
Googleスプレッドシート 困った表を集計する為の 加工数式(結合セルに負けない)

週1とは言え、毎回Googleスプレッドシートだけで よくそんだけ書けますね。なんてことを言われますが、バズるかはともかく 書きたいことはいくらでもあるんですよね。
本当は もっと1回あたりのテーマを絞った 短めの noteをいっぱい書いた方がいんでしょうが、どうしても 書き出すとアレもコレもと話が広がって長くなっちゃいます。(逆に書き出すまでが腰が重いタイプ)
前回までの フィルタ表示シリーズは、まさにそんな感じで 1回あたりが長い上に 4週もフィルタ表示ネタで引っ張っちゃいましたw
しかも、SUBTOTALの挙動や QUERY関数なんかも盛り込む、マシマシnoteで 普通の人には重すぎる内容w
ジロリアンならぬ スプシアンだけが喜ぶ noteってのも良くないなと。
かつての格ゲーみたいに、新参が入りづらくなったコンテンツは衰退していくものです。
なるべく裾野を広げるネタも書いていきたいなと思います。
というわけで、今回は「あるある」ネタです。
シリーズ前回の記事
でも、やっぱ 瞬間風速だけ高い その時だけしか注目浴びない noteよりも、後々 困った人が検索でたどり着くような 残る noteを書いていきたいんですよねー。(鮮度も大事だけど)
そうすると、やっぱ 麺固め、濃いめ、脂多め みたいな noteになっちゃうw
「あるある」な困った表と向き合う
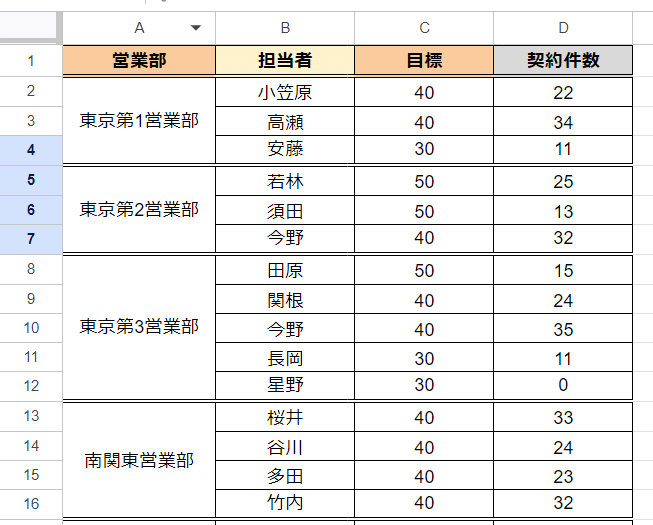
皆さんの会社にもこんな表がないでしょうか?
「あるある」と思った方には、今回の noteが役立つかもしれません。
一部の式は Excelでも使えるので、Excelユーザーの方にも役立つかも。
見た目を優先すると、データとして扱いづらくなる
見た目重視の表と データベースとして使える集計しやすい表は、なかなか相容れないものです。
他の人が作った表をベースに 集計しようとして、結構困ることがあります。
たとえば、上のような 部署、社員ごとの実績管理表があった場合、「見やすさ」を優先して 部署がセル結合してあったり・・・。
気持ちはわかりますが、これやられちゃうと集計や絞り込みをする時に困るんですよね。
そもそも縦に結合したセルがあると、先週までシリーズ連載していた フィルタ(フィルタ表示)でのソートが使えません。

もちろん、気軽に関数による抽出、検索も出来ません。
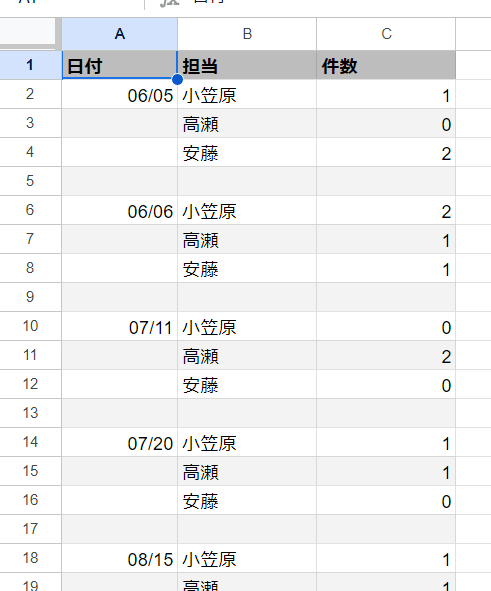
結合セルがなくても、見やすさを優先した結果、各データの 先頭行にだけ記述するといった表も「あるある」ですね。
これも 同じく 日付で絞り込もうとすると 、小笠原さん以外の人は システからは 日付なしと判断されてしまい、うまく集計ができません。
とはいえ、
データベースファーストな表の方が良いんです!
と、他の社員の意見を無視して以下のような表に変えると・・・

みっちりと 同じ文字が繰り返される表になってしまい、閲覧者や普段利用する 人からは「見づらい」「使いにくい」といった声が上がってしまいます。
で、いつのまにか最初の結合セル表に戻ってるってパターンも多いのです。
デザイン系の記事でよく見かける「余白」 の重要性
この「余白」が人間 にとっては重要なんだけど、データベース的には困りもんってことですね。
両方を考慮した、人間からもシステムからも 扱いやすい表はどうすれば良いか?
落としどころ(一番簡単な解決策) 背景色と同じ色の文字を使う

一番簡単な解決策は、結合セルは諦めてもらうとして、先頭行の文字だけ見えるようにして、以降の繰り返し文字を白(セルの背景色と同じ)にして 見えなくする方法です。
これなら 余白多めで見やすさは確保しつつ、システム的にもデータとして扱え、フィルタでの絞り込みや FILTER関数や SUMIF関数、QUERY関数 が使えます。
注意点としては、文字が見えないので 誤操作で消されてしまった時に気づかないという点。
それを回避する為に、アラートを出す保護をかけたり、条件付き書式で 消されたことがわかるようにしておくと良いです。

空白があった場合は、セルに色を付けて目立たせる。条件付き書式でこれを設定しておくだけでも、誤操作発見に繋がります。
でも、この隠し文字を入れる方法が使えるのは、あくまでも 自分が管理できる表だけなんですよね。。
怖い上司が作った表や、自分が出しゃばって勝手に書き換えることが難しい他部署の 表 にはこの方法は使えません。
そもそも、自分が触れない保護されている表ってパターンもあります。
では、結合セル多用、もしくは 塊ごとの先頭にしかデータが入っていない 困った表から直接 集計する方法はないのか?
お題形式で考えていきましょう。
作業列(作業用シート)を使って集計
元の表をさわらずに データとして使いやすい形にしたい場合、まず考えられるのが作業列や作業用シートに一度 出力する方法です。

簡単ですが、まずは これを お題として考えてみましょう。
Q1. 上の画像のように縦結合のセルがある A列を F列のようにしたい。下にフィルコピーするとして、最初のF2セルには どんな式を入れればよいか?
いきなり 1つの式で処理は ハードルが高いので、下にフィルコピーする前提で F2に入れる式を考えてみましょう。
どうでしょうか? 基本ですが、普段Excelやスプレッドシートを使ってる人でも これが出来ない人が半数くらいいます。
まずは自力で考えてみましょう。
↓↓↓
回答は以下
↓↓↓
A1. 縦結合の列のデータをバラす 式

F2に入れる式は
=IF(A2<>"", A2 , F1 )
または
=IF(A2="", F1 , A2 )
こちらになります。 式の見栄えとしては 下の方がよいですが、動作を理解するには 上の式が分かりやすいかと思います。
まず、 結合セルの中身のデータがどうなっているか?
結合セルは 結合されているセル範囲の 左上 だけにデータが入っており、それ以外は空白 となっています。(結合を解除すると 実際そうなっている)
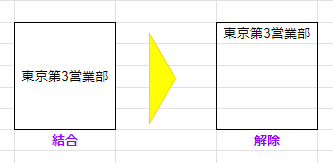
だから、A2:A4 が結合されて 「東京第1営業部」と入っていた場合、
A2 東京第1営業部
A3 空白
A4 空白
このようになっています。
統合セルの文字の表示位置が上下真ん中になっていても、値が入ってるセルが 左上であることに変わりはありませんw
というわけで F2 に入れる式は、
A2(A列)が空白でなければ、A2をそのまま返す
A2(A列)が空白なら 式を入れている F2の1つ上 F1を返す
このように記述すればよいわけです。
空白かどうか?で 結果を分岐させるので IF関数の出番ですね。
それを式にしたものが ↓ です。
=IF(A2<>"", A2 , F1 )
当然ですが、開始の A2が空白でないことが前提となっています。あとは、これを下にフィルコピーで OK。
簡単ですね。
他のシート(作業用シート)に出力する時も、考え方は一緒です。
作業列を組み合わせて集計する
この作業列 F2:F30 に出力した データを組み合わせることで、関数での集計が可能となります。

H2に部署名の プルダウンをセットして、その部署の 合計契約件数(D列)を集計する場合は I2に
=SUMIF(F2:F30,H2,D2:D30)
このように SUMIFを入れればOK。
F2:F30 で H2 と一致した行の D2:D30 の値を SUMする という式です。
SUMIFやSUMIFSは スピル以前のExcelでも使えるんで、根強い人気の便利な関数ですね。
さらに、Googleスプレッドシートではお馴染みの QUERY関数を使えば、一気に部署ごとの 目標と実績の集計表を作成することも可能です。

=QUERY(C1:F30,"select F,sum(C),sum(D) where C is not null group by F")
元の表の並びに作業列を作ったので、関係ない E列を含めて C1:F30 を範囲として Select 句で 必要な列だけ取り出す。
Query関数ならではの処理ですね。
もちろん 範囲側を必要なものだけに加工しておく書き方もあります。
=QUERY({F1:F30,C1:D30},"select Col1,sum(Col2),sum(Col3) where Col1 is not null group by Col1")
少し脱線しますが、Query関数のオプション句を長々と記述すれば、
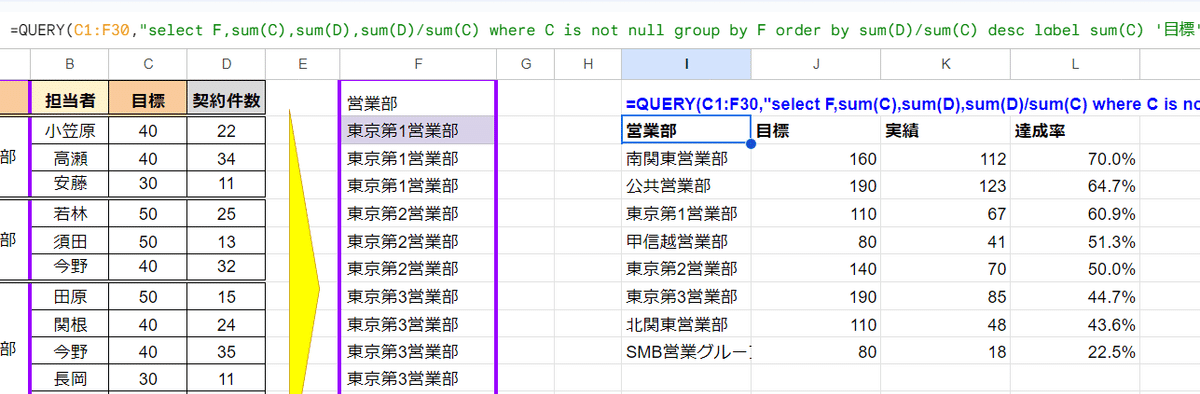
sum(D)/sum(C) で 計算した 達成率をformat句で %表記 に、その達成率 が高い順で order by で並び替え、さらに label でラベルを修正。
こんなことも出来ます。
=QUERY(C1:F30, "select F, sum(C), sum(D), sum(D)/sum(C) where C is not null group by F order by sum(D)/sum(C) desc label sum(C) '目標', sum(D) '実績', sum(D)/sum(C) '達成率' format sum(D)/sum(C) '0.0%' ")
=QUERY(C1:F30,
"select F, sum(C), sum(D), sum(D)/sum(C)
where C is not null
group by F
order by sum(D)/sum(C) desc
label sum(C) '目標', sum(D) '実績', sum(D)/sum(C) '達成率'
format sum(D)/sum(C) '0.0%' "
)そのうち QUERY関数についても書きたいと思うんですが、結構他の人がやりつくしてるんで、いまいちモチベが上がらないw
↓ 公式は丁寧じゃないんで見てもよくわからないと思いますが、一応
作業列 と 元の表のデータを組み合わせて集計することが出来ました。
作業列の式を 1つの式で記述する
最終目標は 作業列なしで 困った表を集計する! なので、そのためには作業列の式を 一つの式でスピらせる必要があります。
どう記述すればよいでしょうか?
Q2. 縦結合のセルがある A列を F列のようにしたい。F2セルにだけ式を入れて 実現することは可能か?
先ほどの フィルコピーした式
=IF(A2<>"", A2 , F1 )
↑ こちらは 式を入れる F列の一つ上を参照する式なんで、そのまま Arrayformulaに出来ません。
循環参照エラーがでちゃいます。

じゃあ、どのような方法があるか?
少しハードルがあがりますが、自信のある人は考えてみましょう!
要件として 範囲は A1:A30として、

このように 下のデータがない部分の判定に関しては、B列が 空白かどうかを条件として使えることにしましょう。
↓↓↓
回答は以下
ちなみに LAMBDAヘルパー関数を使う方法と、
LAMBDAや新関数を使わず Arrayformula で処理する方法があります。
↓↓↓
A2. 1つの式で 縦結合の列のデータをバラす
まずは 比較的簡単な LAMBDAヘルパー関数を使う方法から解説していきます。
処理の中でポイントとなるのは、
A2(A列)が空白なら 式を入れている F2の1つ上 F1を返す
この処理です。
一つ上の値(つまり 一つ前の計算処理の結果)を利用したい。まさにこんな時にうってつけの関数があります。
LAMBDAヘルパー関数 の中でも 最強クラスの REDUCE関数 と SCAN関数 です。
今回の場合は 途中経過を出力する SCANを使いましょう。
ちなみに、ありがたいことに
SCAN関数 スプレッドシート
で検索すると、公式の次に mirのnoteが 表示されます!

で、回答はこちら ↓
=SCAN(,A2:A30,
LAMBDA(pv,cv,IFS(cv<>"",cv,offset(cv,,1)<>"",pv,true,)))

A2が空白じゃないことを前提としているので、初期値は空でOKです。A2:A30を順に処理していくので 冒頭は
=SCAN(,A2:A30,
となります。で、
一つ前の 処理の 結果(累積値)を pv
A2:A30 を一つずつ取り出した もの(現在の値)を cv
と置いています。
=SCAN(,A2:A30,LAMBDA(pv,cv
あとは IFS関数の処理ですね。
IFS(cv<>"",cv,offset(cv,,1)<>"",pv,true,)
IFSは 左(前)から順に判定して、条件が合致した時の結果を返します。
IFS(条件1, 値1, [条件2, 値2, …])
今回の場合は
IFS(
cv<>"",cv,
※条件式1 cv が空でないなら cv を返す 。
これが 次の処理の pv になる
↓ 通過した場合は cvは空であるということ
offset(cv,,1)<>"",pv,
※条件式2 cvの 一つ右、つまり B列が 空でなければ
pv(一つ上の結果)を返す。これが次の式の pv になる
↓ 通過した場合は B列が空であるということ
true,
※ 条件式1,2にヒットしないその他は全て 空白を返す
カンマで終わってますが、これは 空白を返すという意味
)
このような処理がされています。
IFS関数で 「それ以外の時」の処理は 一番後ろに
true, (それ以外の時の処理)
と記述します。
cv は 意外にも セル参照を 一つずつわたしてるんですね。
だから offsetで 今処理している A列のセルの隣、同じ行のB列セルを取得することが出来ます。
別のケースでも同じように使えます。

SCAN関数が、不慣れな人には 理解が難しいかもしれませんが、LAMBDAヘルパー関数の登場で、だいぶすっきり記述できるようになりました。
じゃあ、LAMBDA登場以前はどのような式で処理していたか?
別解として、それも見ておきましょう。
A2(別解). 1つの式で 縦結合の列のデータをバラす

=Arrayformula(IF(B2:B30="",,
XLOOKUP(ROW(A2:A30),IF(A2:A30="",,ROW(A2:A30)),A2:A30,,-1)))
こちらになります。
いやいや、XLOOKUPって・・新関数使ってるじゃん!
ってツッコまれそうなんで、一応 LOOKUPでも出来るって回答も書いておきます。
=Arrayformula(IF(B2:B30="",,
LOOKUP(ROW(A2:A30),IF(A2:A30="",,ROW(A2:A30)),A2:A30)))
ポイントは
IF(A2:A30="",,ROW(A2:A30))
この部分です。A列が空白の場合は 空白、空白でない場合は 行番号を返す配列を生成しています。

この配列を対象に XLOOKUPの 第4引数 -1 による 近似値一致 小、もしくはLOOKUP の 近似値一致で 行番号 ROW(A2:A30) を1つずつ検索していきます。
そうすると、例えば ROW(A3) つまり 行番号 3 の時は、検索配列に 3がないので、3以下のもっとも3に近い値 2がヒットします。
結果列に A2:A30を指定しているので A2の値、 東京第1営業部 が返ることになります。

近似値一致 を応用したテクニックです。
この困った表がとんでもない行数の場合は、別解のArrayformulaを使った処理の方が若干早いかもしれませんが、普通に利用するなら 今どきは SCAN式の方がよいでしょう。式も短いし。
あと、例外的に「条件付き書式」で利用したい場合は、別解の式の方が人によっては簡単に感じるかもしれません。
これは後ほど触れます。
困った表から 直接 データ集計する
SCAN関数を使うことで、一つの式で 結合セル入りの列を データとして扱える状態に出来ました。
じゃあ、この式をそのまま 組み込めば、作業列なしで 直接 困った表から データ集計できそうですね!
やってみましょう。
困った表から 直接SUMIFする

作業列なしで 困った表から SUMIFで 集計できているのがわかりますね。
さらに、条件付き書式で 選択している 部門も色付けできています。
まずは F2に入っている 集計の式
=LET(range,A2:D30,key,F2,SUMIF(SCAN(,index(range,,1),LAMBDA(pv,cv,IFS(cv<>"",cv,offset(cv,0,1)<>"",pv,true,))),key,index(range,,4)))
ちょっと長いんでわかりづらいですね。コード記述でインデントつけましょう。
=LET(
range,A2:D30,
key,F2,
SUMIF(
SCAN(
,index(range,,1),
LAMBDA(
pv,cv,
IFS(
cv<>"",cv,
offset(cv,0,1)<>"",pv,
true,
)
)
),
key,
index(range,,4)
)
)セルの指定記述 を LETを使って前半にまとめて変数化しています。
そこから 使う列を indexで取り出して、SUMIFと先ほどの SCAN式を組み合わせればOK。
困った表を 条件付き書式で 可変色付けする
F2で 選択した部署のデータに色付けする 条件付き書式、こちらの設定方法も確認しましょう。
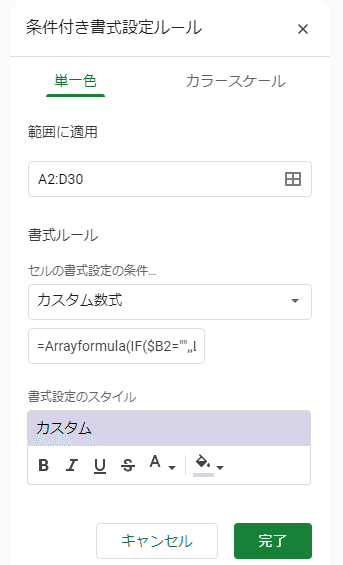
カスタム数式はなかなか複雑です。
=Arrayformula(IF($B2="",,LOOKUP(ROW(A2),IF($A$2:$A$30="",,ROW($A$2:$A$30)),$A$2:$A$30)))=$F$2
こんな感じ。
色付けするセルから見た式をつくり、範囲内で相対的に動くことを考慮して式を作る必要があるので、一部は絶対参照にする必要がありますし、一部は 単体セルとして指定とする必要があります。
ここで、一気に配列を返してしまう 先ほどの SCAN式をそのまま使ってもうまくいきません。
ちょっとしたアレンジが必要で、SCANの配列から 色付けするセルと 相対的な位置の 値を indexで取得した上で、$F$2と 一致するかを判定する式にしています。
カスタム数式 パターン2
=index(SCAN(,$A$2:$A$30, LAMBDA(pv,cv,IFS(cv<>"",cv,offset(cv,0,1)<>"",pv,true,))),ROW(A2)-1,)=$F$2
条件付き書式のカスタム数式は エラーが見つけづらいので、一度 セルで動かして動作確認してから コピペすることをお勧めします。
また、条件付き書式で カスタム数式を使う時のポイントは、カレンダーの回で触れています。
困った表から 直接QUERY関数で集計表を生成する

=LET(
range,A1:D30,
dept,
SCAN(
,index(range,,1),
LAMBDA(
pv,cv,
IFS(
cv<>"",cv,
offset(cv,0,1)<>"",pv,
true,
)
)
),
QUERY(
{dept,CHOOSECOLS(range,3,4)},
"select Col1,sum(Col2),sum(Col3)
where Col1 is not null
group by Col1"
)
)これも 組み合わせるだけですね。
SCAN関数で生成した A列をクレンジングした配列を dept と置いて、CHOOSECOLSで取り出した C列、D列と { , } で横連結して配列化、Query関数で グループ集計しています。
Query関数でグループ集計すると、部署名の並びが変わってしまうのがネックです。
これを 並びを変えを発生させずに処理するには、行番号を組み合わせた一工夫が必要なんですが、今回のテーマからはズレるし、結構長くなるのでQuery関数 を特集する回にでも紹介したいと思います。
困った表と 上手に付き合う
今回は「あるある」な セル結合されていたり、記述が先頭行のみ といった、見やすいけど少し困った表からデータ集計する方法を紹介しました。
冒頭に書いた通り、人間側からの 見やすい・作業しやすい表と、コンピュータ側からデータとして扱うのに適した表は別モノです。
集計の為に 人間側にストレスをかけては意味がありませんし、だからといって集計の際に 手作業が発生しては元も子もないです。
最新関数を理解して、上手に困った表と付き合っていきましょう。
次回は、もう一つの困った表 手作業で作られたクロス表を扱う方法。いわゆるアンピボットに挑戦してみましょう。
これもネット上で結構紹介されてるネタなんで、少し複雑なケースにも触れたいと思います。
いいなと思ったら応援しよう!
