと思っている段階でも、平均値などで埋められる数値で、これを計算で埋められるならそれに越したことはないという観点。
また、上は80歳、下は0歳だが、0歳が地力で逃げるのは不可能と考えると、年齢は生存率に関係あるはずだ。
Fareの時と同じパターンで穴埋めしようとして、ランダムフォレストが思い浮かぶ私。
df.groupby(['Sex','Pclass','Embarked','SibSp','Parch']).mean()この結果を見ていると、どの条件で年齢が決まるのかランダムフォレストで出せばいいんじゃないだろうか?
※組み合わせを割り出すのに強そうでしょ。あの木。
ランダムフォレスト
Ageを予測するも、正解率が60%も出ない上に、全体の正解率が55%と低下!
この辺で、根本的な部分で機械学習を間違っているのではないか?と迷うが、突き進むことにする。
groupbyでの穴埋め
gc.groupby(['mrms','Pclass','Sex','SibSp','Parch','Embarked','Survived']).mean()各グループ分けした平均で、Ageの欠損を埋めてやる。
column = 'Cabin'
gc[column] = gc[column].fillna(0)
gc[column] = gc[column].str.extract('([A-Za-z]+)', expand = False)
column = 'mrms'
gc[column] = gc['Name'].str.extract('([A-Za-z]+)\.', expand = False)
gc[column] = gc[column].replace(['Col', 'Mlle', 'Major','Countess','Lady', 'Sir', 'Dona', 'Capt', 'Jonkheer', 'Don', 'Mme', 'Ms', 'Dr', 'Rev'], 'Other')
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
gc['Ticket_head']=le.fit_transform(gc['Ticket_head'])
gc['Ticket_num']=le.fit_transform(gc['Ticket_num'])import category_encoders as ce
list_ce = ['Cabin','Embarked','Sex','mrms']
ce_ohe = ce.OneHotEncoder(cols=list_ce,handle_unknown='impute')
gc = ce_ohe.fit_transform(gc)文字列のままだと、一括で埋められないので変換。
gc = train.drop(['Name','Ticket','Survived'], axis=1)gccollist=list(gc.columns)
gccollist.remove('Age')Ageだけを抜いた文字列の数値変換後のリストを作った。
gc['Age']=gc['Age'].fillna(gc.groupby(gccollist)['Age'].transform('mean'))gc.Age.isnull().sum()
80あと80個、もともと263個あったからもう少し。
Age???
待てよ、なんか変だ。生存率に年齢が関係あるという仮定があって、ここまで分析して、生存のフラグから年齢が推定できていない気がするぞ???
#機械学習 #kaggle
— ムジンさん:IT単純作業@自動化支援の社長 (@MKP3share) April 24, 2020
今はどんなに辛くても、自分のやり方で正解率を高める必要がある。自分の研究対象(競輪予想等)にkaggleのようなディスカッションの場はない。Titanic完全にハマっている状態だが、今までのパターンで、ハマリ状態は正解に近い。この先に一歩進むのが大変なのは知っているけども。
#機械学習 #kaggle
— ムジンさん:IT単純作業@自動化支援の社長 (@MKP3share) April 24, 2020
当時のシンプルなやり方の方が正解率が高い。これは今の競輪予想モデルにも余計なことをしている可能性が高い。前処理の差だと思うが、ここを今のテクニックと上手く噛み合わせる必要があると感じている。 https://t.co/zMAqI9b5bf
もう一度やり直してみよう。
いいなと思ったら応援しよう!
